Rule Configuration and AI Assistance for Policies
ADOC V2.12.1 introduced a significant enhancement to how you create and execute Data quality (DQ) policies. This feature focuses on optimizing the execution of policies by loading only the necessary columns into the data frame, thus conserving memory and improving performance.
Rule Items and Column Loading
When you construct a DQ policy, you can specify rule elements like null checks, SQL rules, and length checks. Traditionally, while executing a policy, all data from the asset's table was loaded into the data frame, independent of the rule items' specific column needs. This method may cause significant memory utilization, particularly for tables with a large number of columns or data.
Optimized Column Selection
To remedy this, users can now pick only the columns required for policy execution. For example, if a policy specifies a null check on column one, the system will only load column one into the data frame, skipping all extraneous columns. This tailored method reduces needless data loading and related performance difficulties.
Creating User-Defined Transformations (UDTs)
During the creation of a UDT, users can select specific columns to be transformed. Only these selected columns will be loaded, avoiding the need to load the entire table. This selective approach is reflected in the UI where, upon adding a transformation and selecting columns, these columns will be automatically locked and deemed mandatory for loading. Additional columns will be pre-selected but can be deselected based on user preference.
Column Selection and Locking Mechanism
The UI now includes a feature where columns specified in transformations or rules are locked and loaded by default. Users have the flexibility to deselect other pre-selected columns. During validation, the system will consider only the columns that have been explicitly included by the user.
UI modifications to support the new column selection process:
- When you add transformations or rules, the UI automatically locks the corresponding columns.
- A column identification standard is implemented to ensure that only the required columns are loaded.
- Users can now validate and confirm which columns need to be loaded before saving the policy.
Execution on Selected Columns
At runtime, policies execute by loading only the columns that were selected during policy creation. If a policy includes a null check for a specific column, only that column is involved in the execution. This selective strategy extends to all rule items, including UDTs, UDFs, and SQL rules.
Persisted Columns refers to the columns that users wish to monitor post-execution, which may include columns not directly involved in any rule but are important for context, such as IDs in good/bad record analysis. These can be additionally selected to appear in the final output.
Execution Details and SQL Filters
Execution details provide insight into the success of the policy and the number of rows scanned. Additionally, a feature exists for applying SQL filters, which allows policies to execute based on specific row conditions, such as a column value match. This feature operates alongside the column selection optimization.
Generative AI Assisted Functionalities
Utilizing the Generative AI Assisted Text to Rules Functionality
The Generative AI Assisted Text to Rules functionality in ADOC streamlines the process of defining data quality rules, allowing you to leverage natural language to quickly establish rules across your datasets. Here’s how to make the most of this innovative feature.
Manually crafting data quality rules for large datasets can be daunting due to the sheer number of columns and the complexity of the data involved. Our Text to Rules functionality simplifies this process by enabling rule creation using straightforward natural language inputs.
Supported Rule Definitions
With Text to Rules, you can effortlessly define a variety of data quality checks, including:
| Rule Type | Description |
|---|---|
| Null Check | Verify the absence of null values in a column. |
| Schema Match (Primitive Data Types) | Ensure column data matches specific primitive types (integer, string). |
| Pattern Match | Validate data patterns within columns, using regular expressions for structured data like email addresses. |
| Range Match | Define rules to restrict column values within a specified range. |
| Enumerations | Set rules to limit column values to a predefined list, ensuring data consistency. |
| Row Check | Apply custom logic to your data quality checks using Text to SQL functionality for more complex validations. |
| Duplicate Row Check | Easily identify and manage rows with identical data across selected columns. |
| Tags Match | Verifies that data tags are consistent with the defined criteria. |
| Uniqueness Check | Ensures that values in specified columns are unique within the dataset. |
Examples
| Rule Type | Rule Description | Generated Rule |
|---|---|---|
| Null Checks | Perform a null check on CC_CALL_CENTER_SK (weight 90) and CC_CLASS (weight 100). |
|
| Duplicate Checks |
|
|
| Enumeration Validation | Validate the CC_STATE column to only contain a list of states with their short forms from the United States of America. | Enumerations rule for CC_STATE with values as state abbreviations of the USA. |
| Schema Checks | Apply integer schema check on columns tagged as @Integral. | Schema match rule for all columns identified as Integer datatype in profiled assets. |
While Text to Rules offers broad capabilities, there are certain limitations to be aware of:
- 'Except' Use Case: The ability to apply rules to all columns except specified ones (e.g., all except name and id) is not actively supported.
