Data Reliability
Ensuring that data is highly available, accurate, timely, and free from errors and inconsistencies is vital for maintaining data integrity and, ultimately, business success. The following are the key aspects of data reliability and why it is indispensable for organizations.
Key Aspects of Data Reliability
- Accuracy: Accurate data is error-free and conveys real-world information that is up-to-date and inclusive of all relevant data sources. Inaccurate data can lead to significant issues and severe consequences.
- Completeness: Completeness refers to how inclusive and comprehensive the available data is. It must include all necessary information to serve its purpose, preventing erroneous decisions based on incomplete or incomprehensible data.
- Consistency: Data consistency ensures uniformity and conformity to specific standards across related databases, applications, and systems. Inconsistencies can result in incorrect analyses and outcomes.
- Uniformity: Data must adhere to a consistent structure to avoid misunderstandings and errors, which can impact business operations.
- Relevance: Data must align with its intended use or purpose; irrelevant data holds little value.
- Timeliness: Timely data is current and relevant, enabling agile decision-making. Outdated information can be costly in terms of time and money.
When it comes to discovering, comprehending, and successfully utilizing data sources and their resources, data dependability is vital for individuals and enterprises. It ensures that data sources are trustworthy, reliable, and accurate, allowing informed decisions about which sources to study.
Understanding data assets is crucial because it helps users understand the quality, completeness, and validity of the data. Data reliability assures data accuracy and consistency through rigorous quality assurance processes. Reliable data sources provide for the seamless integration of several sources, easing data integration and interoperability.
Building trust in data is also crucial since it promotes credibility, reduces uncertainty, and boosts overall confidence in results. Mitigating risks and errors is also important, because data dependability minimizes the potential for organizations to reach incorrect conclusions based on faulty data, thereby strengthening data governance and risk management approaches.
After you add a data source, ADOC continuously monitors the assets in your data sources. This assures that high-quality data exists in your assets, and your data is reliable.
The Reliability capability in ADOC provides you the following features:

Example Illustration
When you add a data source and crawl the data source, the assets are displayed in the Asset List View.
Data Sources
A Data Source is an inventory of the organization's data assets. It provides detailed information about each data asset, such as its location, format, owner, and usage. The catalog helps organizations manage their data more effectively by enabling users to quickly find and access the data they need.

Policy
Policies are used to ensure that data residing in systems is of the highest quality.

Types of Data Policies
ADOC has four different types of policy. Data quality, Reconciliation, Data Drift, and Schema Drift are all essential policies in the context of Data Reliability.
- Data Quality Policy: The ADOC data quality policy is part of the framework for data observability. A Data Quality Policy is a single asset's quality measure. It examines a variety of attributes, including Null Values, Asset Data Type, and Regex Match. Overall, the Data Quality policy is a crucial instrument for assuring a single asset's accuracy and completeness. It helps to maintain high data quality standards by checking for critical attributes.
- Reconciliation Policy: Within the context of data observability the Reconciliation policy is a quality indicator for two assets that are comparable in nature. This rule compares two assets by comparing several features such as Profile Match and Equality Match. In conclusion, both the Data Quality policy and the Reconciliation policy are critical instruments for sustaining high data quality standards. The Data Quality policy focuses on a single asset and checks for characteristics like Null Values and Regex Match, whereas the Reconciliation policy compares two similar assets by matching features like Profile Match and Equality Match. These policies work together to assure the accuracy and completeness of data, which is critical for making informed decisions and meeting quality objectives.
- Data Drift Policy: When the underlying data changes, Data Drift determines the % change in various metrics. The user can define Data Drift rules to validate the data change against a tolerance threshold for each type of measure. By monitoring data drift, the user may guarantee that the data remains consistent and correct over time. This is significant since data might change owing to a variety of circumstances such as system upgrades, data migrations, and data entry errors. The user may detect and fix any deviations from expected values by defining tolerance limits and creating data drift rules.
- Schema Drift Policy: Changes to a schema or table between previously crawled and presently crawled data sources are detected by the schema drift policy. This ensures that the data is correctly formatted and that any changes to the schema are deliberate. By identifying schema drift, the user can identify and solve any possible issues that may develop as a result of changes to the data structure. Overall, these policies and tools collaborate to ensure that the data is of high quality and can be relied on when making critical business choices.
