Resource Recommendations, Auto-Sizing, and Run-Time Estimation Guide
Overview
The ADOC Resource Recommendation feature for Spark jobs is designed to optimize resource allocation by recommending appropriate compute resources, leading to improved performance and cost efficiency. This guide outlines the key components of the feature, including inventory strategies, T-shirt size-based resources, node-driven recommendations, and auto-retry mechanisms. These features are available for Kubernetes Spark Engine environments.
Key Features:
- Dataplane Resource Inventory: Resources are preloaded based on inventory strategy for efficient management.
- T-Shirt Size Based Resource Inventory: Default options of Small, Medium, and Large resources are preloaded, with Medium as the default.
- Node and Asset Driven Recommendations: Recommendations are tailored based on specific nodes and assets, allowing more precise resource allocation.
- Auto-Retry Mechanism: Automatically adjusts and retries using higher resources if memory-related failures are detected during job execution.
- Execution-Level Audit: Detailed audit of resource usage and strategies for individual Spark job executions.
Resource Inventory Strategies
The ADOC Resource Recommendation feature provides two strategies for recommending and managing compute resources for Spark jobs:
1. Inventory-Driven Strategy
This strategy uses pre-configured inventory levels—such as Small, Medium, and Large—to recommend resources. The system defaults to the "Medium" configuration for most jobs unless specified otherwise. The inventory strategy also includes an auto-retry feature, which handles memory-related issues (e.g., Out-Of-Memory or ExecutorLostFailure) by retrying with the next higher inventory level, which is determined based on the predefined order of inventory sizes (e.g., from Small to Medium to Large) until the issue is resolved. Default retry attempts are limited to three.
2. Custom-Driven Strategy
The custom-driven strategy is more flexible, allowing users to set their own resource parameters, including driver memory, executor memory, core count, and retry attempts. In case of memory-related failures, the system boosts the driver and executor memory allocation by a configurable multiplier, typically doubling it for each retry. This retry process also has a maximum of three attempts.
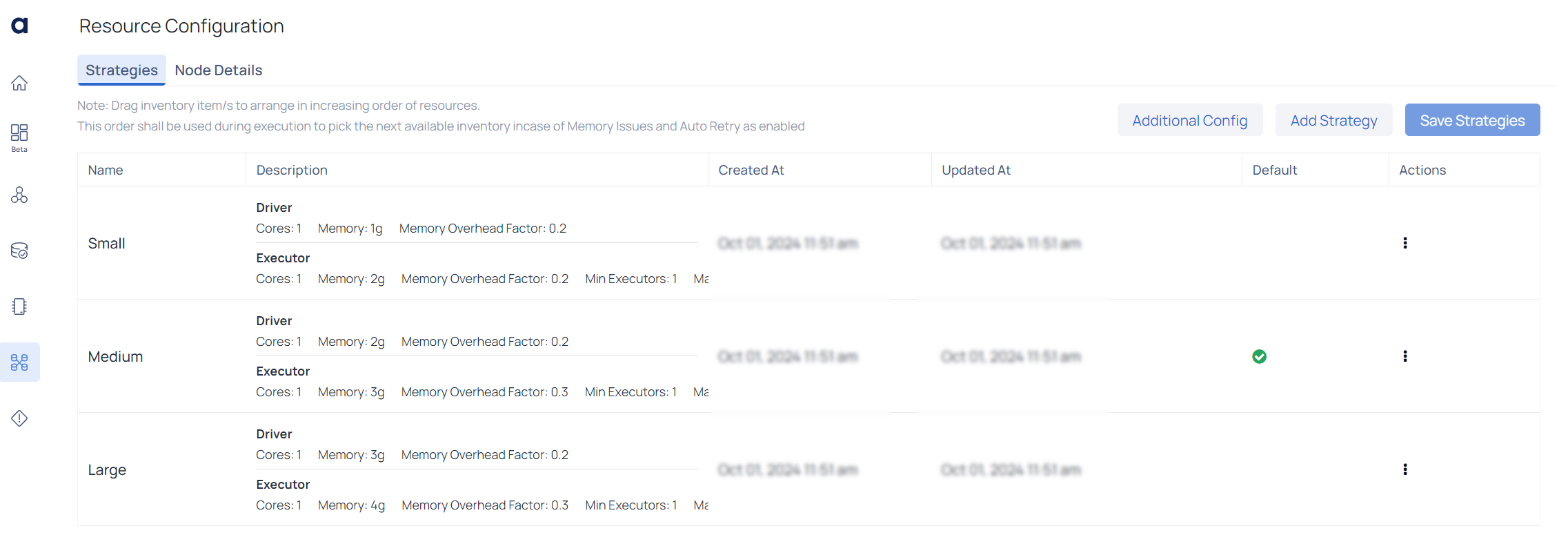
| Element | Description |
|---|---|
| Resource Configuration | The Resource Configuration page allows users to define and manage resource allocation strategies for the data processing engine, such as setting memory and core usage for Spark jobs. |
| Additional Config | Opens a panel for fine-tuning the selected resource strategy. |
| Add Strategy | Initiates the creation of a new resource strategy, allowing users to define parameters like memory allocation and cores. |
| Save Strategies | Saves all changes made to the configurations. |
| Name | The strategy's name, representing its resource allocation level (e.g., Small, Medium, Large). |
| Description | Details of driver and executor configurations, including cores, memory allocation, and overhead factors. |
| Created At | Date and time when the strategy was created. |
| Updated At: | Date and time of the last modification. |
| Default | Indicates if the strategy is set as the default (marked with a green check icon). |
| Actions | A three-dot menu for actions like editing or deleting the strategy. |
Strategy Configuration Details
Under the Description column, each strategy provides detailed driver and executor configurations:
Driver Configuration:
- Cores: Number of CPU cores allocated to the Spark driver.
