Start the ODP Stack Services
Start All Services Manually
Once the Ambari upgrade is done, start all the services manually and make sure it all started.
JDK 11 Env Changes
The following flags must be added after upgrading Infra-Solr, Hadoop, HBase, Hive, and Druid env files, before starting the services in a JDK11 environment.
Hadoop-env
The Java 11 flags have been addressed in the ${else} block, which needs to be updated after the upgrade is completed during the service start process.
File location: Log on to the Ambari UI → HDFS → configs → Advanced -> Advanced hadoop-env -> hadoop-env template.
# # Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # Set Hadoop-specific environment variables here. ## ## THIS FILE ACTS AS THE MASTER FILE FOR ALL HADOOP PROJECTS. ## SETTINGS HERE WILL BE READ BY ALL HADOOP COMMANDS. THEREFORE, ## ONE CAN USE THIS FILE TO SET YARN, HDFS, AND MAPREDUCE ## CONFIGURATION OPTIONS INSTEAD OF xxx-env.sh. ## ## Precedence rules: ## ## {yarn-env.sh|hdfs-env.sh} > hadoop-env.sh > hard-coded defaults ## ## {YARN_xyz|HDFS_xyz} > HADOOP_xyz > hard-coded defaults ## # Many of the options here are built from the perspective that users # may want to provide OVERWRITING values on the command line. # For example: # # JAVA_HOME=/usr/java/testing hdfs dfs -ls # # Therefore, the vast majority (BUT NOT ALL!) of these defaults # are configured for substitution and not append. If append # is preferable, modify this file accordingly. # Technically, the only required environment variable is JAVA_HOME. # All others are optional. However, the defaults are probably not # preferred. Many sites configure these options outside of Hadoop, # such as in /etc/profile.d # The java implementation to use. By default, this environment # variable is REQUIRED on ALL platforms except OS X! export JAVA_HOME={{java_home}} # Location of Hadoop. By default, Hadoop will attempt to determine # this location based upon its execution path. export HADOOP_HOME=${HADOOP_HOME:-{{hadoop_home}}} # # Out of the box, Hadoop uses jsvc from Apache Commons to launch daemons # on privileged ports. This functionality can be replaced by providing # custom functions. See hadoop-functions.sh for more information. # # The jsvc implementation to use. Jsvc is required to run secure datanodes # that bind to privileged ports to provide authentication of data transfer # protocol. Jsvc is not required if SASL is configured for authentication of # data transfer protocol using non-privileged ports. export JSVC_HOME={{jsvc_path}} # Location of Hadoop's configuration information. i.e., where this # file is living. If this is not defined, Hadoop will attempt to # locate it based upon its execution path. # # NOTE: It is recommend that this variable not be set here but in # /etc/profile.d or equivalent. Some options (such as # --config) may react strangely otherwise. # export HADOOP_CONF_DIR={{hadoop_conf_dir}} # The maximum amount of heap to use (Java -Xmx). If no unit # is provided, it will be converted to MB. Daemons will # prefer any Xmx setting in their respective _OPT variable. # There is no default; the JVM will autoscale based upon machine # memory size. export HADOOP_HEAPSIZE={{hadoop_heapsize}} export HADOOP_NAMENODE_HEAPSIZE={{namenode_heapsize}} # Enable extra debugging of Hadoop's JAAS binding, used to set up # Kerberos security. # export HADOOP_JAAS_DEBUG=true # Extra Java runtime options for all Hadoop commands. We don't support # IPv6 yet/still, so by default the preference is set to IPv4. # export HADOOP_OPTS="-Djava.net.preferIPv4Stack=true" # For Kerberos debugging, an extended option set logs more information # export HADOOP_OPTS="-Djava.net.preferIPv4Stack=true -Dsun.security.krb5.debug=true -Dsun.security.spnego.debug" export HADOOP_OPTS="-Djava.net.preferIPv4Stack=true ${HADOOP_OPTS}" USER="$(whoami)" # Some parts of the shell code may do special things dependent upon # the operating system. We have to set this here. See the next # section as to why.... export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)} {% if java_version < 8 %} SHARED_HDFS_NAMENODE_OPTS="-server -XX:ParallelGCThreads=8 -XX:+UseConcMarkSweepGC -XX:ErrorFile={{hdfs_log_dir_prefix}}/$USER/hs_err_pid%p.log -XX:NewSize={{namenode_opt_newsize}} -XX:MaxNewSize={{namenode_opt_maxnewsize}} -XX:PermSize={{namenode_opt_permsize}} -XX:MaxPermSize={{namenode_opt_maxpermsize}} -Xloggc:{{hdfs_log_dir_prefix}}/$USER/gc.log-`date +'%Y%m%d%H%M'` -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -Xms$HADOOP_NAMENODE_HEAPSIZE -Xmx$HADOOP_NAMENODE_HEAPSIZE -Dhadoop.security.logger=INFO,DRFAS -Dhdfs.audit.logger=INFO,DRFAAUDIT" export HDFS_NAMENODE_OPTS="${SHARED_HDFS_NAMENODE_OPTS} -XX:OnOutOfMemoryError=\"/usr/odp/current/hadoop-hdfs-namenode/bin/kill-name-node\" -Dorg.mortbay.jetty.Request.maxFormContentSize=-1 ${HDFS_NAMENODE_OPTS}" export HDFS_DATANODE_OPTS="-server -XX:ParallelGCThreads=4 -XX:+UseConcMarkSweepGC -XX:OnOutOfMemoryError=\"/usr/odp/current/hadoop-hdfs-datanode/bin/kill-data-node\" -XX:ErrorFile=/var/log/hadoop/$USER/hs_err_pid%p.log -XX:NewSize=200m -XX:MaxNewSize=200m -XX:PermSize=128m -XX:MaxPermSize=256m -Xloggc:/var/log/hadoop/$USER/gc.log-`date +'%Y%m%d%H%M'` -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xms{{dtnode_heapsize}} -Xmx{{dtnode_heapsize}} -Dhadoop.security.logger=INFO,DRFAS -Dhdfs.audit.logger=INFO,DRFAAUDIT ${HDFS_DATANODE_OPTS} -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly" export HDFS_SECONDARYNAMENODE_OPTS="${SHARED_HDFS_NAMENODE_OPTS} -XX:OnOutOfMemoryError=\"/usr/odp/current/hadoop-hdfs-secondarynamenode/bin/kill-secondary-name-node\" ${HDFS_SECONDARYNAMENODE_OPTS}" # The following applies to multiple commands (fs, dfs, fsck, distcp etc) export HADOOP_CLIENT_OPTS="-Xmx${HADOOP_HEAPSIZE}m -XX:MaxPermSize=512m $HADOOP_CLIENT_OPTS" {% elif java_version == 8 %} SHARED_HDFS_NAMENODE_OPTS="-server -XX:ParallelGCThreads=8 -XX:+UseG1GC -XX:ErrorFile={{hdfs_log_dir_prefix}}/$USER/hs_err_pid%p.log -XX:NewSize={{namenode_opt_newsize}} -XX:MaxNewSize={{namenode_opt_maxnewsize}} -Xloggc:{{hdfs_log_dir_prefix}}/$USER/gc.log-`date +'%Y%m%d%H%M'` -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:InitiatingHeapOccupancyPercent=70 -Xms$HADOOP_NAMENODE_HEAPSIZE -Xmx$HADOOP_NAMENODE_HEAPSIZE -Dhadoop.security.logger=INFO,DRFAS -Dhdfs.audit.logger=INFO,DRFAAUDIT" export HDFS_NAMENODE_OPTS="${SHARED_HDFS_NAMENODE_OPTS} -XX:OnOutOfMemoryError=\"/usr/odp/current/hadoop-hdfs-namenode/bin/kill-name-node\" -Dorg.mortbay.jetty.Request.maxFormContentSize=-1 ${HDFS_NAMENODE_OPTS}" export HDFS_DATANODE_OPTS="-server -XX:ParallelGCThreads=4 -XX:+UseG1GC -XX:OnOutOfMemoryError=\"/usr/odp/current/hadoop-hdfs-datanode/bin/kill-data-node\" -XX:ErrorFile=/var/log/hadoop/$USER/hs_err_pid%p.log -XX:NewSize=200m -XX:MaxNewSize=200m -Xloggc:/var/log/hadoop/$USER/gc.log-`date +'%Y%m%d%H%M'` -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xms{{dtnode_heapsize}} -Xmx{{dtnode_heapsize}} -Dhadoop.security.logger=INFO,DRFAS -Dhdfs.audit.logger=INFO,DRFAAUDIT ${HDFS_DATANODE_OPTS} -XX:InitiatingHeapOccupancyPercent=70" export HDFS_SECONDARYNAMENODE_OPTS="${SHARED_HDFS_NAMENODE_OPTS} -XX:OnOutOfMemoryError=\"/usr/odp/current/hadoop-hdfs-secondarynamenode/bin/kill-secondary-name-node\" ${HDFS_SECONDARYNAMENODE_OPTS}" # The following applies to multiple commands (fs, dfs, fsck, distcp etc) export HADOOP_CLIENT_OPTS="-Xmx${HADOOP_HEAPSIZE}m $HADOOP_CLIENT_OPTS" {% else %} SHARED_HDFS_NAMENODE_OPTS="-server -XX:ParallelGCThreads=8 -XX:+UseG1GC -XX:ErrorFile={{hdfs_log_dir_prefix}}/$USER/hs_err_pid%p.log -XX:NewSize={{namenode_opt_newsize}} -XX:MaxNewSize={{namenode_opt_maxnewsize}} -Xlog:gc*,gc+heap=debug,gc+phases=debug:file={{hdfs_log_dir_prefix}}/$USER/gc.log-`date +'%Y%m%d%H%M'`:time,level,tags -XX:InitiatingHeapOccupancyPercent=70 -Xms$HADOOP_NAMENODE_HEAPSIZE -Xmx$HADOOP_NAMENODE_HEAPSIZE -Dhadoop.security.logger=INFO,DRFAS -Dhdfs.audit.logger=INFO,DRFAAUDIT" export HDFS_NAMENODE_OPTS="${SHARED_HDFS_NAMENODE_OPTS} -XX:OnOutOfMemoryError=\"/usr/odp/current/hadoop-hdfs-namenode/bin/kill-name-node\" -Dorg.mortbay.jetty.Request.maxFormContentSize=-1 ${HDFS_NAMENODE_OPTS}" export HDFS_DATANODE_OPTS="-server -XX:OnOutOfMemoryError=\"/usr/odp/current/hadoop-hdfs-datanode/bin/kill-data-node\" -XX:ErrorFile=/var/log/hadoop/$USER/hs_err_pid%p.log -verbose:gc -Xms{{dtnode_heapsize}} -Xmx{{dtnode_heapsize}} -Dhadoop.security.logger=INFO,DRFAS -Dhdfs.audit.logger=INFO,DRFAAUDIT ${HDFS_DATANODE_OPTS} " export HDFS_SECONDARYNAMENODE_OPTS="${SHARED_HDFS_NAMENODE_OPTS} -XX:OnOutOfMemoryError=\"/usr/odp/current/hadoop-hdfs-secondarynamenode/bin/kill-secondary-name-node\" ${HDFS_SECONDARYNAMENODE_OPTS}" # The following applies to multiple commands (fs, dfs, fsck, distcp etc) export HADOOP_CLIENT_OPTS="-Xmx${HADOOP_HEAPSIZE}m $HADOOP_CLIENT_OPTS" {% endif %} {% if security_enabled %} export HDFS_NAMENODE_OPTS="$HDFS_NAMENODE_OPTS -Djava.security.auth.login.config={{hadoop_conf_dir}}/hdfs_nn_jaas.conf -Djavax.security.auth.useSubjectCredsOnly=false" ### # SecondaryNameNode specific parameters ### # Specify the JVM options to be used when starting the SecondaryNameNode. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # # This is the default: export HDFS_SECONDARYNAMENODE_OPTS="$HDFS_SECONDARYNAMENODE_OPTS -Djava.security.auth.login.config={{hadoop_conf_dir}}/hdfs_nn_jaas.conf -Djavax.security.auth.useSubjectCredsOnly=false" ### # DataNode specific parameters ### # Specify the JVM options to be used when starting the DataNode. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # # This is the default: export HDFS_DATANODE_OPTS="$HDFS_DATANODE_OPTS -Djava.security.auth.login.config={{hadoop_conf_dir}}/hdfs_dn_jaas.conf -Djavax.security.auth.useSubjectCredsOnly=false" ### # QuorumJournalNode specific parameters ### # Specify the JVM options to be used when starting the QuorumJournalNode. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # export HDFS_JOURNALNODE_OPTS="$HADOOP_JOURNALNODE_OPTS -Djava.security.auth.login.config={{hadoop_conf_dir}}/hdfs_jn_jaas.conf -Djavax.security.auth.useSubjectCredsOnly=false" {% endif %} ### # NFS3 Gateway specific parameters ### # Specify the JVM options to be used when starting the NFS3 Gateway. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # export HDFS_NFS3_OPTS="-Xmx{{nfsgateway_heapsize}}m -Dhadoop.security.logger=ERROR,DRFAS ${HDFS_NFS3_OPTS}" ### # HDFS Balancer specific parameters ### # Specify the JVM options to be used when starting the HDFS Balancer. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # export HDFS_BALANCER_OPTS="-server -Xmx{{hadoop_heapsize}}m ${HADOOP_BALANCER_OPTS}" # Should HADOOP_CLASSPATH be first in the official CLASSPATH? # export HADOOP_USER_CLASSPATH_FIRST="yes" # If HADOOP_USE_CLIENT_CLASSLOADER is set, the classpath along # with the main jar are handled by a separate isolated # client classloader when 'hadoop jar', 'yarn jar', or 'mapred job' # is utilized. If it is set, HADOOP_CLASSPATH and # HADOOP_USER_CLASSPATH_FIRST are ignored. # export HADOOP_USE_CLIENT_CLASSLOADER=true # HADOOP_CLIENT_CLASSLOADER_SYSTEM_CLASSES overrides the default definition of # system classes for the client classloader when HADOOP_USE_CLIENT_CLASSLOADER # is enabled. Names ending in '.' (period) are treated as package names, and # names starting with a '-' are treated as negative matches. For example, # export HADOOP_CLIENT_CLASSLOADER_SYSTEM_CLASSES="-org.apache.hadoop.UserClass,java.,javax.,org.apache.hadoop." # Enable optional, bundled Hadoop features # This is a comma delimited list. It may NOT be overridden via .hadooprc # Entries may be added/removed as needed. # export HADOOP_OPTIONAL_TOOLS="@@@HADOOP_OPTIONAL_TOOLS@@@" # On secure datanodes, user to run the datanode as after dropping privileges export HDFS_DATANODE_SECURE_USER=${HDFS_DATANODE_SECURE_USER:-{{hadoop_secure_dn_user}}} ### # Options for remote shell connectivity ### # There are some optional components of hadoop that allow for # command and control of remote hosts. For example, # start-dfs.sh will attempt to bring up all NNs, DNS, etc. # Options to pass to SSH when one of the "log into a host and # start/stop daemons" scripts is executed export HADOOP_SSH_OPTS="-o BatchMode=yes -o SendEnv=HADOOP_CONF_DIR -o StrictHostKeyChecking=no -o ConnectTimeout=10s" # The built-in ssh handler will limit itself to 10 simultaneous connections. # For pdsh users, this sets the fanout size ( -f ) # Change this to increase/decrease as necessary. # export HADOOP_SSH_PARALLEL=10 # Filename which contains all of the hosts for any remote execution # helper scripts # such as workers.sh, start-dfs.sh, etc. # export HADOOP_WORKERS="${HADOOP_CONF_DIR}/workers" ### # Options for all daemons ### # # # Many options may also be specified as Java properties. It is # very common, and in many cases, desirable, to hard-set these # in daemon _OPTS variables. Where applicable, the appropriate # Java property is also identified. Note that many are re-used # or set differently in certain contexts (e.g., secure vs # non-secure) # # Where (primarily) daemon log files are stored. # ${HADOOP_HOME}/logs by default. # Java property: hadoop.log.dir # Where log files are stored. $HADOOP_HOME/logs by default. export HADOOP_LOG_DIR={{hdfs_log_dir_prefix}}/$USER # How many seconds to pause after stopping a daemon # export HADOOP_STOP_TIMEOUT=5 # Where pid files are stored. /tmp by default. export HADOOP_PID_DIR={{hadoop_pid_dir_prefix}}/$USER ### # Secure/privileged execution ### # # This directory contains pids for secure and privileged processes. export HADOOP_SECURE_PID_DIR=${HADOOP_SECURE_PID_DIR:-{{hadoop_pid_dir_prefix}}/$HDFS_DATANODE_SECURE_USER} # # This directory contains the logs for secure and privileged processes. # Java property: hadoop.log.dir export HADOOP_SECURE_LOG=${HADOOP_SECURE_LOG:-{{hdfs_log_dir_prefix}}/$HDFS_DATANODE_SECURE_USER} YARN_RESOURCEMANAGER_OPTS="-Dyarn.server.resourcemanager.appsummary.logger=INFO,RMSUMMARY" # # When running a secure daemon, the default value of HADOOP_IDENT_STRING # ends up being a bit bogus. Therefore, by default, the code will # replace HADOOP_IDENT_STRING with HADOOP_xx_SECURE_USER. If one wants # to keep HADOOP_IDENT_STRING untouched, then uncomment this line. # export HADOOP_SECURE_IDENT_PRESERVE="true" # A string representing this instance of hadoop. $USER by default. # This is used in writing log and pid files, so keep that in mind! # Java property: hadoop.id.str export HADOOP_IDENT_STRING=$USER # Add database libraries JAVA_JDBC_LIBS="" if [ -d "/usr/share/java" ]; then for jarFile in `ls /usr/share/java | grep -E "(mysql|ojdbc|postgresql|sqljdbc)" 2>/dev/null` do JAVA_JDBC_LIBS=${JAVA_JDBC_LIBS}:$jarFile done fi # Add libraries to the hadoop classpath - some may not need a colon as they already include it export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}${JAVA_JDBC_LIBS} # Setting path to hdfs command line export HADOOP_LIBEXEC_DIR={{hadoop_libexec_dir}} # Mostly required for hadoop 2.0 export JAVA_LIBRARY_PATH=${JAVA_LIBRARY_PATH}:{{hadoop_lib_home}}/native/Linux-{{architecture}}-64 {% if zk_principal_user is defined %} HADOOP_OPTS="-Dzookeeper.sasl.client.username={{zk_principal_user}} $HADOOP_OPTS" {% endif %} export HADOOP_OPTS="-Dodp.version=$ODP_VERSION $HADOOP_OPTS" # Fix temporary bug, when ulimit from conf files is not picked up, without full relogin. # Makes sense to fix only when runing DN as root if [ "$command" == "datanode" ] && [ "$EUID" -eq 0 ] && [ -n "$HDFS_DATANODE_SECURE_USER" ]; then {% if is_datanode_max_locked_memory_set %} ulimit -l {{datanode_max_locked_memory}} {% endif %} ulimit -n {{hdfs_user_nofile_limit}} fi ### # ZKFailoverController specific parameters ### # Specify the JVM options to be used when starting the ZKFailoverController. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # # Enable ACLs on zookeper znodes if required {% if hadoop_zkfc_opts is defined %} export HDFS_ZKFC_OPTS="{{hadoop_zkfc_opts}} $HDFS_ZKFC_OPTS" {% endif %} ### # HDFS Mover specific parameters ### # Specify the JVM options to be used when starting the HDFS Mover. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # # export HDFS_MOVER_OPTS="" ### # Router-based HDFS Federation specific parameters # Specify the JVM options to be used when starting the RBF Routers. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # # export HDFS_DFSROUTER_OPTS="" ### # HDFS StorageContainerManager specific parameters ### # Specify the JVM options to be used when starting the HDFS Storage Container Manager. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # # export HDFS_STORAGECONTAINERMANAGER_OPTS="" ### # Advanced Users Only! ### # # When building Hadoop, one can add the class paths to the commands # via this special env var: # export HADOOP_ENABLE_BUILD_PATHS="true" # # To prevent accidents, shell commands be (superficially) locked # to only allow certain users to execute certain subcommands. # It uses the format of (command)_(subcommand)_USER. # # For example, to limit who can execute the namenode command, # export HDFS_NAMENODE_USER=hdfsYARN-env
Update 1
