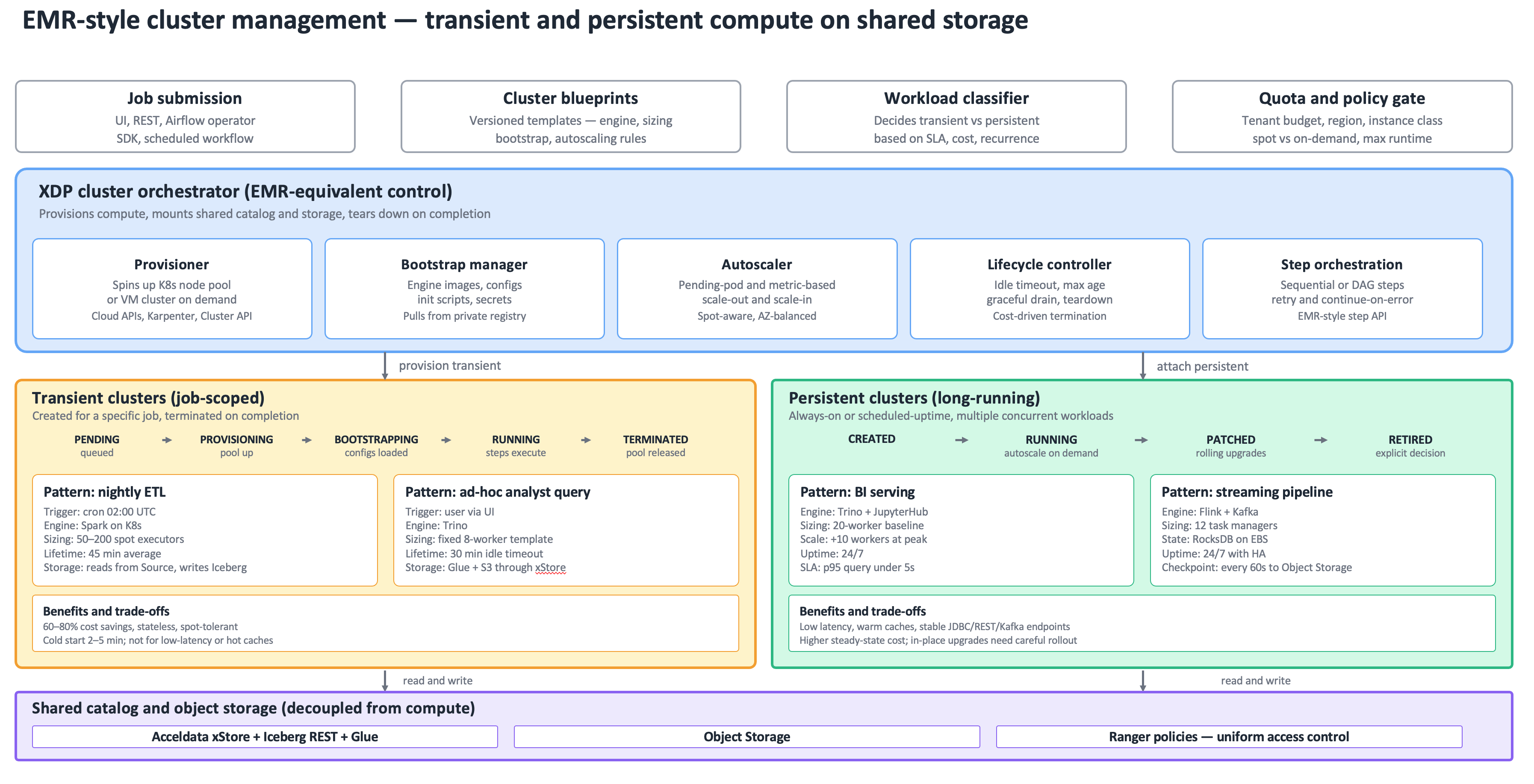
AWS EMR established a pattern that has become the dominant operational model for large-scale data processing — provisioning compute clusters on demand for specific workloads, run against shared catalog and storage, and tear them down when done. XDP implements this pattern natively on Kubernetes, with feature parity for transient workloads (job-scoped clusters) and persistent workloads (long-running clusters), all governed by the same control plane and reading from the same data substrate.
Figure : EMR-style cluster orchestration — transient and persistent clusters provisioned on demand against decoupled catalog and storage.
The cluster orchestrator
The XDP cluster orchestrator is the EMR-equivalent component. It exposes a job submission API, accepts versioned cluster blueprints, and drives the full provisioning lifecycle:
Provisioner — creates Kubernetes node pools or VM-backed clusters on demand. Integrates with Karpenter, Cluster Autoscaler, or Cluster API depending on the substrate. On AWS, can directly use EC2 fleet APIs for spot-aware provisioning across instance types and availability zones.
Bootstrap manager — applies engine images, configuration overlays, and init scripts before workload pods start. Pulls all images from the private registry inside the customer trust boundary so no runtime dependency on the upstream registry exists.
Autoscaler — scales node pools based on pending pods, custom metrics (Spark executor backlog, Kafka consumer lag, query queue depth), or scheduled rules. Spot-aware — knows which workloads can tolerate interruption and biases placement accordingly.
