Torch Databricks Integration
Integration Modes
Torch can be integrated with Databricks in two modes based on where the Spark jobs run:
- External Spark Cluster with Databricks Delta Lake as the data source
- Full Databricks integration (Data and Compute both on a Databricks cluster)
External Spark Cluster with Databricks Delta lake as the data source
In this mode, the installation process is the same as that of a normal Torch installation, and Databricks Delta Lake can be added as one of the data sources using the Torch Databricks connector. The Spark jobs run on an external Spark cluster running either on Kubernetes or Spark on a Hadoop Cluster. Here, Databricks is added as a datasource to access data from Databricks Delta tables for profiling and quality evaluation. To add Databricks as a datasource, Torch requires Databricks cluster JDBC details, along with UID and Personal Access Token to establish the connection, and to run queries.
The JDBC details for a cluster is found on the Advanced Options in Cluster Details page.
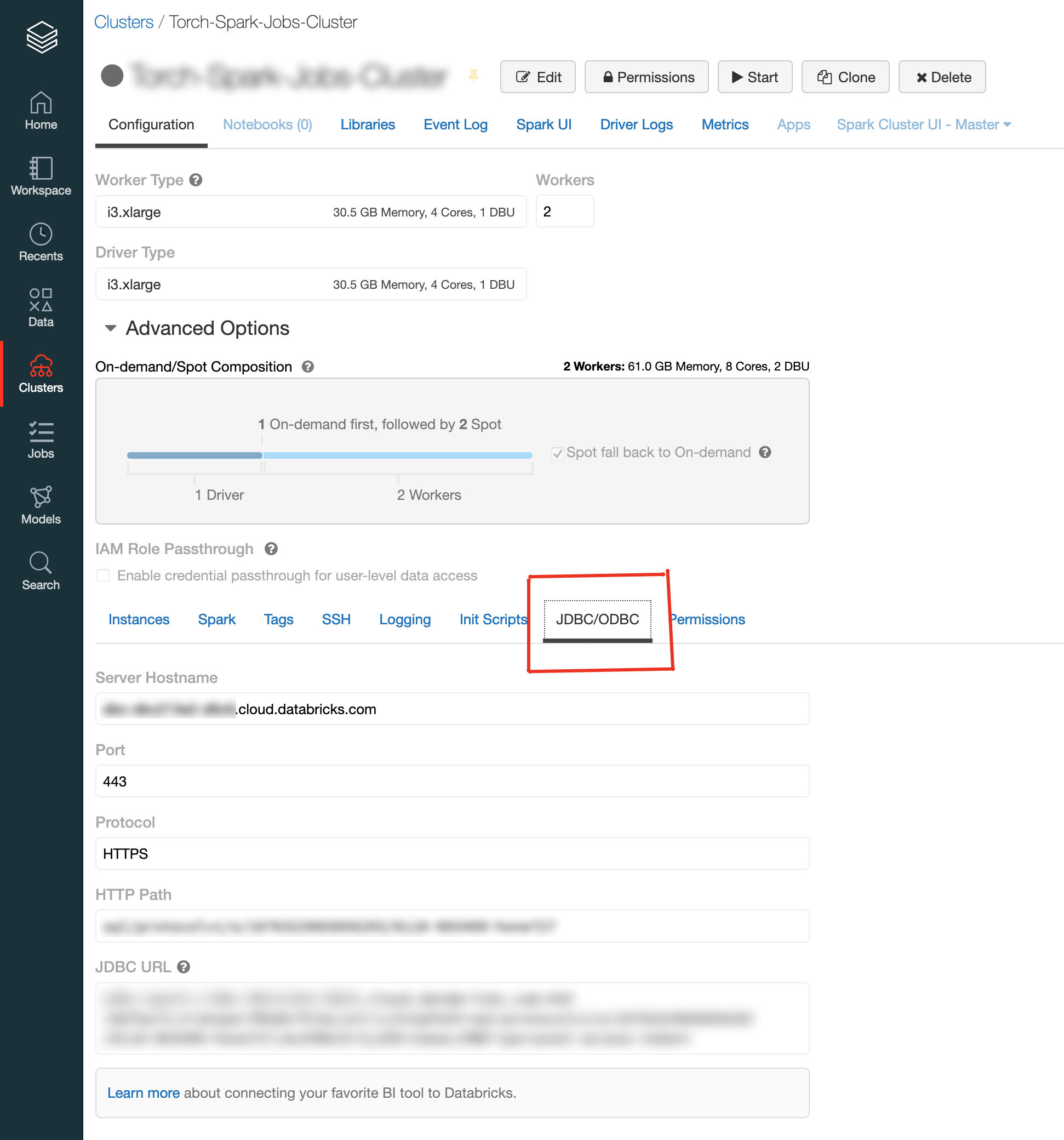
databricks jdbc details
Here, UID is "token," and PWD stands for Personal Access Token, which can be generated on Databricks' User Settings page.