Update the YARN Java 11 flags as shown below.
File location: Log into the Ambari UI and navigate to YARN → Configs → Advanced→ Advanced yarn-hbase-env → hbase-env template.
export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:{{yarn_hbase_log_dir}}/gc.log-`date +'%Y%m%d%H%M'`"Replace it with the updated code block below.
{% if java_version == 8 %} # For Java 8 export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:{{yarn_hbase_log_dir}}/gc.log-`date +'%Y%m%d%H%M'`" {% else %} # For Java 11 and above export SERVER_GC_OPTS="-Xlog:gc*,gc+heap=debug,gc+phases=debug:file={{yarn_hbase_log_dir}}/gc.log-`date +'%Y%m%d%H%M'`:time,level,tags" {% endif %}Update 2
Update the YARN Java 11 flags as shown below.
File Location: Log into the Ambari UI and navigate to YARN → Configs → Advanced → Advanced yarn-hbase-env → hbase-env template.
export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC -XX:ErrorFile=$HBASE_LOG_DIR/hs_err_pid%p.log -Djava.io.tmpdir={{yarn_hbase_java_io_tmpdir}}"export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xmx{{yarn_hbase_master_heapsize}} $JDK_DEPENDED_OPTS"export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:CMSInitiatingOccupancyFraction=70 -XX:ReservedCodeCacheSize=256m -Xms{{yarn_hbase_regionserver_heapsize}} -Xmx{{yarn_hbase_regionserver_heapsize}} $JDK_DEPENDED_OPTS"Replace it with the updated code block below.
{% if java_version == 8 %} # For Java 8 export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC -XX:ErrorFile=$HBASE_LOG_DIR/hs_err_pid%p.log -Djava.io.tmpdir={{yarn_hbase_java_io_tmpdir}}" export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:CMSInitiatingOccupancyFraction=70 -XX:ReservedCodeCacheSize=256m -Xms{{yarn_hbase_regionserver_heapsize}} -Xmx{{yarn_hbase_regionserver_heapsize}} $JDK_DEPENDED_OPTS" {% else %} # For Java 11 and above export HBASE_OPTS="$HBASE_OPTS -XX:+UseG1GC -XX:ErrorFile=$HBASE_LOG_DIR/hs_err_pid%p.log -Djava.io.tmpdir={{yarn_hbase_java_io_tmpdir}}" export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:InitiatingHeapOccupancyPercent=70 -XX:ReservedCodeCacheSize=256m -Xms{{yarn_hbase_regionserver_heapsize}} -Xmx{{yarn_hbase_regionserver_heapsize}} $JDK_DEPENDED_OPTS" {% endif %} export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xmx{{yarn_hbase_master_heapsize}} $JDK_DEPENDED_OPTS"Hbase-env
Update the HBase Java 11 flags as shown below.
File location: Log on to the Ambari UI → HBase → configs → Advanced hbase-env -> hbase-env template.
# Set environment variables here. # The java implementation to use. Java 1.6 required. export JAVA_HOME={{java64_home}} # HBase Configuration directory export HBASE_CONF_DIR=${HBASE_CONF_DIR:-{{hbase_conf_dir}}} # Extra Java CLASSPATH elements. Optional. export HBASE_CLASSPATH=${HBASE_CLASSPATH} # The maximum amount of heap to use, in MB. Default is 1000. # export HBASE_HEAPSIZE=1000 {% if java_version == 8 %} # For Java version 8 export SERVER_GC_OPTS="-verbose:gc -XX:-PrintGCCause -XX:+PrintAdaptiveSizePolicy -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:{{log_dir}}/gc.log-`date +'%Y%m%d%H%M'` -XX:+PrintHeapAtGC -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution" {% else %} # For Java 11 and above export SERVER_GC_OPTS="-Xlog:gc*,gc+heap=info,gc+age=debug:file={{log_dir}}/gc.log-`date +'%Y%m%d%H%M'`:time,uptime:filecount=10,filesize=200M -XX:+UseG1GC" {% endif %} # Extra Java runtime options. export HBASE_OPTS="-Xms1g -Xmx2g -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:-ResizePLAB -XX:ErrorFile={{log_dir}}/hs_err_pid%p.log -Djava.io.tmpdir={{java_io_tmpdir}}" export HBASE_MASTER_OPTS="-Xms1g -Xmx2g -XX:+UseG1GC" # Uncomment below to enable java garbage collection logging. # export HBASE_OPTS="$HBASE_OPTS -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:$HBASE_HOME/logs/gc-hbase.log" # Uncomment and adjust to enable JMX exporting # See jmxremote.password and jmxremote.access in $JRE_HOME/lib/management to configure remote password access. # More details at: http://java.sun.com/javase/6/docs/technotes/guides/management/agent.html # # export HBASE_JMX_BASE="-Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false" # If you want to configure BucketCache, specify '-XX: MaxDirectMemorySize=' with proper direct memory size # export HBASE_THRIFT_OPTS="$HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10103" # export HBASE_ZOOKEEPER_OPTS="$HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10104" # File naming hosts on which HRegionServers will run. $HBASE_HOME/conf/regionservers by default. export HBASE_REGIONSERVERS=${HBASE_CONF_DIR}/regionservers # Extra ssh options. Empty by default. # export HBASE_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HBASE_CONF_DIR" # Where log files are stored. $HBASE_HOME/logs by default. export HBASE_LOG_DIR={{log_dir}} # A string representing this instance of hbase. $USER by default. # export HBASE_IDENT_STRING=$USER # The scheduling priority for daemon processes. See 'man nice'. # export HBASE_NICENESS=10 # The directory where pid files are stored. /tmp by default. export HBASE_PID_DIR={{pid_dir}} # Seconds to sleep between slave commands. Unset by default. This # can be useful in large clusters, where, e.g., slave rsyncs can # otherwise arrive faster than the master can service them. # export HBASE_SLAVE_SLEEP=0.1 # Tell HBase whether it should manage its own instance of Zookeeper or not. export HBASE_MANAGES_ZK=false # JDK depended options JDK_DEPENDED_OPTS="-XX:ReservedCodeCacheSize=256m" # Set common JVM configuration export HBASE_OPTS="$HBASE_OPTS $JDK_DEPENDED_OPTS" export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $JDK_DEPENDED_OPTS" export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $JDK_DEPENDED_OPTS" export PHOENIX_QUERYSERVER_OPTS="$PHOENIX_QUERYSERVER_OPTS $JDK_DEPENDED_OPTS" # Add Kerberos authentication-related configuration {% if security_enabled %} export HBASE_OPTS="$HBASE_OPTS -Djava.security.auth.login.config={{client_jaas_config_file}} {{zk_security_opts}}" export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Djava.security.auth.login.config={{master_jaas_config_file}} -Djavax.security.auth.useSubjectCredsOnly=false" export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Djava.security.auth.login.config={{regionserver_jaas_config_file}} -Djavax.security.auth.useSubjectCredsOnly=false" export PHOENIX_QUERYSERVER_OPTS="$PHOENIX_QUERYSERVER_OPTS -Djava.security.auth.login.config={{queryserver_jaas_config_file}}" {% endif %} # HBase off-heap MaxDirectMemorySize export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS {% if hbase_max_direct_memory_size %} -XX:MaxDirectMemorySize={{hbase_max_direct_memory_size}}m {% endif %}" export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS {% if hbase_max_direct_memory_size %} -XX:MaxDirectMemorySize={{hbase_max_direct_memory_size}}m {% endif %}"Hive-env
Update 1
Update the Hive Java 11 flags in two places as shown below.