Lifecycle controller — enforces idle timeouts, maximum cluster age, graceful drain on shutdown, and cost-driven termination. The controller is the component that turns transient clusters into a tractable cost story.
Step orchestration — sequential or DAG-based steps within a cluster, with retry, continue-on-error, and conditional branching. EMR's step API is mirrored to ease migration of existing workflows.
Transient clusters
A transient cluster exists for the duration of a single job — typically minutes to hours. It is created, used, and destroyed in a single workflow execution. The lifecycle has five canonical phases:
PENDING — request queued behind quota and policy validation.
PROVISIONING — node pool created, networking and storage attached.
BOOTSTRAPPING — engine images pulled, configuration applied, credentials injected.
RUNNING — steps execute, autoscaling responds to load.
TERMINATED — graceful drain, resources released, final state and logs persisted.
Common transient patterns
Two patterns dominate transient cluster usage. The first is scheduled batch ETL — a nightly Spark job triggered by Airflow at 02:00 UTC, sized at 50 to 200 spot executors, running for 30 to 60 minutes, reading raw data from S3 and writing partitioned Iceberg output. The cluster is gone by 03:00 and the customer pays only for the actual minutes of compute.
The second is an ad-hoc analyst query — a Trino cluster spun up when an analyst opens a notebook, sized at a small fixed worker count (typically 8 workers), with a 30-minute idle timeout. The first query takes longer because of cold start (2 to 5 minutes), but subsequent queries are interactive. The cluster terminates automatically when the analyst stops working.
Cost profile
Transient clusters typically deliver 60 to 80 percent cost savings versus an always-on cluster sized for peak. The savings come from three sources: spot instances are tolerated because failures restart work rather than corrupting state; right-sizing is per-job rather than per-fleet; idle time is zero by definition. The trade-off is cold-start latency — interactive workloads with sub-second SLAs need persistent clusters, not transient ones.
Persistent clusters
A persistent cluster runs continuously, with autoscaling responding to load and rolling upgrades applied in place. The lifecycle is shaped differently — CREATED, RUNNING, PATCHED, RETIRED — with no termination on idle. Persistent clusters are appropriate when:
Workloads have low-latency SLAs that cannot tolerate cold start (typical example: BI serving with p95 query latency under 5 seconds).
Connections are persistent (Kafka brokers, JDBC pools, streaming sources).
State is local and large (Flink RocksDB checkpoints, Spark structured streaming state stores, materialized caches).
The cluster is shared by many concurrent users and the cost of always-on is amortized across that population.
Common persistent patterns
BI serving uses Trino with a 20-worker baseline, scaling to 30 workers during business hours, queries hitting hot caches and answering in seconds. JupyterHub on the same cluster gives data scientists interactive sessions without re-provisioning. Streaming pipelines use Flink with 12 task managers, RocksDB on EBS for state, checkpoints to S3 every 60 seconds, with active-passive HA across availability zones.
Operational responsibilities
Persistent clusters require more careful operational hygiene than transient ones. Upgrades happen in place via rolling pod restarts, which means tenants must be communicated with and connection draining must be configured. Capacity planning matters because pooled capacity must cover peak demand. State on local disk must be backed up — for Flink, that means checkpoint retention policies; for streaming state, periodic externalization to durable storage.
Decoupled storage — the EMR pattern
The architectural property that makes EMR-style management work is the decoupling of compute from storage. Compute clusters are ephemeral; data is permanent. In XDP, this manifests as:
Catalog through xStore — every cluster, transient or persistent, attaches to the same federated catalog. Schema is shared; tables are visible across clusters; lineage is captured uniformly.
Data on object storage — S3, GCS, ADLS, Vast S3, Ceph S3 or Apache Ozone. Iceberg manifests and Parquet files persist independently of any cluster's lifetime. A table written by a transient Spark job is queryable seconds later by a persistent Trino cluster.
Policy through Ranger — access control is uniform regardless of which cluster the query runs on. A user denied access to a column will be denied in Spark, in Trino, and in any other engine because the policy lives at the catalog layer.
This decoupling is what allows XDP to mix transient and persistent clusters freely. The same data is queryable by a long-running Trino cluster for interactive BI and by a transient Spark cluster for nightly ETL — the clusters never need to know about each other.
Comparison with AWS EMR
XDP's EMR-style management offers feature parity with EMR on the orchestration model, with several differences that reflect XDP's Kubernetes-native, sovereign-deployment positioning:
Dimension | AWS EMR | XDP EMR-style |
|---|---|---|
Substrate | EC2 + custom AMIs | Kubernetes (EKS, GKE, AKS, OpenShift, on-prem) |
Cluster types | On-demand, EMR Serverless, EMR on EKS | Transient, persistent — both on K8s |
Engine versions | AWS-curated | Customer-curated through private registry |
Catalog | Glue, Hive Metastore | xStore federates Glue, Hive, RDBMS |
Authorization | IAM + Lake Formation | Ranger (uniform across engines) |
Multi-cloud | AWS only | AWS, GCP, Azure, on-prem |
Air-gapped | Not supported | Native (sovereign deployment model) |
Cost model | AWS marketplace pricing | Customer-controlled infrastructure |
Step API | EMR steps | Equivalent + DAG support |