token generation
Adding a Databricks Datasource
- Get the Databricks Cluster's JDBC URL as well as the Access Token. The UID is set to "token" by default. Below is an example JDBC URL:
jdbc:spark://dummy.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/16763 040399-dummy267;AuthMech=3 - Navigate to Datasources in Torch UI, then click Create Datasource and select Databricks. Provide the necessary connection properties, such as the JDBC URL, Username, and Password. URL will be the JDBC URL, for example:
jdbc:spark:/dummy.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/138694 040399-dummy267;AuthMech=3Username - "token"
Password - Personal Access Token
- If Databricks has Unity Catalog enabled, the Unity Catalog Enabled option must be set to true.
- Test the connection and proceed if it succeeds.
- Start the crawler to crawl the Databricks assets.
Full Databricks Integration
In this mode, the analysis jobs are run on Databricks job clusters. Torch consumes Databricks Native Spark tables as well as Delta lake tables. In addition to other supported datasources, for Quality Evaluation and any other Torch supported feature executions. Each Torch job creates a Job Cluster on Databricks on which the computation is performed.
Torch requires the following parameters to enable a complete Databricks integration:
- A path on DBFS to upload the Torch binaries.
- Cluster URL, UID and Personal Access Token having access to submit the jobs and run queries. Personal access token must have the access to upload the Torch binaries to the above mentioned location.
- An S3 bucket to store the Torch internal results: The access to S3 bucket from Databricks is handled via Instance Profiles. The instance profile must be added to Databricks. The instance profile ARN should be provided to Torch during the deployment. For more information on enabling secure access to S3 from Databricks, see https://docs.databricks.com/administration-guide/cloud-configurations/aws/instance-profiles.html.
Please follow https://docs.databricks.com/administration-guide/access-control/index.html to manage access and personal access tokens
On completion of the above steps, the following details must be shared to configure other Torch services:
URL of the Databricks cluster, Cluster ID, UID and Personal Access Token. For example:
- Databricks Cluster URL: https://dummy.cloud.databricks.com
- Cluster slug: 0811-040399-dummy267. This is found on the Cluster Details page in the Tags section.
- Uslug token
- Personal Access Token: Personal Access Token is generated on the User Settings page.
The path of the ad-analysis-app.jar file on DBFS. The path to the ad-analysis-app.jar in the preceding example is dbfs:/databricks/acceldata/ad-analysis-app.jar.
The S3 bucket to which the job results must be saved, as well as the instance profile ARN that is added to Databricks and has access to this S3 bucket.
Along with the the above, customizations for job clusters must be provided during deployment.
To enable Databricks as the computation engine for Torch, perform the following steps:
- Login to Admin Console.
- Select "Use Databricks" in the Settings for Spark Support section.
- Provide the required details.

Configurations for saving the results of jobs
- Navigate to "Configurations for Saving the results of Jobs" section.
- Select the required storage.
- If S3 is the storage location, the following two types of access are available:
- Access Key and Secret Key based - If the S3 bucket can be accessed using AWS Access Key and Secret Keys.
- Instance Profile Based Access - In this mode, access key and secret key are not required. But the Databricks cluster should have access to the S3 bucket via instance profiles. This is the preferred mode if S3 is used as the storage location.
