In scenarios where direct pipeline instrumentation encounters challenges, our updated capabilities offer a flexible approach. While real-time tracking traditionally assumes instant span creation, this may not align with cases involving pipeline execution details sourced from databases or APIs.
To address this, we have optimized our API or SDK to efficiently load pipeline monitoring metadata independently of the platform's ongoing activity.
Prerequisites
Supported by the acceldata_sdk version, commencing from acceldata-sdk.2.12.0.
No Real-Time Alerts: Real-time alerts are triggered only for current activities. Historical loads will not trigger the following real-time alerts.
Pipeline Alerts
- Pipeline Duration: Set alerts based on user-defined thresholds.
- Pipeline Start Time: Configure alerts based on user-defined thresholds.
- Pipeline End Time: Establish alerts based on user-defined thresholds.
Job Alerts
- Job Duration: Set alerts based on user-defined thresholds.
- Job Start Time: Configure alerts based on user-defined thresholds.
- Job End Time: Establish alerts based on user-defined thresholds.
Span Alerts
- Span Duration: Set alerts based on user-defined thresholds.
- Span Start Time: Configure alerts based on user-defined thresholds.
- Span End Time: Establish alerts based on user-defined thresholds.
Event Based Alerts: Evaluated as soon as the span events are received.
Post-Processing Alerts: Avoid configuring post-processing alerts for historical loads; allocate them for upcoming data flows. The following are the post-processing alerts:
Pipeline Alerts
- Pipeline Duration: Set alerts based on previous executions.
- Pipeline Start Time: Configure alerts based on previous executions.
- Pipeline End Time: Establish alerts based on previous executions.
Job Alerts
- Job Duration: Set alerts based on previous executions.
- Job Start Time: Configure alerts based on previous executions.
- Job End Time : Establish alerts based on previous executions.
Span Alerts
- Span Duration: Set alerts based on previous executions.
- Span Start Time: Configure alerts based on previous executions.
- Span End Time: Establish alerts based on previous executions.
Event Based Alerts: Evaluated as soon as the span events are received, making it applicable for historical processing.
Creating a Historical Pipeline
- Creating a pipeline with explicit times: While creating a pipeline for historical load, the
createdAtfield specifying the pipeline creation time needs to be passed.
xxxxxxxxxx#Add necessary imports here explicit_pipeline_createdAt = datetime(2023, 11, 14, 12, 30, 0) meta = PipelineMetadata(owner='sdk/pipeline-user', team='ADOC', codeLocation='...')pipeline_name_ = pipeline_namepipeline = CreatePipeline( uid=pipeline_uid, name=pipeline_name_, description=f'The pipeline {pipeline_name_} has been created from acceldata-sdk using External integration', meta=meta, context={'pipeline_uid': pipeline_uid, 'pipeline_name': pipeline_name_}, createdAt=explicit_pipeline_createdAt )pipeline_res = torch_client.create_pipeline(pipeline=pipeline)- Updating a pipeline with explicit times: When updating any details of the pipeline for historical load, the
updatedAtfield needs to be passed.
xxxxxxxxxx#Add necessary imports hereexplicit_pipeline_updatedAt = datetime(2023, 11, 14, 12, 50, 0) meta = PipelineMetadata(owner='sdk/pipeline-user', team='ADOC', codeLocation='...')pipeline_name_ = pipeline_namepipeline = CreatePipeline( uid=pipeline_uid, name=pipeline_name_, description=f'The pipeline {pipeline_name_} has been updated from acceldata-sdk using External integration', meta=meta, context={'pipeline_uid': pipeline_uid, 'pipeline_name': pipeline_name_}, updatedAt=explicit_pipeline_updatedAt )pipeline_res = torch_client.create_pipeline(pipeline=pipeline)- Creating Pipeline run with explicit times: The
startedAtparameter needs to be set with the historical pipeline run creation time.