- Memory: Amount of memory assigned to the driver.
- Memory Overhead Factor: Overhead applied to the driver's memory.
Executor Configuration:
- Cores: Number of CPU cores for the Spark executor.
- Memory: Amount of memory allocated to the executor.
- Memory Overhead Factor: Overhead for the executor’s memory.
- Min Executors: Minimum number of executors initiated.
- Max Executors: Maximum number of executors that can be utilized.
Default Strategy Indicator
A green checkmark under the Default column highlights the strategy set as the default configuration. This default will be used unless other settings are specified.
Action Menu
Under the Actions column, each strategy has a three-dot menu with options to:
- Edit: Modify the configuration.
- Delete: Remove the strategy.
- View Details: View more detailed information about the configuration.
Node and Asset-Based Resource Recommendations
Users can further enhance the recommendations by providing node and asset information, which helps the system tailor the resource allocation more precisely to the specific workload requirements. By understanding the available hardware (nodes) and the nature of the data (assets), the system can better allocate memory, CPU, and other resources to achieve optimal performance.
- Node Details: Include core count, memory, and the number of nodes.
- Asset Information: Define minimum and maximum asset sizes.
When this information is provided, the Resource Recommendation feature dynamically adjusts the configuration to optimize resource usage based on these parameters.
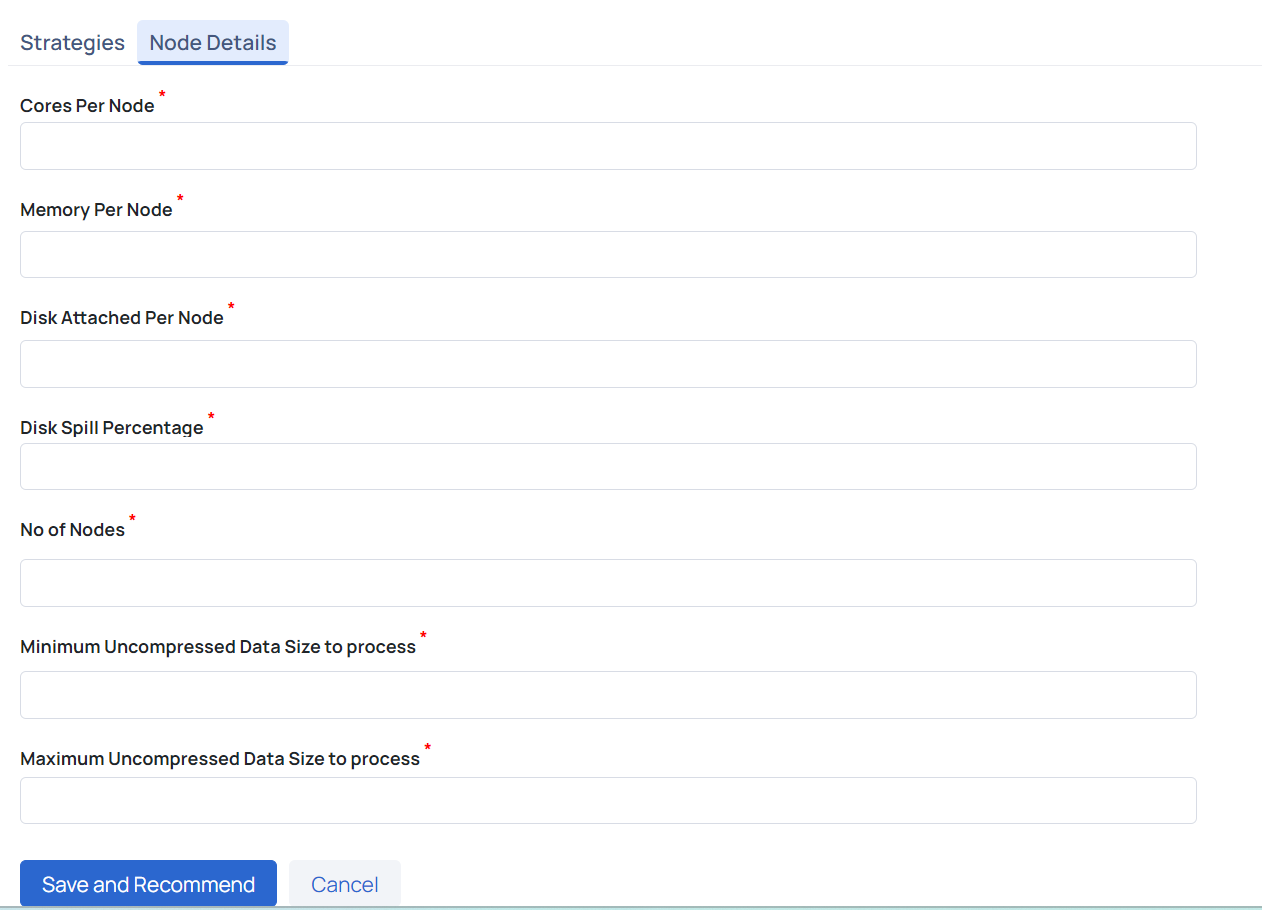
Node Details Configuration
The Node Details tab allows users to input key details about their nodes to enhance the accuracy of resource recommendations. Users need to provide the following information:
- Cores Per Node: Number of CPU cores per node, with a recommended core-to-memory ratio of 1:4.
- Memory Per Node: Amount of memory per node (e.g., 32 GB), maintaining a core-to-memory ratio of 1:4 for faster processing.
- Disk Attached Per Node: Recommended to have at least 100 GB per node for disk storage.
- Disk Spill Percentage: Percentage of data spilled to disk if it cannot fit in memory, which impacts performance.
- No of Nodes: Total number of nodes available for Spark jobs.
- Minimum and Maximum Uncompressed Data Size to Process: Specifies the data size range that influences resource recommendations.
Configuring Resources
At the Dataplane level, users can view and adjust resource settings:
- Preloaded Sizes: Users have the ability to select Small, Medium, or Large configurations or create custom configurations based on their requirements.
- Order of Inventory Levels: Users can arrange inventory levels based on priority, allowing them to specify the order in which inventory sizes should be applied during an auto-retry scenario.
- Detailed Configuration: Users can add new configurations (e.g., "X-Large") and adjust resource values accordingly. The configuration can be saved and applied to individual Spark jobs or policies.
Strategies Configuration
The Strategies tab provides an overview of the pre-configured resource levels:
- Small, Medium, and Large: Each level defines the driver and executor settings, including cores, memory, and memory overhead factor.
- Adjustable Strategy Order: Users can drag and drop inventory items to arrange the order, which impacts how the auto-retry mechanism selects the next configuration.
Auto-Retry Mechanism
The Auto-Retry Mechanism aims to minimize job failures by automatically adjusting resource allocation in response to memory-related failures. If a job fails due to memory issues, the system increases the resource allocation for the next run—whether scheduled or manual—to enhance the chances of successful execution.
The process includes:
- Inventory Driven Retry: The system moves to the next higher inventory level and retries if a memory-related failure occurs.
- Custom Resource Retry: For custom settings, memory (e.g., executor and driver memory) is increased by a fixed multiplier and the job is retried. This continues for up to three attempts, providing opportunities to resolve transient issues.
Job Resource Audit
A comprehensive audit mechanism is in place to track the resource allocation strategy for each job. This helps end-users understand what configurations were used during each run, what issues were faced, and how those issues were resolved, ensuring transparency and better debugging of performance issues.
Viewing Job Resources
To view resources for a particular Spark job execution:
- Navigate to the Job Resource section to see details of the resource configuration used during the run, including inventory level (e.g., Small, Medium, Large, Custom) and the status of auto-retry.