- metastore
- hiveserver2
- File location: Log into the Ambari UI →
Hive→Configs→Advanced hive-env→hive-env template.
# The heap size of the jvm, and jvm args stared by hive shell script can be controlled via:if [ "$SERVICE" = "metastore" ]; then export HADOOP_HEAPSIZE={{hive_metastore_heapsize}} # Setting for HiveMetastore {% if java_version == 8 %} export HADOOP_OPTS="$HADOOP_OPTS -Xloggc:{{hive_log_dir}}/hivemetastore-gc-%t.log -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath={{hive_log_dir}}/hms_heapdump.hprof -Dhive.log.dir={{hive_log_dir}} -Dhive.log.file=hivemetastore.log" {% else %} export HADOOP_OPTS="$HADOOP_OPTS -Xlog:gc*,gc+heap=debug,gc+phases=debug:file={{hive_log_dir}}/hivemetastore-gc-%t.log:time,level,tags:filecount=10,filesize=10M -XX:+UseG1GC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath={{hive_log_dir}}/hms_heapdump.hprof -Dhive.log.dir={{hive_log_dir}} -Dhive.log.file=hivemetastore.log" {% endif %}fiif [ "$SERVICE" = "hiveserver2" ]; then export HADOOP_HEAPSIZE={{hive_heapsize}} # Setting for HiveServer2 and Client {% if java_version == 8 %} # For Java 8 export HADOOP_OPTS="$HADOOP_OPTS -Xloggc:{{hive_log_dir}}/hiveserver2-gc-%t.log -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath={{hive_log_dir}}/hs2_heapdump.hprof -Dhive.log.dir={{hive_log_dir}} -Dhive.log.file=hiveserver2.log" {% else %} # For Java 11 and above export HADOOP_OPTS="$HADOOP_OPTS -Xlog:gc*,gc+heap=debug,gc+phases=debug:file={{hive_log_dir}}/hiveserver2-gc-%t.log:time,level,tags:filecount=10,filesize=10M -XX:+UseG1GC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath={{hive_log_dir}}/hs2_heapdump.hprof -Dhive.log.dir={{hive_log_dir}} -Dhive.log.file=hiveserver2.log" {% endif %}fi{% if security_enabled %}export HADOOP_OPTS="$HADOOP_OPTS -Dzookeeper.sasl.client.username={{zk_principal_user}}"{% endif %}export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -Xms${HADOOP_HEAPSIZE}m -Xmx${HADOOP_HEAPSIZE}m"export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS{{heap_dump_opts}}"# Larger heap size may be required when running queries over large number of files or partitions.# By default hive shell scripts use a heap size of 256 (MB). Larger heap size would also be# appropriate for hive server (hwi etc).# Set HADOOP_HOME to point to a specific hadoop install directoryHADOOP_HOME=${HADOOP_HOME:-{{hadoop_home}}}export HIVE_HOME=${HIVE_HOME:-{{hive_home_dir}}}# Hive Configuration Directory can be controlled by:export HIVE_CONF_DIR=${HIVE_CONF_DIR:-{{hive_config_dir}}}# Folder containing extra libraries required for hive compilation/execution can be controlled by:if [ "${HIVE_AUX_JARS_PATH}" != "" ]; then if [ -f "${HIVE_AUX_JARS_PATH}" ]; then export HIVE_AUX_JARS_PATH=${HIVE_AUX_JARS_PATH} elif [ -d "/usr/odp/current/hive-webhcat/share/hcatalog" ]; then export HIVE_AUX_JARS_PATH=/usr/odp/current/hive-webhcat/share/hcatalog/hive-hcatalog-core.jar fielif [ -d "/usr/odp/current/hive-webhcat/share/hcatalog" ]; then export HIVE_AUX_JARS_PATH=/usr/odp/current/hive-webhcat/share/hcatalog/hive-hcatalog-core.jarfiexport METASTORE_PORT={{hive_metastore_port}}{% if sqla_db_used or lib_dir_available %}export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:{{jdbc_libs_dir}}"export JAVA_LIBRARY_PATH="$JAVA_LIBRARY_PATH:{{jdbc_libs_dir}}"{% endif %}if [ "$SERVICE" = "hiveserver2" ]; thenexport HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=8008"fiif [ "$SERVICE" = "metastore" ]; thenexport HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=8009"fi- File location - Log into the Ambari UI →
Hive→Configs→Advanced→General.
hive.tez.java.opts = -server -Djava.net.preferIPv4Stack=true -XX:NewRatio=8 -XX:+UseNUMA -XX:+UseG1GC -XX:+ResizeTLAB -Xlog:gc*,gc+heap=debug,gc+phases=debug:stdout:time,level,tagsUpdate 2
After completing the Ambari upgrade, during the express upgrade, you might see the below error while starting Hive metastore, due to a initSchema upgrade issue.
No rows affected (0 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> CREATE TABLE `CTLGS` ( `CTLG_ID` BIGINT PRIMARY KEY, `NAME` VARCHAR(256), `DESC` VARCHAR(4000), `LOCATION_URI` VARCHAR(4000) NOT NULL, `CREATE_TIME` INT(11), UNIQUE KEY `UNIQUE_CATALOG` (`NAME`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1Error: Table 'CTLGS' already exists (state=42S01,code=1050)Closing: 0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiveSchema initialization FAILED! Metastore state would be inconsistent!Underlying cause: java.io.IOException : Schema script failed, errorcode 2org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent! at org.apache.hadoop.hive.metastore.tools.schematool.SchemaToolTaskInit.execute(SchemaToolTaskInit.java:66) at org.apache.hadoop.hive.metastore.tools.schematool.MetastoreSchemaTool.run(MetastoreSchemaTool.java:484) at org.apache.hive.beeline.schematool.HiveSchemaTool.main(HiveSchemaTool.java:143) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566) at org.apache.hadoop.util.RunJar.run(RunJar.java:328) at org.apache.hadoop.util.RunJar.main(RunJar.java:241)Caused by: java.io.IOException: Schema script failed, errorcode 2 at org.apache.hive.beeline.schematool.HiveSchemaTool.execSql(HiveSchemaTool.java:110) at org.apache.hive.beeline.schematool.HiveSchemaTool.execSql(HiveSchemaTool.java:88)These issues occur because, after migrating to Hive 4.0.0, it is also necessary to upgrade the Hive Metastore database schema using the following commands.
/usr/odp/current/hive-server2/bin/schematool -initSchema -dbType mysql –verbose/usr/odp/current/hive-server2/bin/schematool -dbType mysql -upgradeSchemaFrom 3.1.4 --verboseThe expected outcome is as follows.
[root@ugnode1 upgrade]# /usr/odp/current/hive-server2/bin/schematool -dbType mysql -upgradeSchemaFrom 3.1.4 --verboseLoading class com.mysql.jdbc.Driver'. This is deprecated. The new driver class is com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.Upgrading from the user input version 3.1.4Metastore connection URL: jdbc:mysql://ugnode1.acceldata.ce:3306/hiveMetastore connection Driver : com.mysql.jdbc.DriverMetastore connection User: hiveStarting upgrade metastore schema from version 3.1.4 to 4.0.0Upgrade script upgrade-3.1.4-to-4.0.0-alpha-2.mysql.sqlConnecting to jdbc:mysql://ugnode1.acceldata.ce:3306/hiveConnected to: MySQL (version 8.0.41)Driver: MySQL Connector/J (version mysql-connector-java-8.0.16.redhat-00001 (Revision: 296d518bea806424de021f02ecb453642c3e7d31))Transaction isolation: TRANSACTION_READ_COMMITTED0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> !autocommit offAutocommit status: false0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> SELECT 'Upgrading MetaStore schema from 3.1.4 to 4.0.0-alpha-2' AS MESSAGE+----------------------------------------------------+| MESSAGE |+----------------------------------------------------+| Upgrading MetaStore schema from 3.1.4 to 4.0.0-alpha-2 |+----------------------------------------------------+1 row selected (0.008 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE COMPLETED_COMPACTIONS ADD COLUMN CC_NEXT_TXN_ID bigintNo rows affected (0.03 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE COMPLETED_COMPACTIONS ADD COLUMN CC_TXN_ID bigintNo rows affected (0.024 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE COMPLETED_COMPACTIONS ADD COLUMN CC_COMMIT_TIME bigintNo rows affected (0.034 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE NOTIFICATION_SEQUENCE ADD CONSTRAINT ONE_ROW_CONSTRAINT CHECK (NNI_ID = 1)1 row affected (0.068 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE COMPACTION_QUEUE ADD COLUMN CQ_POOL_NAME VARCHAR(128)No rows affected (0.055 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE COMPLETED_COMPACTIONS ADD COLUMN CC_POOL_NAME VARCHAR(128)No rows affected (0.062 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> UPDATE VERSION SET SCHEMA_VERSION='4.0.0-alpha-2', VERSION_COMMENT='Hive release version 4.0.0-alpha-2' where VER_ID=11 row affected (0.001 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> SELECT 'Finished upgrading MetaStore schema from 3.1.4 to 4.0.0-alpha-2' AS MESSAGE+----------------------------------------------------+| MESSAGE |+----------------------------------------------------+| Finished upgrading MetaStore schema from 3.1.4 to 4.0.0-alpha-2 |+----------------------------------------------------+1 row selected (0.001 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> !commitCommit complete (0.003 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> !closeallClosing: 0: jdbc:mysql://ugnode1.acceldata.ce:3306/hivebeeline>beeline> Completed upgrade-3.1.4-to-4.0.0-alpha-2.mysql.sqlUpgrade script upgrade-4.0.0-alpha-2-to-4.0.0-beta-1.mysql.sqlConnecting to jdbc:mysql://ugnode1.acceldata.ce:3306/hiveConnected to: MySQL (version 8.0.41)Driver: MySQL Connector/J (version mysql-connector-java-8.0.16.redhat-00001 (Revision: 296d518bea806424de021f02ecb453642c3e7d31))Transaction isolation: TRANSACTION_READ_COMMITTED0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> !autocommit offAutocommit status: false0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> SELECT 'Upgrading MetaStore schema from 4.0.0-alpha-2 to 4.0.0-beta-1' AS MESSAGE+----------------------------------------------------+| MESSAGE |+----------------------------------------------------+| Upgrading MetaStore schema from 4.0.0-alpha-2 to 4.0.0-beta-1 |+----------------------------------------------------+1 row selected (0.002 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE TAB_COL_STATS ADD HISTOGRAM blobNo rows affected (0.044 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE PART_COL_STATS ADD HISTOGRAM blobNo rows affected (0.152 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE COMPACTION_QUEUE ADD COLUMN CQ_NUMBER_OF_BUCKETS INTEGERNo rows affected (0.152 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE COMPLETED_COMPACTIONS ADD COLUMN CC_NUMBER_OF_BUCKETS INTEGERNo rows affected (0.168 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE COMPACTION_QUEUE ADD COLUMN CQ_ORDER_BY VARCHAR(4000)No rows affected (0.053 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE COMPLETED_COMPACTIONS ADD COLUMN CC_ORDER_BY VARCHAR(4000)No rows affected (0.07 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> CREATE TABLE MIN_HISTORY_WRITE_ID ( MH_TXNID bigint NOT NULL, MH_DATABASE varchar(128) NOT NULL, MH_TABLE varchar(256) NOT NULL, MH_WRITEID bigint NOT NULL, FOREIGN KEY (MH_TXNID) REFERENCES TXNS (TXN_ID) ) ENGINE=InnoDB DEFAULT CHARSET=latin1No rows affected (0.036 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> DROP INDEX TAB_COL_STATS_IDX ON TAB_COL_STATSNo rows affected (0.013 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> CREATE INDEX TAB_COL_STATS_IDX ON TAB_COL_STATS (DB_NAME, TABLE_NAME, COLUMN_NAME, CAT_NAME) USING BTREENo rows affected (0.013 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> DROP INDEX PCS_STATS_IDX ON PART_COL_STATSNo rows affected (0.013 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> CREATE INDEX PCS_STATS_IDX ON PART_COL_STATS (DB_NAME,TABLE_NAME,COLUMN_NAME,PARTITION_NAME,CAT_NAME) USING BTREENo rows affected (0.013 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> ALTER TABLE METASTORE_DB_PROPERTIES ADD PROPERTYCONTENT blobNo rows affected (0.048 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> UPDATE SDS SET INPUT_FORMAT = 'org.apache.hadoop.hive.kudu.KuduInputFormat', OUTPUT_FORMAT = 'org.apache.hadoop.hive.kudu.KuduOutputFormat' WHERE SD_ID IN ( SELECT TBLS.SD_ID FROM TBLS INNER JOIN TABLE_PARAMS ON TBLS.TBL_ID = TABLE_PARAMS.TBL_ID WHERE PARAM_VALUE LIKE '%KuduStorageHandler%' )No rows affected (0.003 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> UPDATE SERDES SET SERDES.SLIB = "org.apache.hadoop.hive.kudu.KuduSerDe" WHERE SERDE_ID IN ( SELECT SDS.SERDE_ID FROM TBLS INNER JOIN SDS ON TBLS.SD_ID = SDS.SD_ID INNER JOIN TABLE_PARAMS ON TBLS.TBL_ID = TABLE_PARAMS.TBL_ID WHERE TABLE_PARAMS.PARAM_VALUE LIKE '%KuduStorageHandler%' )No rows affected (0.001 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> UPDATE VERSION SET SCHEMA_VERSION='4.0.0-beta-1', VERSION_COMMENT='Hive release version 4.0.0-beta-1' where VER_ID=11 row affected (0.001 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> SELECT 'Finished upgrading MetaStore schema from 4.0.0-alpha-2 to 4.0.0-beta-1' AS MESSAGE+----------------------------------------------------+| MESSAGE |+----------------------------------------------------+| Finished upgrading MetaStore schema from 4.0.0-alpha-2 to 4.0.0-beta-1 |+----------------------------------------------------+1 row selected (0 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> !commitCommit complete (0.002 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> !closeallClosing: 0: jdbc:mysql://ugnode1.acceldata.ce:3306/hivebeeline>beeline> Completed upgrade-4.0.0-alpha-2-to-4.0.0-beta-1.mysql.sqlUpgrade script upgrade-4.0.0-beta-1-to-4.0.0.mysql.sqlConnecting to jdbc:mysql://ugnode1.acceldata.ce:3306/hiveConnected to: MySQL (version 8.0.41)Driver: MySQL Connector/J (version mysql-connector-java-8.0.16.redhat-00001 (Revision: 296d518bea806424de021f02ecb453642c3e7d31))Transaction isolation: TRANSACTION_READ_COMMITTED0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> !autocommit offAutocommit status: false0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> SELECT 'Upgrading MetaStore schema from 4.0.0-beta-1 to 4.0.0' AS MESSAGE+----------------------------------------------------+| MESSAGE |+----------------------------------------------------+| Upgrading MetaStore schema from 4.0.0-beta-1 to 4.0.0 |+----------------------------------------------------+1 row selected (0.001 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> DROP TABLE INDEX_PARAMSNo rows affected (0.011 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> DROP TABLE IDXSNo rows affected (0.014 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> DROP INDEX UNIQUEPARTITION ON PARTITIONSNo rows affected (0.02 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> CREATE UNIQUE INDEX UNIQUEPARTITION ON PARTITIONS (TBL_ID, PART_NAME)No rows affected (0.018 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> DROP INDEX PARTITIONS_N49 on PARTITIONSNo rows affected (0.018 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> UPDATE VERSION SET SCHEMA_VERSION='4.0.0', VERSION_COMMENT='Hive release version 4.0.0' where VER_ID=11 row affected (0.001 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> SELECT 'Finished upgrading MetaStore schema from 4.0.0-beta-1 to 4.0.0' AS MESSAGE+----------------------------------------------------+| MESSAGE |+----------------------------------------------------+| Finished upgrading MetaStore schema from 4.0.0-beta-1 to 4.0.0 |+----------------------------------------------------+1 row selected (0.001 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> !commitCommit complete (0.003 seconds)0: jdbc:mysql://ugnode1.acceldata.ce:3306/hiv> !closeallClosing: 0: jdbc:mysql://ugnode1.acceldata.ce:3306/hivebeeline>beeline> Completed upgrade-4.0.0-beta-1-to-4.0.0.mysql.sqlInfra-solr-env
Update the Infra-Solr Java11 flags as shown below.