- Row level operations: It is currently not supported in Text to Rules. Instead use Text to SQL.
How to Use Text to Rules
- Accessing Text to Rules: Navigate to the Data Quality Policy section in ADOC and select the option to create a new rule via Text to Rules.
- Entering Rule Definitions: Type your rule definition in natural language. For instance, "Verify that the column ‘CustomerID’ contains no null values" would automatically generate a Null Check rule for that column.
- Refining Your Inputs: Use the "@" symbol to specify columns and ensure clarity in your rule definition to avoid any potential misinterpretation by the AI.
- Clear Rule Definition: "Perform a null check on ‘Email’ and ‘Phone Number’ columns" generates Null Check rules for both columns.
- Enumerations: "Ensure ‘State’ column contains only US state abbreviations" will create an Enumeration rule for the ‘State’ column with a predefined list of US state abbreviations.
- Using @ Symbol: Always use "@" to select columns directly, such as "@Email" for specifying the Email column.
Tips for Success
- For datatype-based rules, ensure your asset is profiled. This allows the functionality to accurately generate schema match rules based on column datatypes.
- In case of regex/pattern match rules, use the "Escape regex" keyword for complex patterns to ensure accuracy.
- Providing detailed context in your rule definitions helps the AI in generating precise and applicable rules.
Utilizing the Generative AI Assisted SQL Validation and Correction Feature
Creating data quality rules is a fundamental task in maintaining the integrity of data within ADOC. Traditionally, users define these rules through the UI, which, while effective, can become cumbersome with an increasing number of rules. Recognizing this challenge, ADOC introduces the GenAI Assisted SQL Validation and Correction feature to streamline this process. This feature allows users to articulate their rules in simple English, which ADOC then converts into the corresponding SQL statements.
The primary goal of this feature is to simplify the rule creation process, making it more accessible and efficient, especially for users unfamiliar with SQL syntax or those looking to expedite the rule configuration process.
How to Use AI Assisted SQL Validation

| Steps | Function | Description |
|---|---|---|
| 1 | Rule Description | Users input the desired rule in plain English text. |
| 2 | Automatic Conversion | Utilizing advanced GPT technology, ADOC automatically translates the text input into the equivalent SQL. |
| 3 | SQL Validation | The system performs an automatic syntax check on the generated SQL to ensure accuracy and optimality. |
| 4 | User Review and Validation | Users have the opportunity to review the generated SQL. If it meets their requirements, they can proceed to save and deploy it. |
- Users should describe their intended rules in clear, concise English.
- It is crucial to review the automatically generated SQL for accuracy and intended functionality.
AI Assistant
The capabilities of the generative AI assistance have been improved. There is now an AI assistant available to aid in articulating data quality rules or SQL rules.
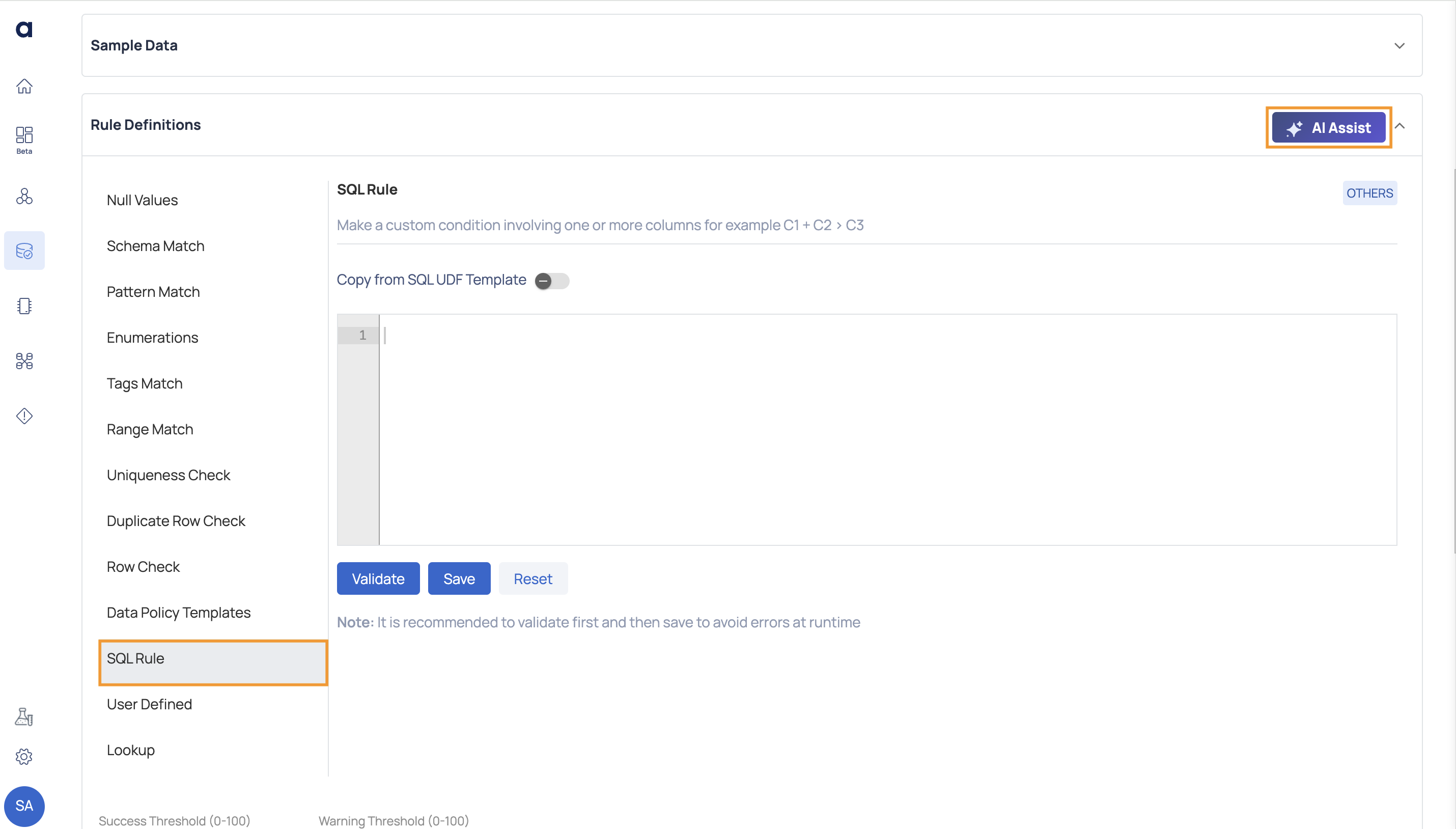
Describe the data quality rule or the SQL rule in plain English. When you type the @ symbol, it offers column suggestions.

The rule is configured based on selected policy. You can choose to apply it or generate a new rule as needed.
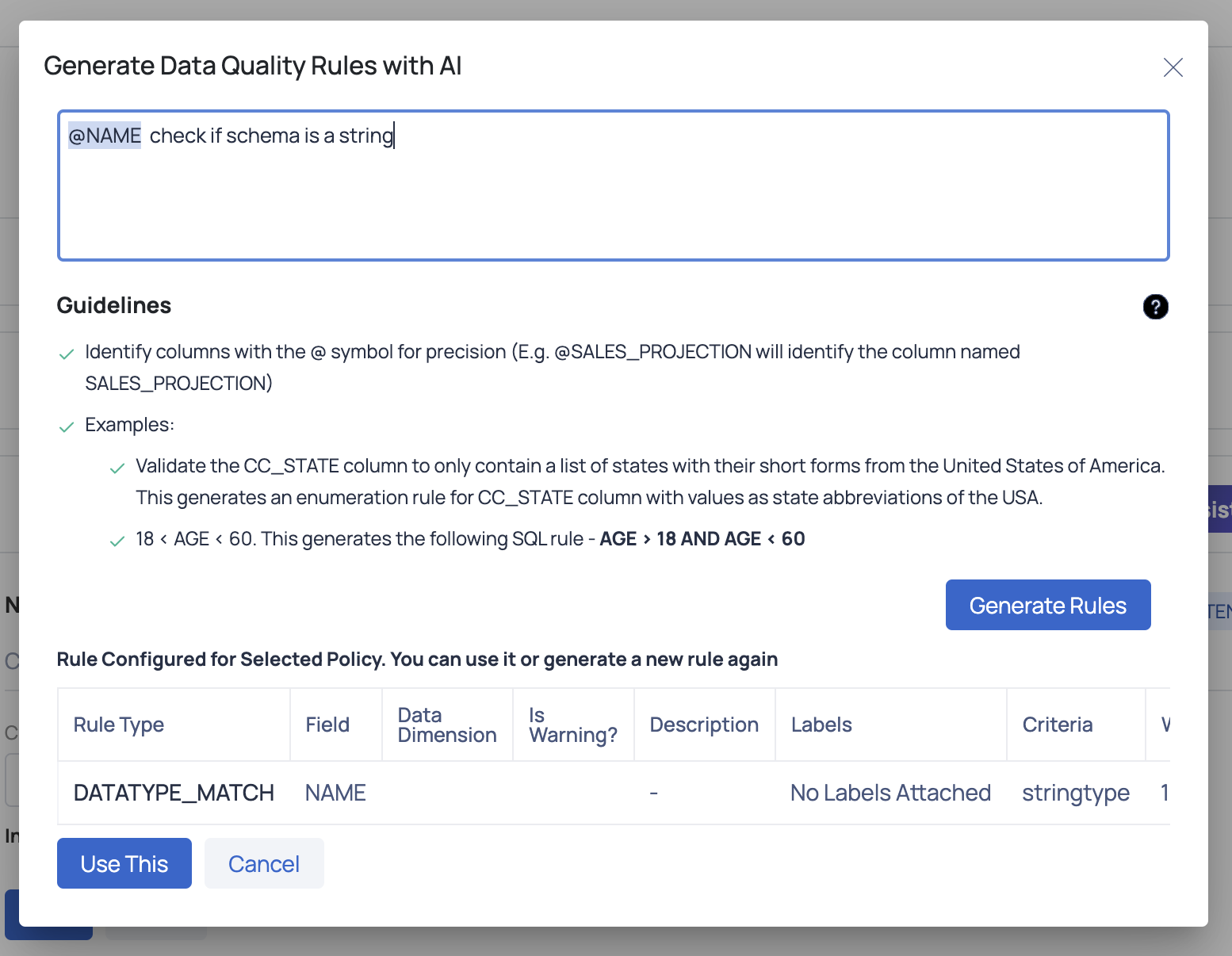
Click the Use this button to configure the selected rule for the policy.

Example Rules and their SQL Equivalents
Validation SQL Examples
| Validations | English | SQL |
|---|---|---|
| Date Format Validation | Validate whether the date column is in 'yyyy-MM-dd' format. | SELECT regexp_like(date, '^[0-9]{4}-[0-9]{2}-[0-9]{2}$') |
| Positive Age Check | Validate “age” column to have positive values. | SELECT age > 0 |
Best Practices
- Clarity in Description: Ensure the rule description in English is as clear and detailed as possible to generate accurate SQL statements.
- Review Generated SQL: Always review the generated SQL for accuracy and modify if necessary before saving and deploying.
- Use Cases: Leverage this feature for a wide range of validation and transformation rules to streamline data quality processes.
- Complex SQL transformations or validations that require understanding of context beyond the rule description may not be fully captured.
- Certain SQL functionalities, especially those requiring deep database schema knowledge, might need manual adjustments.
Generate Auto Tags
The features introduced in ADOC V3.4.0, enhances data quality management across enterprise data assets through automated data tagging and domain identification.
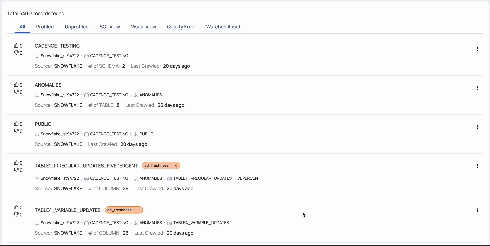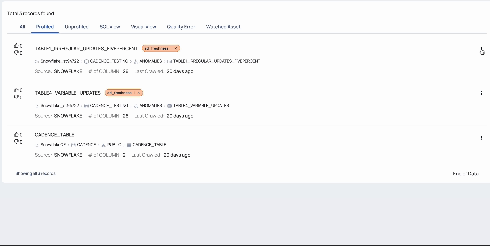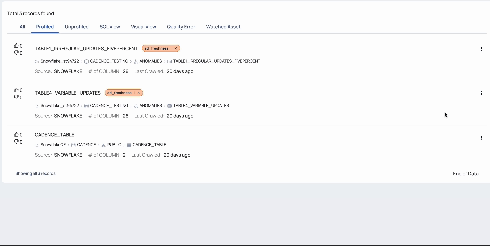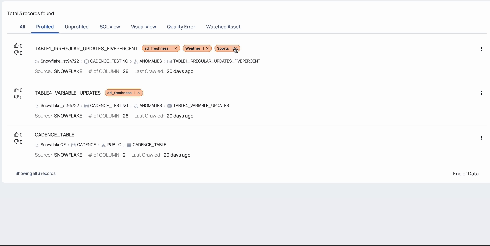
Automated Data Tagging
Automatically extracts the most common values from each column, utilizing existing control plane functionalities.
Supported Tags
Generate Auto Description
The Generative AI for Metadata Generation feature in ADOC V3.4.0 automates the creation of metadata descriptions for tables and columns. This enhancement facilitates better asset discovery and explainability, streamlining data management processes.
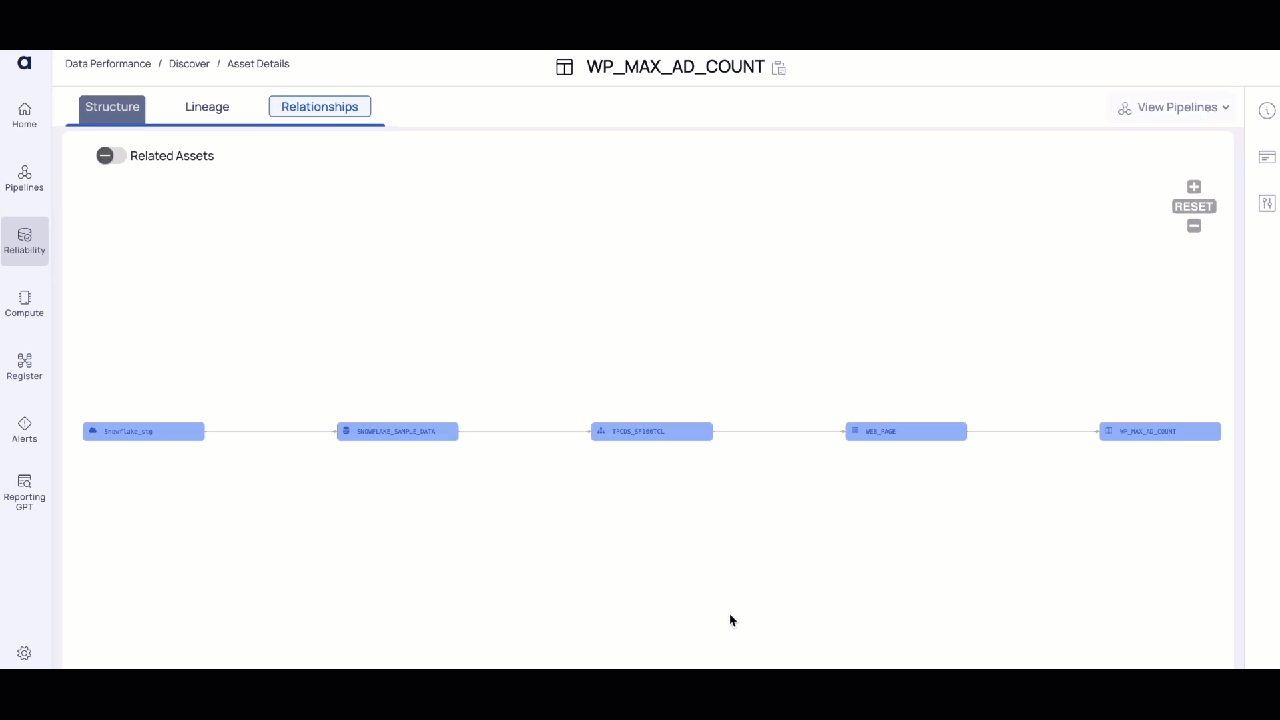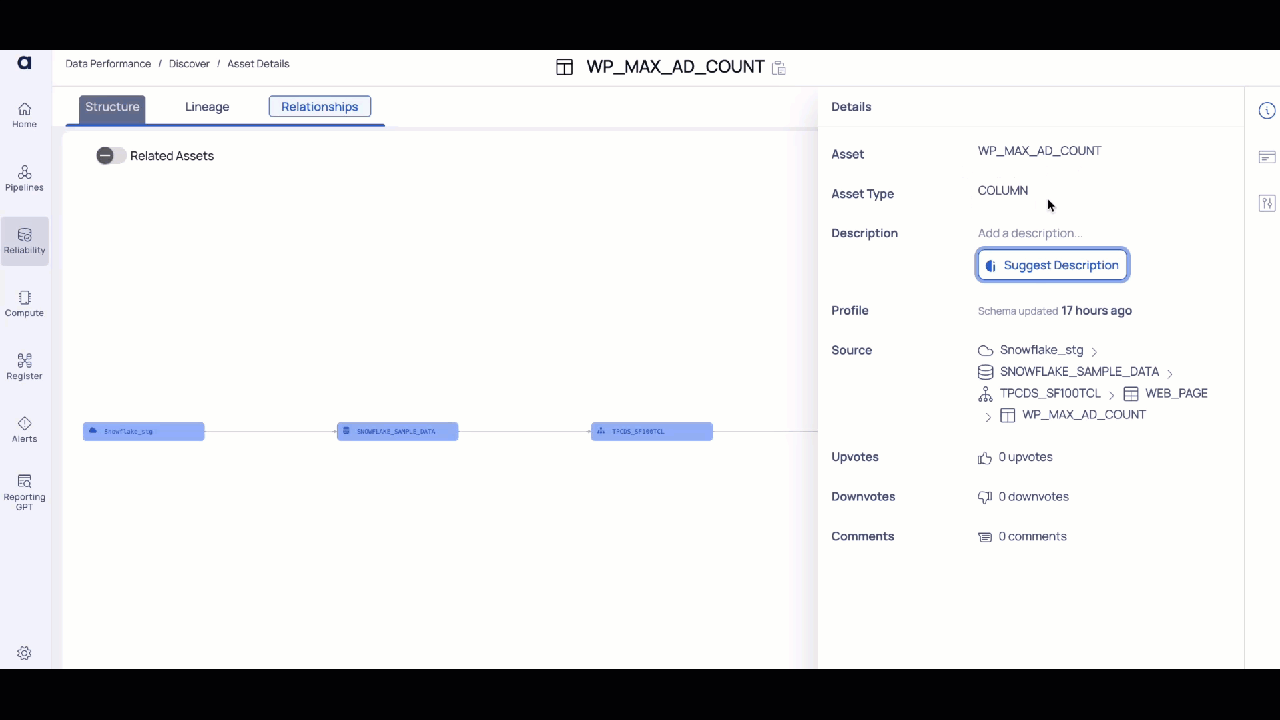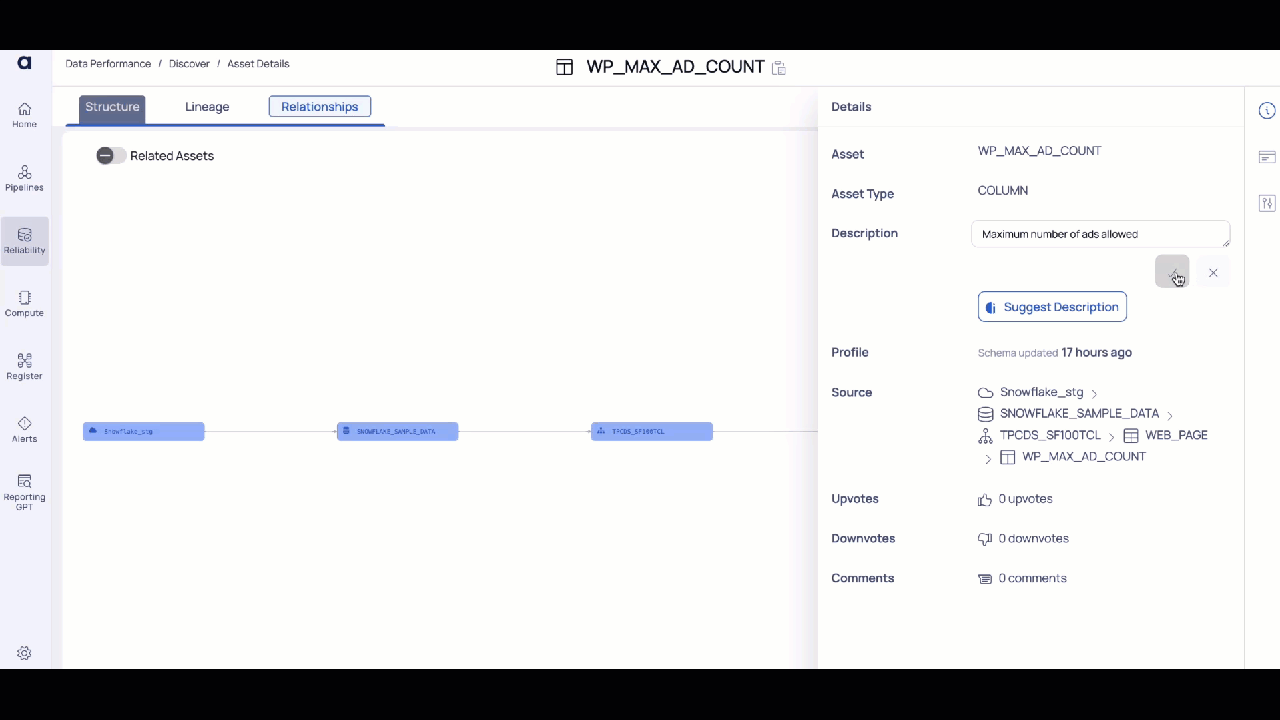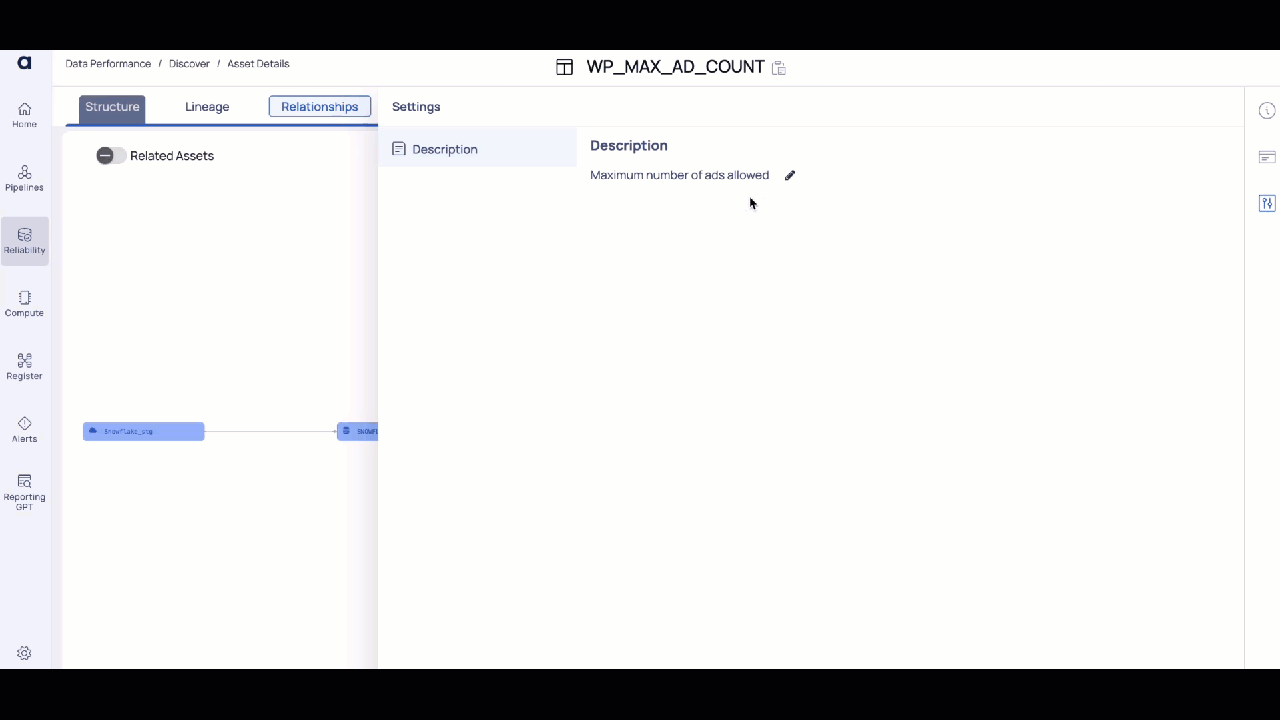
Column Level Description

Table Level Description
- Navigate to the Data Discovery section in the Reliability.
- Select the Table or Column level asset type.
- Navigate to the Details icon on the right side menu.
- Click on the Suggest Description button. The AI assesses column data or table contents and provides an appropriate description.
- Review the AI-generated metadata for accuracy and relevance. Make edits if necessary to tailor the descriptions to your organizational standards.
- Once reviewed, approve the metadata to be associated with the data assets. The metadata is then integrated into your data catalog for enhanced asset discovery.
This feature employs advanced AI algorithms to analyze your data assets and generate descriptive metadata automatically. It improves the discoverability and understandability of data assets, facilitating data governance and usage.