Anomalies
An anomaly is said to occur if your costs deviate from the previous cost trends. This table displays the cost trend on anomalies across the selected time period. The cost on any given day is considered to be an anomaly if it exceeds the average cost of previous 7 cost days by 50%.
Consider that your Snowflake account incurred the following cost daily from July 1 to July. 10.
| Date | Cost |
|---|---|
| July 1 | $10 |
| July 2 | $20 |
| July 3 | $15 |
| July 4 | $10 |
| July 5 | $12 |
| July 6 | $16 |
| July 7 | $18 |
| July 8 | $22 |
| July 9 | $15 |
| July 10 | $18 |
The expenditure incurred on July 8th is considered an outlier or an anomaly.
This is because the average cost of the previous seven days (July 1 to July 7) was $14.42.
50% of the value is equal to $7.21. The cost cannot be more than 50% of the mean value, which is computed as the sum of $14.42 and $7.21, yielding $21.63.
As a result, the expenditure incurred on July 8th is considered an outlier because its value of $22 surpasses the threshold of $21.63.
The graph considers the cost of the last 7 days, excluding the present day. In the aforementioned scenario, assuming no costs were incurred on July 1 and 2, the expenses from June 29, June 30, and July 1 to July 5 will be included.
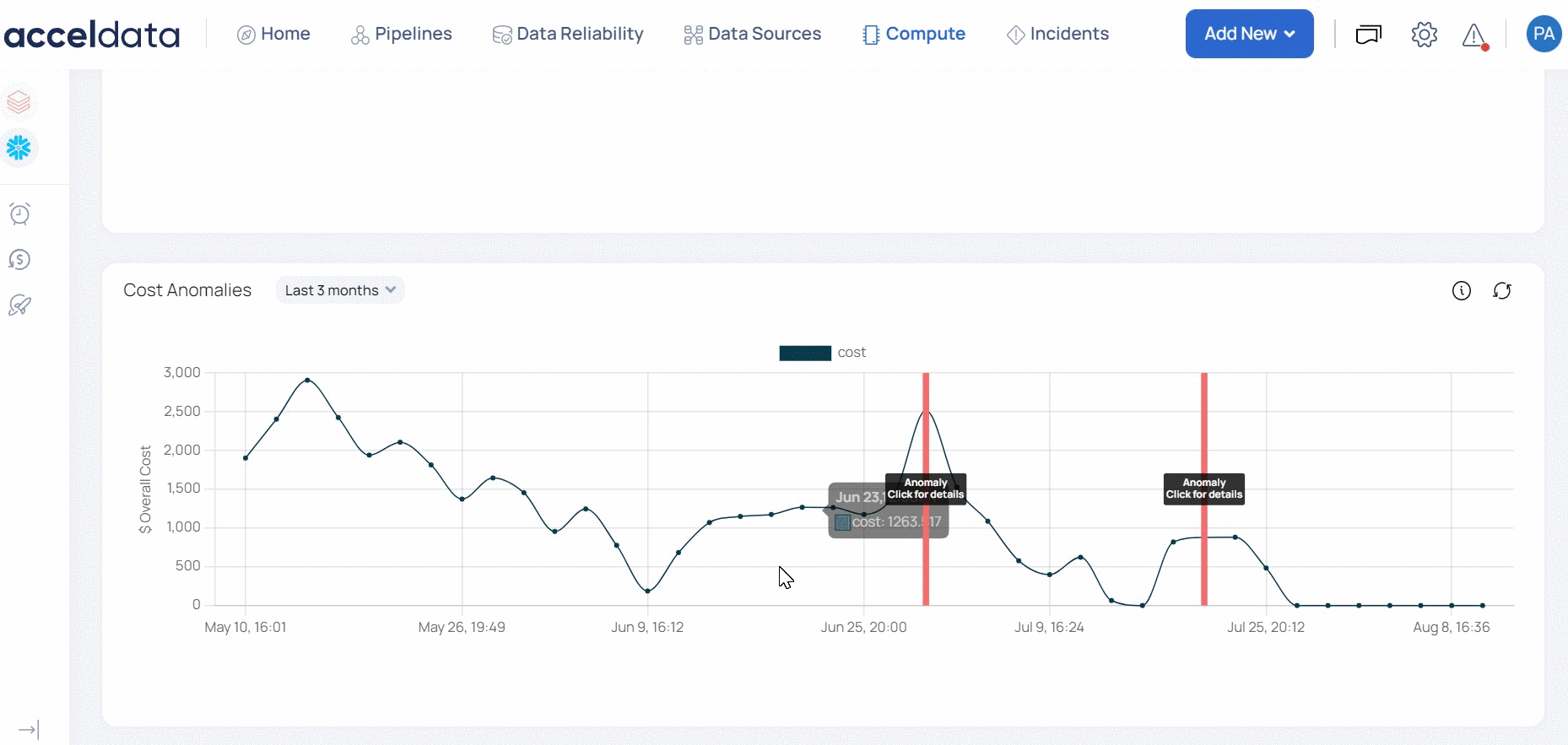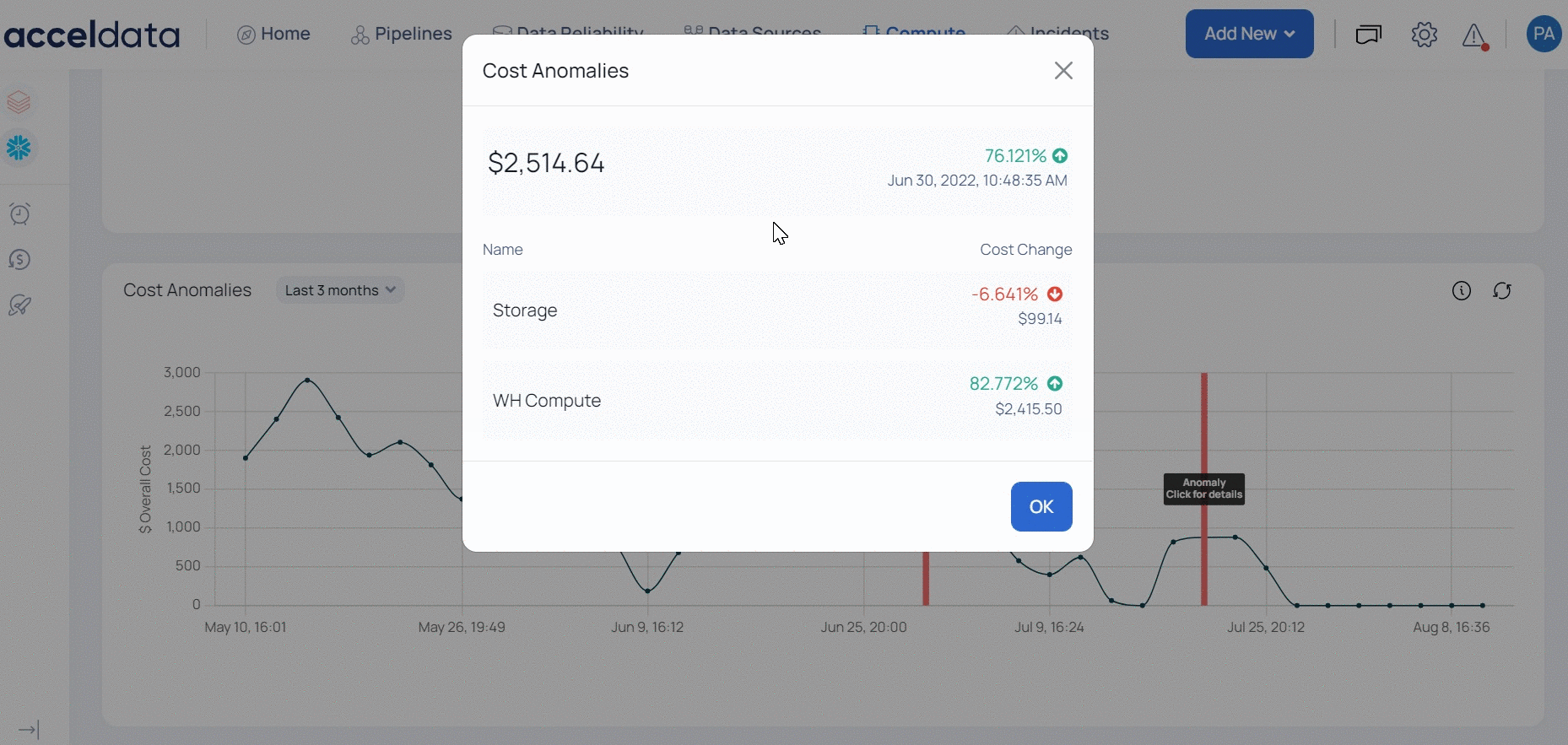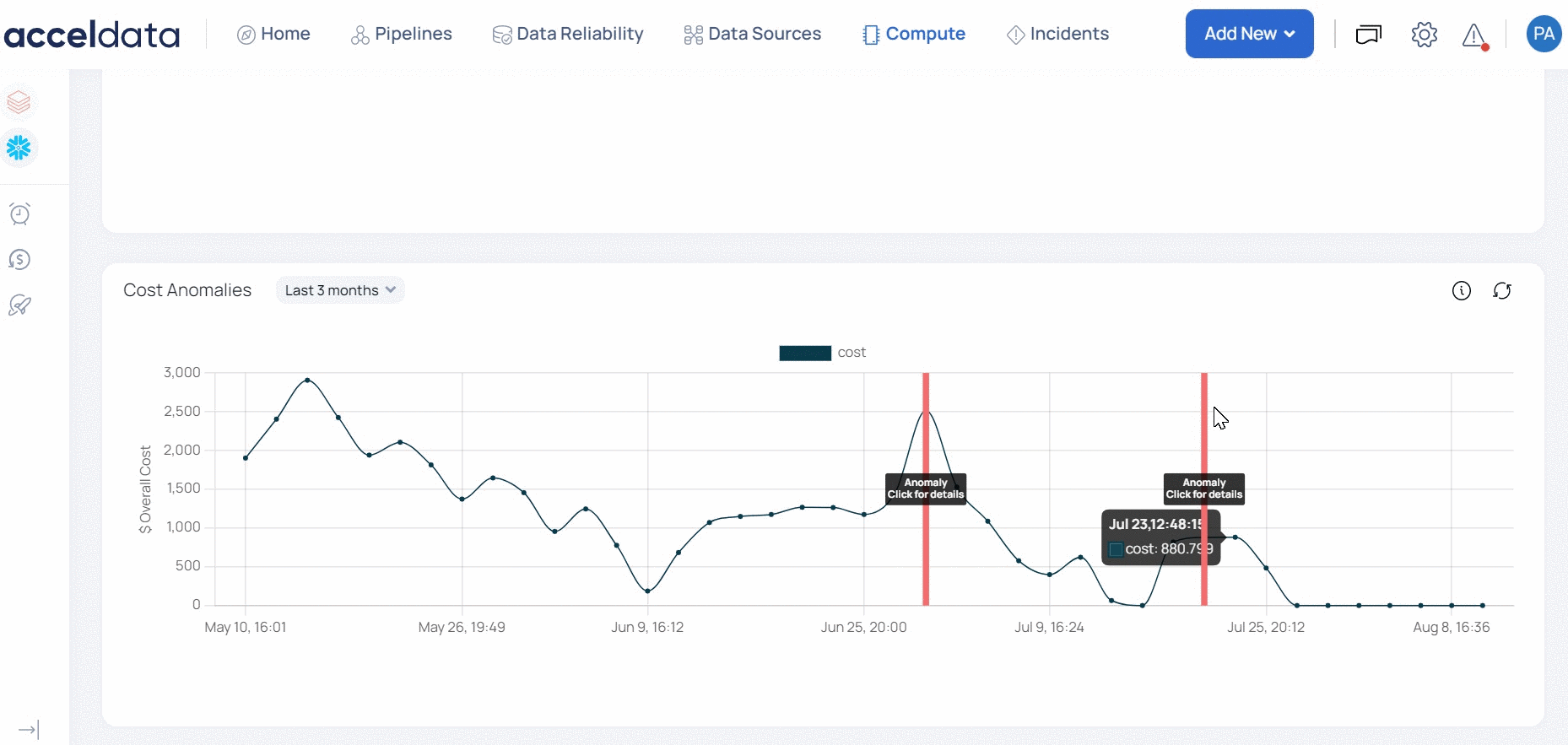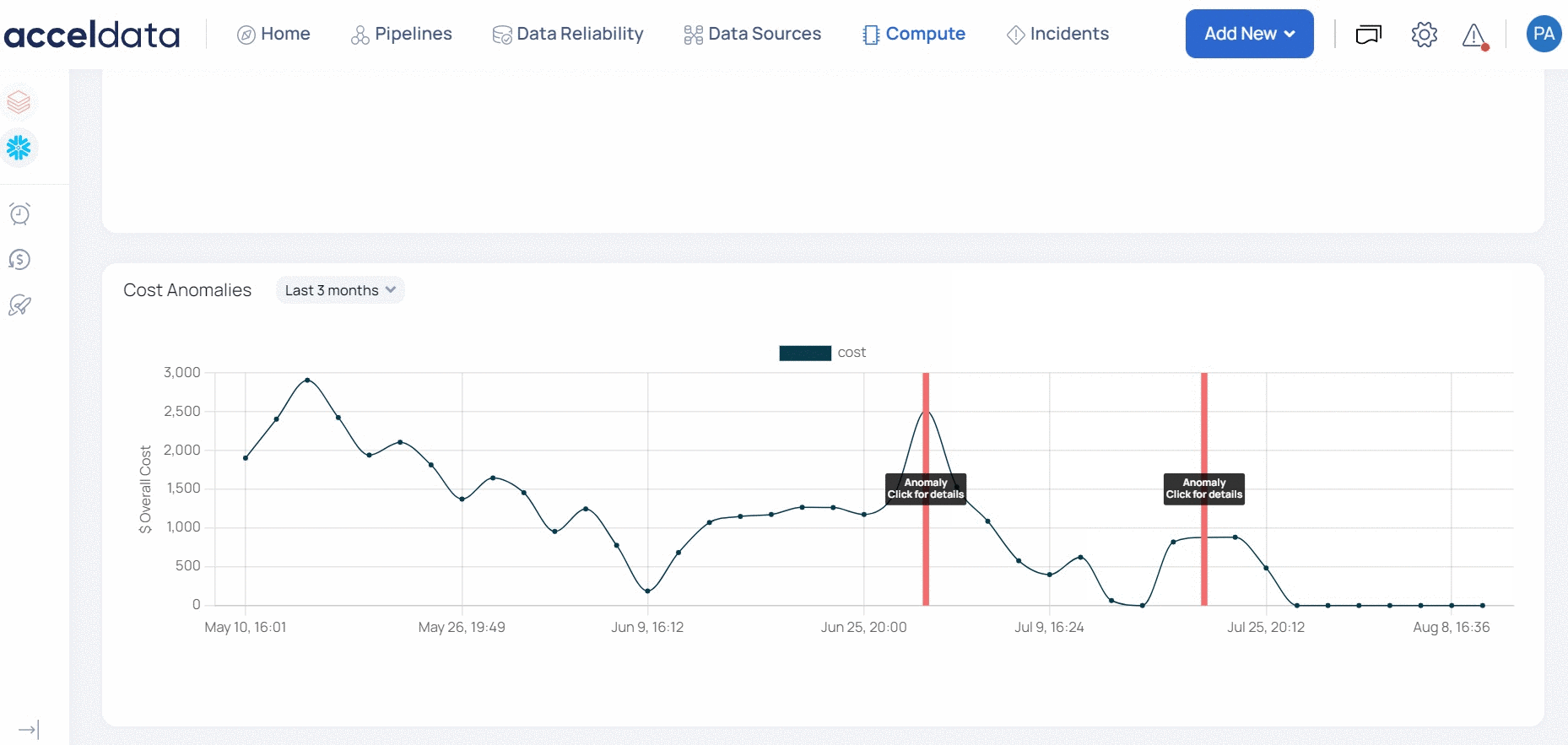
ADOC displays the anomaly costs with a red vertical line. You can click the red line to view the total percentile increase and also the individual service costs that caused the spike in the cost for that day. You can filter data on this graph.