File location: Log into the Ambari UI → Infra Solr → configs → Advanced Infr-Solr-env -> Infra Solr-env template.
# Licensed to the Apache Software Foundation (ASF) under one or more# contributor license agreements. See the NOTICE file distributed with# this work for additional information regarding copyright ownership.# The ASF licenses this file to You under the Apache License, Version 2.0# (the "License"); you may not use this file except in compliance with# the License. You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.# By default the script will use JAVA_HOME to determine which java# to use, but you can set a specific path for Solr to use without# affecting other Java applications on your server/workstation.SOLR_JAVA_HOME={{java64_home}}# Increase Java Min/Max Heap as needed to support your indexing / query needsSOLR_JAVA_MEM="-Xms{{infra_solr_min_mem}}m -Xmx{{infra_solr_max_mem}}m"SOLR_JAVA_STACK_SIZE="-Xss{{infra_solr_java_stack_size}}m"{% if java_version < 11 %} # For JDK 8 and below infra_solr_gc_log_opts="-verbose:gc -XX:+PrintHeapAtGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=15 -XX:GCLogFileSize=200M" GC_LOG_OPTS="{{infra_solr_gc_log_opts}} -Xloggc:{{infra_solr_log_dir}}/solr_gc.log" infra_solr_gc_tune="-XX:NewRatio=3 -XX:SurvivorRatio=4 -XX:TargetSurvivorRatio=90 -XX:MaxTenuringThreshold=8 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:ConcGCThreads=4 -XX:ParallelGCThreads=4 -XX:+CMSScavengeBeforeRemark -XX:PretenureSizeThreshold=64m -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=50 -XX:CMSMaxAbortablePrecleanTime=6000 -XX:+CMSParallelRemarkEnabled -XX:+ParallelRefProcEnabled"{% else %} # For JDK 11 and above GC_LOG_OPTS="-Xlog:gc*=info:file={{infra_solr_log_dir}}/solr_gc.log:time,uptime" # Use separate options to handle log file rotation and size LOG_ROTATION_OPTS="-XX:NumberOfGCLogFiles=15 -XX:GCLogFileSize=200M" # Garbage Collection Tuning infra_solr_gc_tune="-XX:NewRatio=3 -XX:SurvivorRatio=4 -XX:TargetSurvivorRatio=90 -XX:MaxTenuringThreshold=8 -XX:+UseG1GC -XX:+ParallelRefProcEnabled -XX:ConcGCThreads=4 -XX:ParallelGCThreads=4 -XX:+DisableExplicitGC" # Combine all options JAVA_OPTS="${GC_LOG_OPTS} ${LOG_ROTATION_OPTS} ${infra_solr_gc_tune}"{% endif %}# Set the ZooKeeper connection string if using an external ZooKeeper ensemble# e.g. host1:2181,host2:2181/chroot# Leave empty if not using SolrCloudZK_HOST="{{zookeeper_quorum}}{{infra_solr_znode}}"# Set the ZooKeeper client timeout (for SolrCloud mode)ZK_CLIENT_TIMEOUT="60000"# By default the start script uses "localhost"; override the hostname here# for production SolrCloud environments to control the hostname exposed to cluster stateSOLR_HOST=`hostname -f`# By default the start script uses UTC; override the timezone if needed#SOLR_TIMEZONE="UTC"# Set to true to activate the JMX RMI connector to allow remote JMX client applications# to monitor the JVM hosting Solr; set to "false" to disable that behavior# (false is recommended in production environments)ENABLE_REMOTE_JMX_OPTS="{{infra_solr_jmx_enabled}}"# The script will use SOLR_PORT+10000 for the RMI_PORT or you can set it hereRMI_PORT={{infra_solr_jmx_port}}# Anything you add to the SOLR_OPTS variable will be included in the java# start command line as-is, in ADDITION to other options. If you specify the# -a option on start script, those options will be appended as well. Examples:#SOLR_OPTS="$SOLR_OPTS -Dsolr.autoSoftCommit.maxTime=3000"#SOLR_OPTS="$SOLR_OPTS -Dsolr.autoCommit.maxTime=60000"#SOLR_OPTS="$SOLR_OPTS -Dsolr.clustering.enabled=true"SOLR_OPTS="$SOLR_OPTS -Djava.rmi.server.hostname={{hostname}}"{% if infra_solr_extra_java_opts -%}SOLR_OPTS="$SOLR_OPTS {{infra_solr_extra_java_opts}}"{% endif %}# Location where the bin/solr script will save PID files for running instances# If not set, the script will create PID files in $SOLR_TIP/binSOLR_PID_DIR={{infra_solr_piddir}}# Path to a directory where Solr creates index files, the specified directory# must contain a solr.xml; by default, Solr will use server/solrSOLR_HOME={{infra_solr_datadir}}# Solr provides a default Log4J configuration properties file in server/resources# however, you may want to customize the log settings and file appender location# so you can point the script to use a different log4j.properties fileLOG4J_PROPS={{infra_solr_conf}}/log4j2.xml# Location where Solr should write logs to; should agree with the file appender# settings in server/resources/log4j.propertiesSOLR_LOGS_DIR={{infra_solr_log_dir}}# Sets the port Solr binds to, default is 8983SOLR_PORT={{infra_solr_port}}# Be sure to update the paths to the correct keystore for your environment{% if infra_solr_ssl_enabled %}SOLR_SSL_KEY_STORE={{infra_solr_keystore_location}}SOLR_SSL_KEY_STORE_PASSWORD={{infra_solr_keystore_password}}SOLR_SSL_TRUST_STORE={{infra_solr_truststore_location}}SOLR_SSL_TRUST_STORE_PASSWORD={{infra_solr_truststore_password}}SOLR_SSL_NEED_CLIENT_AUTH=falseSOLR_SSL_WANT_CLIENT_AUTH=false{% endif %}# Uncomment to set a specific SSL port (-Djetty.ssl.port=N); if not set# and you are using SSL, then the start script will use SOLR_PORT for the SSL port#SOLR_SSL_PORT={% if security_enabled -%}SOLR_JAAS_FILE={{infra_solr_jaas_file}}SOLR_KERB_KEYTAB={{infra_solr_web_kerberos_keytab}}SOLR_KERB_PRINCIPAL={{infra_solr_web_kerberos_principal}}SOLR_OPTS="$SOLR_OPTS -Dsolr.hdfs.security.kerberos.principal={{infra_solr_kerberos_principal}}"SOLR_OPTS="$SOLR_OPTS {{zk_security_opts}}"SOLR_AUTH_TYPE="kerberos"SOLR_AUTHENTICATION_OPTS=" -DauthenticationPlugin=org.apache.solr.security.KerberosPlugin -Djava.security.auth.login.config=$SOLR_JAAS_FILE -Dsolr.kerberos.principal=${SOLR_KERB_PRINCIPAL} -Dsolr.kerberos.keytab=${SOLR_KERB_KEYTAB} -Dsolr.kerberos.cookie.domain=${SOLR_HOST}"{% endif %}Druid-env
Update the Druid Java-11 flags as shown below.
File location: Log on to the Ambari UI → Druid → configs → Advanced druid-env.
druid.broker.jvm.opts=--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED --add-exports=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=jdk.management/com.sun.management.internal=ALL-UNNAMED -Djava.security.auth.login.config={druid_jaas_file} druid.coordinator.jvm.opts=--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED --add-exports=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=jdk.management/com.sun.management.internal=ALL-UNNAMED -Djava.security.auth.login.config={druid_jaas_file} druid.historical.jvm.opts=--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED --add-exports=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=jdk.management/com.sun.management.internal=ALL-UNNAMED -Djava.security.auth.login.config={druid_jaas_file} druid.middlemanager.jvm.opts=--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED --add-exports=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=jdk.management/com.sun.management.internal=ALL-UNNAMED -Djava.security.auth.login.config={druid_jaas_file} druid.overlord.jvm.opts=--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED --add-exports=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=jdk.management/com.sun.management.internal=ALL-UNNAMED -Djava.security.auth.login.config={druid_jaas_file} druid.router.jvm.opts=--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED --add-exports=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/jdk.internal.ref=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=jdk.management/com.sun.management.internal=ALL-UNNAMED -Djava.security.auth.login.config={druid_jaas_file}Tez-env
Update the Tez Java11 flags as shown below.
File location: Log into the Ambari UI → Tez → Configs → Advanced tez-env -> Tez-env template.
# Tez specific configurationexport TEZ_CONF_DIR={{config_dir}}{% if java_version == 8 %}# Java 8 JVM optionsexport tez.am.launch.cmd-opts="-XX:+PrintGCDetails -verbose:gc -XX:+PrintGCTimeStamps -XX:+UseNUMA -XX:+UseG1GC -XX:+ResizeTLAB{{heap_dump_opts}}"export tez.task.launch.cmd-opts="-XX:+PrintGCDetails -verbose:gc -XX:+PrintGCTimeStamps -XX:+UseNUMA -XX:+UseG1GC -XX:+ResizeTLAB{{heap_dump_opts}}"{% else %}# Java 11 JVM optionsexport tez.am.launch.cmd-opts="-Xlog:gc*:file={{gc_log_path}}/tez_am_gc.log:time,uptime,level,tags:filecount=10,filesize=10M -XX:+UseNUMA -XX:+UseG1GC -XX:+ResizeTLAB{{heap_dump_opts}}"export tez.task.launch.cmd-opts="-Xlog:gc*:file={{gc_log_path}}/tez_task_gc.log:time,uptime,level,tags:filecount=10,filesize=10M -XX:+UseNUMA -XX:+UseG1GC -XX:+ResizeTLAB{{heap_dump_opts}}"{% endif %}# Set HADOOP_HOME to point to a specific hadoop install directoryexport HADOOP_HOME=${HADOOP_HOME:-{{hadoop_home}}}# The java implementation to use.export JAVA_HOME={{java64_home}}Update the custom Tez-site configurations as shown below.
tez.am.launch.cmd-opts=-XX:+PrintGCDetails -verbose:gc -XX:+UseNUMA -XX:+UseG1GC -XX:+ResizeTLAB{{heapdump opts}}tez.task.launch.cmd-opts=-XX:+PrintGCDetails -verbose:gc -XX:+UseNUMA -XX:+UseG1GC -XX:+ResizeTLAB{{heap_dump_opts}}Ranger KMS-env
For adding the Ranger-kms logback configuration, Navigate to Ranger-kms → Configs → Advanced -> Advanced kms-logback.
<?xml version="1.0" encoding="UTF-8"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.--><configuration scan="true"> <appender name="kms-audit" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--See http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <!--and http://logback.qos.ch/manual/appenders.html#TimeBasedRollingPolicy--> <!--for further documentation--> <Append>true</Append> <File>${kms.log.dir}/kms-audit-${hostname}-${user}.log</File> <encoder> <pattern>%d{ISO8601} %m%n</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${kms.log.dir}/kms-audit-${hostname}-${user}.log.%d{yyyy-MM-dd}</fileNamePattern> <maxHistory>15</maxHistory> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> </appender> <appender name="kms-metric" class="ch.qos.logback.core.FileAppender"> <!--See also http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <Append>false</Append> <File>${kms.log.dir}/ranger_kms_metric_data_for_${metric.type}.log</File> <encoder> <pattern>%m%n</pattern> </encoder> </appender> <appender name="kms" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--See http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <!--and http://logback.qos.ch/manual/appenders.html#TimeBasedRollingPolicy--> <!--for further documentation--> <File>${kms.log.dir}/ranger-kms-${hostname}-${user}.log</File> <Append>true</Append> <encoder> <pattern>%d{ISO8601} %-5p [%t] %c{1} \(%F:%L\) - %m%n</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${kms.log.dir}/ranger-kms-${hostname}-${user}.log.%d{yyyy-MM-dd}</fileNamePattern> <maxHistory>15</maxHistory> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> </appender> <logger name="com.sun.jersey.server.wadl.generators.WadlGeneratorJAXBGrammarGenerator" level="OFF"/> <logger name="kms-audit" additivity="false" level="INFO"> <appender-ref ref="kms-audit"/> </logger> <logger name="org.apache.hadoop" level="INFO"/> <logger name="org.apache.hadoop.conf" level="INFO"/> <logger name="org.apache.hadoop.crypto.key.kms.server.KMSMetricUtil" level="INFO"> <appender-ref ref="kms-metric"/> </logger> <logger name="org.apache.ranger" level="INFO"/> <root level="WARN"> <appender-ref ref="kms"/> </root></configuration>Following are the reference templates for making Java 11 runtime flags:
- Druid-env-template
- Hadoop-env-template
- Hbase-env-template
- Hive-env-template
- Infra-solr-env-template
- Tez-env-template
- Yarn-env-template
- Ranger-admin-logback.xml
- Ranger-kms-logback.xml
- Ranger-tagsync-logback.xml
- Ranger-usersync-logback.xml
Known Issues
During the ODP upgrade, where Ambari-2.7.9.x has already been upgraded, the following services might experience downtime. This downtime interrupts the ODP stack upgrade when using the express method.
Affected Services:
- Ranger
- Ranger KMS
- HDFS
- Kafka
- Hive
Ranger
Issue 1: Ranger Admin service start
Traceback (most recent call last): File "/var/lib/ambari-agent/cache/stacks/ODP/3.0/services/RANGER/package/scripts/ranger_admin.py", line 258, in <module> RangerAdmin().execute() File "/usr/lib/ambari-agent/lib/resource_management/libraries/script/script.py", line 351, in execute method(env) File "/usr/lib/ambari-agent/lib/resource_management/libraries/script/script.py", line 1009, in restart self.start(env, upgrade_type=upgrade_type) File "/var/lib/ambari-agent/cache/stacks/ODP/3.0/services/RANGER/package/scripts/ranger_admin.py", line 114, in start self.configure(env, upgrade_type=upgrade_type, setup_db=params.stack_supports_ranger_setup_db_on_start) File "/var/lib/ambari-agent/cache/stacks/ODP/3.0/services/RANGER/package/scripts/ranger_admin.py", line 151, in configure setup_ranger_xml.ranger('ranger_admin', upgrade_type=upgrade_type) File "/var/lib/ambari-agent/cache/stacks/ODP/3.0/services/RANGER/package/scripts/setup_ranger_xml.py", line 49, in ranger setup_ranger_admin(upgrade_type=upgrade_type) File "/var/lib/ambari-agent/cache/stacks/ODP/3.0/services/RANGER/package/scripts/setup_ranger_xml.py", line 207, in setup_ranger_admin content=InlineTemplate(params.admin_logback_content), File "/usr/lib/ambari-agent/lib/resource_management/core/source.py", line 149, in __init__ super(InlineTemplate, self).__init__(name, extra_imports, **kwargs) File "/usr/lib/ambari-agent/lib/resource_management/core/source.py", line 136, in __init__ self.template = self.template_env.get_template(self.name) File "/usr/lib/ambari-agent/lib/ambari_jinja2/environment.py", line 717, in get_template return self._load_template(name, self.make_globals(globals)) File "/usr/lib/ambari-agent/lib/ambari_jinja2/environment.py", line 691, in _load_template template = self.loader.load(self, name, globals) File "/usr/lib/ambari-agent/lib/ambari_jinja2/loaders.py", line 115, in load source, filename, uptodate = self.get_source(environment, name)ValueError: too many values to unpack (expected 3)Solution:
Log into the backend database for the Ambari-server.
- In this case, MySQL is used as the Ambari server’s backend database.
Execute the following SQL query to identify the required configurations.
SELECT * FROM ( SELECT cc.config_id, cc.type_name, service_name, sc.version, sc.note, (SELECT MAX(version) FROM ambari.serviceconfig s WHERE s.service_name = sc.service_name) AS max_version FROM ambari.serviceconfig sc INNER JOIN ambari.serviceconfigmapping scm ON sc.service_config_id = scm.service_config_id INNER JOIN ambari.clusterconfig cc ON cc.config_id = scm.config_id WHERE sc.service_name IN ("RANGER_KMS", "RANGER") AND sc.version = (SELECT MAX(version) FROM ambari.serviceconfig s WHERE s.service_name = sc.service_name)) AS res WHERE type_name IN ("kms-log4j", "admin-log4j", "tagsync-log4j", "usersync-log4j");- The Expected Response is as follows.
+-----------+----------------+--------------+---------+----------------------------------------+-------------+| config_id | type_name | service_name | version | note | max_version |+-----------+----------------+--------------+---------+----------------------------------------+-------------+| 232 | kms-log4j | RANGER_KMS | 4 | Enabling Kerberos for added components | 4 || 218 | admin-log4j | RANGER | 4 | | 4 || 228 | tagsync-log4j | RANGER | 4 | | 4 || 229 | usersync-log4j | RANGER | 4 | | 4 |+-----------+----------------+--------------+---------+----------------------------------------+-------------+- Update the required configurations.