xxxxxxxxxx#Add necessary imports here#Consuming pipeline_res object from step 1 aboveexplicit_pipeline_run_startedAt = datetime(2023, 11, 14, 13, 30, 0)pipeline_run = pipeline_res.create_pipeline_run(startedAt=explicit_pipeline_run_startedAt)- Creating spans to support sending span events with explicit times: In order to enable start span events to consume the historical time the flag
with_explicit_timeparameter needs to be set toTruewhile span creation. If this parameter is not set, spans will be created and the span start event will be sent with the current time.
xxxxxxxxxx#Consuming the pipeline_run object created in the step 3 abovespan_name_=f'{pipeline_uid}.root.span'parent_span_context = pipeline_run.create_span(uid=span_name_, with_explicit_time=True)- Sending span events with explicit times: The historical span event start/end/failed/abort times can be passed using the
created_atparameter.
xxxxxxxxxx#Sending span start event#consuming the parent_span_context created in the step 4 aboveroot_span_created_at = datetime(2023, 11, 14, 13, 30, 1)parent_span_context.start(created_at=root_span_created_at)- Creating jobs bound by span with explicit times: When jobs bound by span are created, ensure that the bounded span supports explicit times. To enable the span start event corresponding to the bounded span with the job, the
with_explicit_timeparameter needs to be set, else the span will be bound and start with the current time.
xxxxxxxxxx#Creating Job bounded by spanjob_uid="customers.data-generation"inputs=[]outputs=[Node(job_uid='customers.s3-upload')]job_span_uid=f'{job_uid} Span' job = CreateJob( uid="job_uid", name=f'{job_uid} Job', pipeline_run_id=pipeline_run.id, description=f'{job_uid} created using torch job decorator', inputs=inputs, outputs=outputs, bounded_by_span=True, span_uid=job_span_uid, with_explicit_time=True )created_job = pipeline_run.create_job(job)job_span_context = pipeline_run.get_span(job_span_uid)job_span_context.start(created_at= datetime(2023, 11, 14, 13, 40, 1))job_span_context.send_event(GenericEvent(context_data={'Size':100, 'total_file': 1, 'schema': 'name,address,dept_id'}, event_uid="customers.data.generation.metadata", created_at=datetime(2023, 11, 14, 13, 45, 1)))job_span_context.end(created_at=datetime(2023, 11, 14, 13, 48, 1))- Updating pipeline run with explicit times: To end the pipeline run with historical time, the
finishedAtparameter needs to be set, otherwise the span will end with the current time.
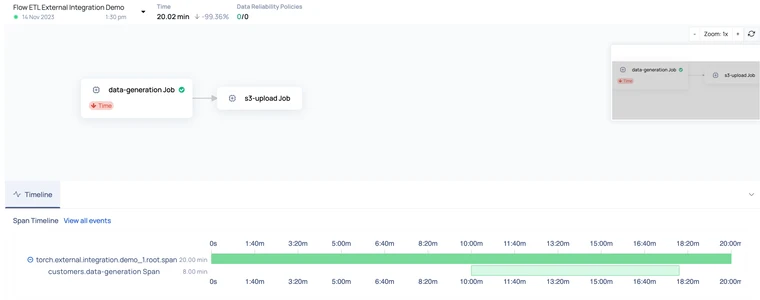
xxxxxxxxxx#Updating the pipeline_run object created in the step 3 #Ending the root span for the pipeline runroot_span_finishedAt = datetime(2023, 11, 14, 13, 50, 1)parent_span_context.end(created_at=root_span_finishedAt) explicit_pipeline_run_finishedAt = datetime(2023, 11, 14, 13, 50, 1)#Ending the pipeline runpipeline_run.update_pipeline_run( context_data={'status': 'success'}, result=PipelineRunResult.SUCCESS, status=PipelineRunStatus.COMPLETED, finishedAt=explicit_pipeline_run_finishedAt )Here is a snapshot of the pipeline reconstructed back in time using the above code: