Upgrade from Version 2.2.1 to 3.1.0
This document describes the steps to migrate from Pulse 2.1.1 version to 3.1.0 version. You must perform the steps mentioned in this document in all your clusters.
Backup Steps
- Take backup of Dashplots Charts using Export option.
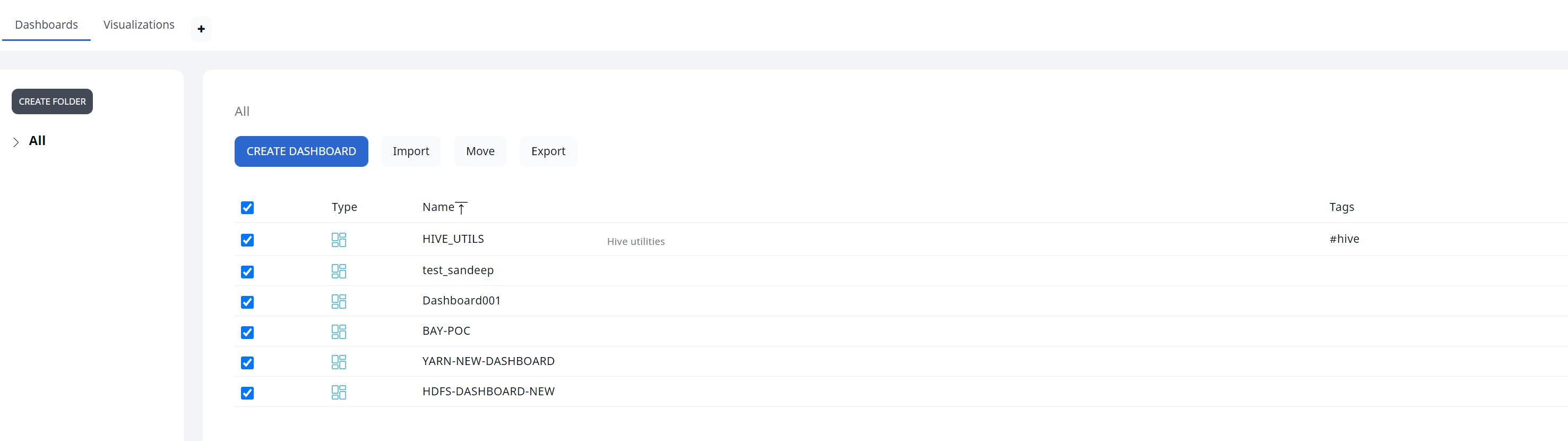
- Take backup of Alerts using the Export option.

Migration Steps
- Requires Pulse server downtime.
- Requires re-installation of Pulse agents running in all the cluster nodes.
Please plan your migrations accordingly.
- (Optional) Execute the following steps only on the standalone nodes of a multi-node Pulse deployment.
- Generate the encrypted string for the
mongodb://accel:<MONGO_PASSWORD>@<PULSE_MASTER_HOST>:27017mongo URI, by executing the following command.
- Generate the encrypted string for the
accelo admin encryptCopy the output of the above command.
b. Add the following environment variables to the /etc/profile.d/ad.sh file.
MONGO_URI="<<Output of step 1.a>> " # You must modify the content in double quotes as per the output of step 1a. MONGO_ENCRYPTED=truePULSE_SA_NODE=trueOnce you execute the above steps, you must receive the output as shown in the following image.
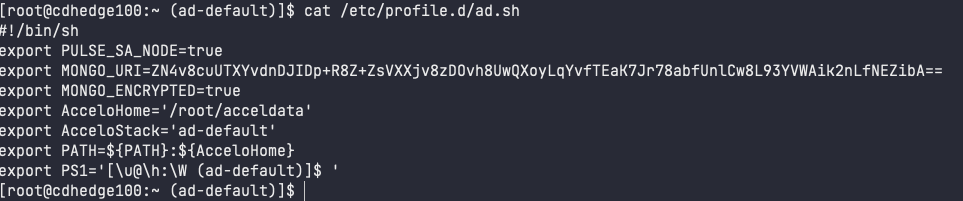
c. Source the /etc/profile.d/ad.sh file by executing the following command.
source /etc/profile.d/ad.sh- Stop the ad-streaming and ad-connector connectors by executing the following commands.
docker stop ad-streaming_defaultdocker stop ad-connectors_default- Enter the Mongo container by executing the following command.
docker exec -it ad-db_default bash- Login to the Mongo shell by bececuting the following command.
mongo mongodb://accel:<PASSWORD>@localhost:27017/admin- Execute the following commands.
show databases;use <db_name>;- Rename the collection by executing the following command.
db.yarn_tez_queries.renameCollection("yarn_tez_queries_details")You must get a response which says { "ok": 1 }.
- Exit the Mongo shell by executing the following command.
exit- Ensure that you are still in the ad-db container bash shell. Use the following command to export the past 7 days data with the required fields from the tez_queries_ nsure that details collection. You can refer to this link to convert a date to epoch value.
mongoexport --username="<username>" --password="<password>" --host=localhost:27017 --authenticationDatabase=admin --db="<db_name>" --collection=yarn_tez_queries_details -f '__id,callerId,user,status,timeTaken,queue,appId,hiveAddress,dagId,uid,queue,counters,tablesUsed,startTime,endTime,llap' --query='{"startTime": {"$gte": <last 7 days epoch millisec>}}' --out=/tmp/tqq.jsonYou must get a response as # document(s) imported successfully. 0 document(s) failed to import.
- Using the following command, import the data file returned by the preceding command into the yarn__tez_ queries collection.
mongoimport --username="<username>" --password="<password>" --host=localhost:27017 --authenticationDatabase=admin --db="<db_name>" --collection=yarn_tez_queries --file=/tmp/tqq.jsonYou must get a response as # document(s) imported successfully. 0 document(s) failed to import.
- Execute the below command to complete the migration.
accelo admin database index-dbYou must receive the following response.
Trying to create indices for the MongoDB database ..INFO: Indices created successfully with the following output.OUTPUT: MongoDB shell version v4.2.19connecting to: mongodb://localhost:27017/ad_hdp_qe?authSource=admin&compressors=disabled&gssapiServiceName=mongodbImplicit session: session { "id" : UUID("5cb5bb0a-c399-49bb-8a0f-7945a4daccac") }MongoDB server version: 4.2.19- Download the new CLI with
3.1.0version.- Execute the following migration command steps to migrate to 3.0.0. a. Execute the following CLI migrate command.
accelo migrate -v 3.0.0 -ab. Based on whether you want to migrate as a Root user or a non-root user, execute the commands from one of the following columns.
| Non Root User | Root User |
|---|---|
a. Disable all the Pulse Services by executing the following command.
| a. If accelo CLI is going to be run as a root user, execute the following command:
|
b. Change the ownership of all data directories to 1000:1000 by executing the following commands.
| |
c. Execute the following migration command with the
| |
d. Execute the following command to uninstall the Pulse Hydra agent from all the current active cluster nodes.
|
You must repeat the steps 12.a, 12.b, and 12.c for all the clusters configured on the Pulse server, one by one.
- Execute the following steps to migrate to 3.1.0. a. Execute the following CLI migrate command.
accelo migrate -v 3.1.0 -ab. Based on whether you want to migrate as a Root user or a non-root user, execute the commands from one of the following columns.
| Non Root User | Root User |
|---|---|
a. Disable all the Pulse Services by executing the following command.
| a. If accelo CLI is going to be run as a root user, execute the following command.
|
b. Change the ownership of all data directories to 1000:1000 by executing the following commands.
| |
c. Execute the following migration command with the
|
- Execute the following command to deploy the Pulse core components.
accelo deploy core- Execute the following command to deploy the required addons.
accelo deploy addons- Execute the following command to reconfigure all the clusters, configured in the Pulse server. The reconfigure command will update the configurations for all the clusters.
accelo reconfig cluster -a- Execute the following command for remote uninstallation.
accelo uninstall remote- Execute the following command to deploy the hydra agents for all the clusters, configured in Pulse server.
accelo deploy hydra- (Optional) Execute the following commands to deploy auto action playbooks, if you have the ad-director add-on component deployed.
accelo deploy playbooksaccelo restart ad-director- Execute the following command to update the HDFS dashboard data.
accelo admin fsa load- Execute the steps in one of the following columns based on whether you are using Pulse single-node or Pulse multi-node setup.
| Single-node multi Kerberos Pulse Setup | Multi-Node multi Kerberos Pulse Setup |
|---|---|
| Update the spark.events.url section in the acceldata<clustername>.conf file. You must replace the <clustername> in the field with the following URL. | Update the spark.events.url section in the acceldata<clustername>.conf file. You must replace the <clustername> in the field with the following URL. |
spark.events.url = "http://ad-sparkstats:19004/events" | http://<IP_WHERE_SPARKSATS_CONTAINER_IS_RUNNING>:19004/events |
- Execute the following command to add the ad-events connection info in acceldata.conf file and Mongo.
accelo reconfig clusterDeploy NATS Container
Pulse now uses the NATS queue. To enable the NATS queue, you must execute the following command.
accelo deploy coreSet Time Zone for Logs
The commands in this section facilitate you to update the environment variables such that they match the server time zone in JODA time format.
- Execute the following command if the ad-logsearch.yml file is not present at the $AcceloHome/config/docker/addons directory.
accelo admin makeconfig ad-logsearch- Open the ad-logsearch.yml file from the $AcceloHome/config/docker/addons directory.
- Update the following environment variable's value to match the server’s time zone in the joda format and add it to the ad-logstash section.
- TZ=<joda time zone for the server/node>- Execute the following command to restart the logstash container. This ensures that the above changes are applied.
accelo restart ad-logstashOozie Connector Update
Add the following property to the acceldata/config/acceldata<CLUSTER NAME>.conf file, under the oozie.connectors section. Select the column based on the database applicable to your setup.
| mariadb/mysql | PostgreSQL | Oracle |
|---|---|---|
type = "mariadb/mysql" user = "<DB_USERNAME>" pass = "<ENCRYPTED_DB_USERNAME>" driver = "org.mariadb.jdbc.Driver" | type = "postgresql" user = "<DB_USERNAME>" pass = "<ENCRYPTED_DB_USERNAME>" driver = "org.postgresql.Driver" | type = "oracle" user = "<DB_USERNAME>" pass = "<ENCRYPTED_DB_USERNAME>" driver = "oracle.jdbc.driver.OracleDriver" |
Pulse Hooks Deployment
Pulse now uses the NATS queue. To get the streaming data from NATS, you must configure and deploy the JAR files in various folders. This section describes the folders in which you must deploy various JAR files.
Acceldata Hive Hook for HDP2
Hook: Acceldata Hive Hook for HDP2
Binary: ad-hive-hook-HDP2-1.0.jar
Deployment: Place the above JAR file in the /opt/acceldata/ folder in HDFS node.
Configuration Steps:
- ad.events.streaming.servers (ad-events:4222)
- ad.cluster (your cluster name, ex: ad_hdp3_dev)
- hive.exec.failure.hooks (io.acceldata.hive.AdHiveHook)
- hive.exec.post.hooks (io.acceldata.hive.AdHiveHook)
- hive.exec.pre.hooks (io.acceldata.hive.AdHiveHook)
- Export the AUX_CLASSPATH=/opt/acceldata/ad-hook_HDP2-assembly-1.0.jar file. This file is present under hive-env template and hive-interactive-env template in hive service config.
Action items: You must add the ad.events.streaming.servers property under the Custom hive-site and Custom hive-interactive-site sections.
Acceldata Hive Hook for HDP3
Hook: Acceldata Hive Hook for HDP3
Binary: ad-hive-hook-HDP3-1.0.jar
Deployment: Place the above JAR file in the /opt/acceldata/ folder in HDFS node.
Configuration Steps:
- ad.events.streaming.servers (ad-events:4222)
- ad.cluster (your cluster name, ex: ad_hdp3_dev)
- hive.exec.failure.hooks (io.acceldata.hive.AdHiveHook)
- hive.exec.post.hooks (io.acceldata.hive.AdHiveHook)
- hive.exec.pre.hooks (io.acceldata.hive.AdHiveHook)
- Export the AUX_CLASSPATH=/opt/acceldata/ad-hook_HDP3-assembly-1.0.jar file. This file is present under hive-env template and hive-interactive-env template in hive service config.
Action items: You must add the ad.events.streaming.servers property under the Custom hive-site and Custom hive-interactive-site sections.
Acceldata Tez Hook for HDP2
Hook: Acceldata Tez Hook for HDP2
Binary: ad-tez-hook-HDP2-1.0.jar
Deployment: You must place the above JAR file in the tarball available in HDFS at /hdp/apps/2.6.5.0-292/tez/tez.tar.gz.
Configuration Steps:
- ad.events.streaming.servers (ad-events:4222)
- ad.cluster (your cluster name, ex: ad_hdp3_dev)
- tez.history.logging.service.class (io.acceldata.hive.AdTezEventsNatsClient)
Action items: You must add the ad.events.streaming.servers property under the Custom tez-site section.
Acceldata Tez Hook for HDP3
Hook: Acceldata Tez Hook for HDP3
Binary: ad-tez-hook-HDP3-1.0.jar
Deployment: You must place the above JAR file in the tarball available in HDFS at /hdp/apps/3.1.4.0-315/tez/tez.tar.gz.
Configuration Steps:
- ad.events.streaming.servers (ad-events:4222)
- ad.cluster (your cluster name, ex: ad_hdp3_dev)
- tez.history.logging.service.class (io.acceldata.hive.AdTezEventsNatsClient)
Action items: You must add the ad.events.streaming.servers property under the Custom tez-site section.
Acceldata Spark Hook HDP2
- Hook: Acceldata Spark Hook HDP2
- Binary: ad-spark-hook-HDP2-1.0.jar
- Deployment: You must place the above JAR file in the /opt/acceldata/ folder in HDFS node.
- Configuration Steps:
- spark.ad.events.streaming.servers (ad-events:4222)
- spark.ad.cluster (your cluster name, ex: ad_hdp3_dev)
- You must use this JAR during Spark job submission. The command to submit the JAR file is as follows.
/usr/bin/spark-submit --jars /opt/acceldata/ad-spark-hook-HDP2-1.0.jar- Action items:
- You must add the spark.ad.events.streaming.servers property under Custom spark2-defaults.
- You must modify the spark.extraListeners property. This property is located under the Advanced spark2-defaults. You must provide the value as io.acceldata.sparkhook.AdSparkHook.
Acceldata Spark Hook HDP3
- Hook: Acceldata Spark Hook HDP3
- Binary: ad-spark-hook-HDP3-1.0.jar
- Deployment: You must place the above JAR file in the /opt/acceldata/ folder in HDFS node.
- Configuration Steps:
- spark.ad.events.streaming.servers (ad-events:4222)
- spark.ad.cluster (your cluster name, ex: ad_hdp3_dev)
- You must use this JAR during Spark job submission. The command to submit the JAR file is as follows.
Connector Level Configurations
This section describes the configurations you must perform on various connector microservices for Pulse deployments.
Sparkstats
You must generate the required connectors YAML file, if not available. You can execute the following command to generate the YAML file.
accelo admin makeconfig ad-core-connectorsConfiguration for Sparkstats
You must configure the ad-core-connectors.yml file. To accomplish this, you must add the following environment variable under ad-sparkstats.
NATS_SERVER_HOST_LIST=ad-events:4222
YARN applications and Hive-queries
You must perform the following configuration in Pulse configurations, under individual collectors.
nats.server.host.list = "ad-events:4222" # You must use appropriate value for port number, applicable to your setup.New Dashplots Version and Generic Reporting Feature
- Splashboards and Dashplots are never automatically rewritten, so either delete that dashboard to acquire the new version, or set the environment variable
OVERWRITE_SPLASHBOARDSandOVERWRITE_DASHPLOTSto overwrite the existing splashboard dashboard with the newer version. - To access the most recent dashboard, delete the HDFS Analytics dashboard from splashboard studio and then refresh configuration.
- Navigate to
ad-core.yml. - In
graphql,set the environment variables ofOVERWRITE_SPLASHBOARDSandOVERWRITE_DASHPLOTStotrue(default value is set tofalse)
- Export all the dashplots which are not seeded by default to file before performing the upgradation.
- Login to the
ad-pg_defaultdocker container with the following command after the upgrade to 3.0.3.
docker exec -ti ad-pg_default bash- Copy, paste and execute the snippet attached in the migration file as is and press enter to execute it.
psql -v ON_ERROR_STOP=1 --username "pulse" <<-EOSQL \connect ad_management dashplot BEGIN;truncate table ad_management.dashplot_hierarchy cascade;truncate table ad_management.dashplot cascade;truncate table ad_management.dashplot_visualization cascade;truncate table ad_management.dashplot_variables cascade;INSERT INTO ad_management.dashplot_variables (stock_version,"name",definition,dashplot_id,dashplot_viz_id,"global") VALUES (1,'appid','{"_id": "1", "name": "appid", "type": "text", "query": "", "shared": true, "options": [], "separator": "", "description": "AppID to be provided for user customization", "defaultValue": "app-20210922153251-0000", "selectionType": "", "stock_version": 1}',NULL,NULL,true), (1,'appname','{"_id": "2", "name": "appname", "type": "text", "query": "", "shared": true, "options": [], "separator": "", "description": "", "defaultValue": "Databricks Shell", "selectionType": "", "stock_version": 1}',NULL,NULL,true), (1,'FROM_DATE_EPOC','{"id": 0, "_id": "3", "name": "FROM_DATE_EPOC", "type": "date", "query": "", "global": true, "shared": false, "options": [], "separator": "", "dashplot_id": null, "description": "", "displayName": "", "defaultValue": "1645641000000", "selectionType": "", "stock_version": 1, "dashplot_viz_id": null}',NULL,NULL,true), (1,'TO_DATE_EPOC','{"id": 0, "_id": "4", "name": "TO_DATE_EPOC", "type": "date", "query": "", "global": true, "shared": false, "options": [], "separator": "", "dashplot_id": null, "description": "", "displayName": "", "defaultValue": "1645727399000", "selectionType": "", "stock_version": 1, "dashplot_viz_id": null}',NULL,NULL,true), (1,'FROM_DATE_SEC','{"_id": "5", "name": "FROM_DATE_SEC", "type": "date", "query": "", "shared": true, "options": [], "separator": "", "defaultValue": "1619807400", "selectionType": ""}',NULL,NULL,true), (1,'TO_DATE_SEC','{"_id": "6", "name": "TO_DATE_SEC", "type": "date", "query": "", "shared": true, "options": [], "separator": "", "defaultValue": "1622477134", "selectionType": ""}',NULL,NULL,true), (1,'dbcluster','{"_id": "7", "name": "dbcluster", "type": "text", "query": "", "shared": true, "options": [], "separator": "", "description": "", "defaultValue": "job-4108-run-808", "selectionType": "", "stock_version": 1}',NULL,NULL,true), (1,'id','{"_id": "8", "name": "id", "type": "text", "query": "", "shared": true, "options": [], "separator": "", "defaultValue": "hive_20210906102708_dcd9df9d-91b8-421a-a70f-94beed03e749", "selectionType": ""}',NULL,NULL,true), (1,'dagid','{"_id": "9", "name": "dagid", "type": "text", "query": "", "shared": true, "options": [], "separator": "", "description": "", "defaultValue": "dag_1631531795196_0009_1", "selectionType": "", "stock_version": 1}',NULL,NULL,true), (1,'hivequeryid','{"_id": "10", "name": "hivequeryid", "type": "text", "query": "", "shared": true, "options": [], "separator": "", "defaultValue": "hive_20210912092701_cef246fa-cb3c-4130-aece-e6cac82751bd", "selectionType": ""}',NULL,NULL,true);INSERT INTO ad_management.dashplot_variables (stock_version,"name",definition,dashplot_id,dashplot_viz_id,"global") VALUES (1,'TENANT_NAME','{"_id": "11", "name": "TENANT_NAME", "type": "text", "query": "", "global": true, "shared": false, "options": [], "separator": "", "description": "", "defaultValue": "acceldata", "selectionType": "", "stock_version": 1}',NULL,NULL,true);COMMIT;EOSQL- Go to dashplot studio and import the zip file exported in step 1 of this section with
< 3.0.0 dashboardcheck box selected.
Troubleshooting
FSAnalytics Issue
Post upgrade after executing the fsa load command, incase if you encounter the following exception in fsanalytics connector execute the below steps to troubleshoot the issue.
22-11-2022 09:59:40.341 [fsanalytics-connector-akka.actor.default-dispatcher-1206] INFO c.a.p.f.metastore.MetaStoreMap - Cleared meta-store.dat[ERROR] [11/22/2022 09:59:40.342] [fsanalytics-connector-akka.actor.default-dispatcher-1206] [akka://fsanalytics-connector/user/$a] The file /etc/fsanalytics/hdp314/meta-store.dat the map is serialized from has unexpected length 0, probably corrupted. Data store size is 286023680java.io.IOException: The file /etc/fsanalytics/hdp314/meta-store.dat the map is serialized from has unexpected length 0, probably corrupted. Data store size is 286023680 at net.openhft.chronicle.map.ChronicleMapBuilder.openWithExistingFile(ChronicleMapBuilder.java:1800) at net.openhft.chronicle.map.ChronicleMapBuilder.createWithFile(ChronicleMapBuilder.java:1640) at net.openhft.chronicle.map.ChronicleMapBuilder.createPersistedTo(ChronicleMapBuilder.java:1563) at com.acceldata.plugins.fsanalytics.metastore.MetaStoreMap.getMap(MetaStoreConnection.scala:71) at com.acceldata.plugins.fsanalytics.metastore.MetaStoreMap.initialize(MetaStoreConnection.scala:42) at com.acceldata.plugins.fsanalytics.metastore.MetaStoreConnection.<init>(MetaStoreConnection.scala:111) at com.acceldata.plugins.fsanalytics.FsAnalyticsConnector.execute(FsAnalyticsConnector.scala:49) at com.acceldata.plugins.fsanalytics.FsAnalyticsConnector.execute(FsAnalyticsConnector.scala:17) at com.acceldata.connectors.core.SchedulerImpl.setUpOneShotSchedule(Scheduler.scala:48) at com.acceldata.connectors.core.SchedulerImpl.schedule(Scheduler.scala:64) at com.acceldata.connectors.core.DbListener$$anonfun$receive$1.$anonfun$applyOrElse$5(DbListener.scala:64) at com.acceldata.connectors.core.DbListener$$anonfun$receive$1.$anonfun$applyOrElse$5$adapted(DbListener.scala:54) at scala.collection.immutable.HashSet$HashSet1.foreach(HashSet.scala:320) at scala.collection.immutable.HashSet$HashTrieSet.foreach(HashSet.scala:976) at com.acceldata.connectors.core.DbListener$$anonfun$receive$1.applyOrElse(DbListener.scala:54) at akka.actor.Actor.aroundReceive(Actor.scala:539) at akka.actor.Actor.aroundReceive$(Actor.scala:537) at com.acceldata.connectors.core.DbListener.aroundReceive(DbListener.scala:26) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:614) at akka.actor.ActorCell.invoke(ActorCell.scala:583) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:268) at akka.dispatch.Mailbox.run(Mailbox.scala:229) at akka.dispatch.Mailbox.exec(Mailbox.scala:241) at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)Execute the following steps to resolve the above exception.
- Remove the
${ACCELOHOME}/data/fsanalytics/${ClusterName}/meta-store.datfile. - Restart the ad-fsanalytics container using the following command.
accelo restart ad-fsanalyticsv2-connector- Execute the following command to generate the meta store data again.
accelo admin fsa load