- Ranger-admin service: Update
admin-log4jtoadmin-logback
UPDATE ambari.clusterconfig SET type_name = "admin-logback" WHERE config_id = 218;- Ranger tagsync service: Update
tagsync-log4jtotagsync-logback
UPDATE ambari.clusterconfig SET type_name = "tagsync-logback" WHERE config_id = 228;- Ranger usersync service: Update
usersync-log4jtousersync-logback
UPDATE ambari.clusterconfig SET type_name = "usersync-logback" WHERE config_id = 229;- Restart the Ambari-server.
ambari-server restartIssue 2: Ranger Admin service start
2025-04-25 11:19:26,414 [I] java patch PatchForOzoneServiceDefConfigUpdate_J10051 is being applied..ch.qos.logback.core.joran.spi.JoranException: Problem parsing XML document. See previously reported errors. at ch.qos.logback.core.joran.event.SaxEventRecorder.recordEvents(SaxEventRecorder.java:70) at ch.qos.logback.core.joran.GenericXMLConfigurator.populateSaxEventRecorder(GenericXMLConfigurator.java:184) at ch.qos.logback.core.joran.GenericXMLConfigurator.doConfigure(GenericXMLConfigurator.java:158) at ch.qos.logback.core.joran.GenericXMLConfigurator.doConfigure(GenericXMLConfigurator.java:122) at ch.qos.logback.core.joran.GenericXMLConfigurator.doConfigure(GenericXMLConfigurator.java:65) at ch.qos.logback.classic.util.DefaultJoranConfigurator.configureByResource(DefaultJoranConfigurator.java:68) at ch.qos.logback.classic.util.DefaultJoranConfigurator.configure(DefaultJoranConfigurator.java:35) at ch.qos.logback.classic.util.ContextInitializer.invokeConfigure(ContextInitializer.java:128) at ch.qos.logback.classic.util.ContextInitializer.autoConfig(ContextInitializer.java:103) at ch.qos.logback.classic.util.ContextInitializer.autoConfig(ContextInitializer.java:66) at ch.qos.logback.classic.spi.LogbackServiceProvider.initializeLoggerContext(LogbackServiceProvider.java:52) at ch.qos.logback.classic.spi.LogbackServiceProvider.initialize(LogbackServiceProvider.java:41) at org.slf4j.LoggerFactory.bind(LoggerFactory.java:196) at org.slf4j.LoggerFactory.performInitialization(LoggerFactory.java:183) at org.slf4j.LoggerFactory.getProvider(LoggerFactory.java:486) at org.slf4j.LoggerFactory.getILoggerFactory(LoggerFactory.java:472) at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:421) at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:447) at org.apache.ranger.patch.BaseLoader.<clinit>(BaseLoader.java:40)Caused by: org.xml.sax.SAXParseException; systemId: file:/usr/odp/current/ranger-admin/ews/webapp/WEB-INF/classes/conf/logback.xml; lineNumber: 2; columnNumber: 1; Content is not allowed in prolog. at java.xml/com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(AbstractSAXParser.java:1243) at java.xml/com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:635) at java.xml/com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl.parse(SAXParserImpl.java:324) at ch.qos.logback.core.joran.event.SaxEventRecorder.recordEvents(SaxEventRecorder.java:64) ... 18 moreSolution: Update the Ranger Configuration
- Log into the Ambari UI →
Ranger→Configs→Advanced→Advanced admin-logback.
Replace the admin-logback-xml template with the one below.
<?xml version="1.0" encoding="UTF-8"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.--><configuration> <appender name="xa_log_appender" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--See http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <!--and http://logback.qos.ch/manual/appenders.html#TimeBasedRollingPolicy--> <!--for further documentation--> <file>{{admin_log_dir}}/ranger-admin-${hostname}-${user}.log</file> <append>true</append> <encoder> <pattern>%date [%thread] %level{5} [%file:%line] %msg%n</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>{{admin_log_dir}}/ranger-admin-${hostname}-${user}.log.%d{yyyy-MM-dd}</fileNamePattern> <maxHistory>15</maxHistory> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> </appender> <appender name="sql_appender" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--See http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <!--and http://logback.qos.ch/manual/appenders.html#TimeBasedRollingPolicy--> <!--for further documentation--> <file>{{admin_log_dir}}/ranger_admin_sql.log</file> <append>true</append> <encoder> <pattern>%d [%t] %-5p %C{6} \(%F:%L\) %msg%n</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>{{admin_log_dir}}/ranger_admin_sql.log.%d{yyyy-MM-dd}</fileNamePattern> <maxHistory>15</maxHistory> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> </appender> <appender name="perf_appender" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--See http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <!--and http://logback.qos.ch/manual/appenders.html#TimeBasedRollingPolicy--> <!--for further documentation--> <file>{{admin_log_dir}}/ranger_admin_perf.log</file> <append>true</append> <encoder> <pattern>%d [%t] %msg%n</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>{{admin_log_dir}}/ranger_admin_perf.log.%d{yyyy-MM-dd}</fileNamePattern> <maxHistory>15</maxHistory> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> </appender> <appender name="patch_logger" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--See http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <!--and http://logback.qos.ch/manual/appenders.html#TimeBasedRollingPolicy--> <!--for further documentation--> <append>true</append> <file>{{admin_log_dir}}/ranger_db_patch.log</file> <encoder> <pattern>%d [%t] %-5p %C{6} \(%F:%L\) %msg%n</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>{{admin_log_dir}}/ranger_db_patch.log.%d{yyyy-MM-dd}</fileNamePattern> <maxHistory>15</maxHistory> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> </appender> <logger name="xa" additivity="false" level="info"> <appender-ref ref="xa_log_appender"/> </logger> <logger name="jdbc.connection" additivity="false" level="error"> <appender-ref ref="sql_appender"/> </logger> <logger name="com.mchange" additivity="false" level="warn" /> <logger name="org.apache.ranger.perf" additivity="false" level="info"> <appender-ref ref="perf_appender"/> </logger> <logger name="jdbc.audit" additivity="false" level="error"> <appender-ref ref="sql_appender"/> </logger> <logger name="org.apache.ranger.patch" additivity="false" level="info"> <appender-ref ref="patch_logger"/> </logger> <logger name="jdbc.resultset" additivity="false" level="error"> <appender-ref ref="sql_appender"/> </logger> <logger name="org.springframework" additivity="false" level="warn"> <appender-ref ref="patch_logger"/> </logger> <logger name="jdbc.sqltiming" additivity="false" level="warn"> <appender-ref ref="sql_appender"/> </logger> <logger name="org.hibernate.SQL" additivity="false" level="warn"> <appender-ref ref="sql_appender"/> </logger> <logger name="org.apache.ranger" additivity="false" level="info"> <appender-ref ref="xa_log_appender"/> </logger> <logger name="jdbc.sqlonly" additivity="false" level="error"> <appender-ref ref="sql_appender"/> </logger> <root level="warn"> <appender-ref ref="xa_log_appender"/> </root></configuration>- On the Ambari UI, navigate to
RANGER→CONFIGS->ADVANCED->Advanced tagsync-logback,update with the following content, and save.
<?xml version="1.0" encoding="UTF-8"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.--><configuration> <appender name="logFile" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--See http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <!--and http://logback.qos.ch/manual/appenders.html#TimeBasedRollingPolicy--> <!--for further documentation--> <file>{{tagsync_log_dir}}/tagsync.log</file> <encoder> <pattern>%d{dd MMM yyyy HH:mm:ss} %5p %c{1} [%t] - %L %m%n</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>{{tagsync_log_dir}}/tagsync.log.%d{yyyy-MM-dd}</fileNamePattern> <maxHistory>15</maxHistory> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> </appender> <root level="info"> <appender-ref ref="logFile"/> </root></configuration>- On the Ambari UI, navigate to
RANGER→CONFIGS->ADVANCED->Advanced usersync-logback,update with the following content, and save.
<?xml version="1.0" encoding="UTF-8"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.--><configuration> <appender name="logFile" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--See http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <!--and http://logback.qos.ch/manual/appenders.html#TimeBasedRollingPolicy--> <!--for further documentation--> <file>{{usersync_log_dir}}/usersync-${hostname}-${user}.log</file> <encoder> <pattern>%d{dd MMM yyyy HH:mm:ss} %5p %c{1} [%t] - %m%n</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>{{usersync_log_dir}}/usersync-${hostname}-${user}.log.%d{yyyy-MM-dd}</fileNamePattern> <maxHistory>15</maxHistory> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> </appender> <root level="info"> <appender-ref ref="logFile"/> </root></configuration>You can now proceed with the Ranger service restart from the Ambari UI. It must start smoothly.
Ranger KMS
During the cluster upgrade (after Ambari is upgraded to 2.7.9.x but before the ODP stack is upgraded), the Ranger-KMS service might not start due to the following error:
raise Fail("Configuration parameter '" + self.name + "' was not found in configurations dictionary!")resource_management.core.exceptions.Fail: Configuration parameter 'kms-logback' was not found in configurations dictionary!Kms-log4j is replaced with kms-logback starting from version 3.2.3.x.
Solution:
Log into the backend database for the Ambari server.
In this case, MySQL is the backend database for the Ambari server.
select * from (SELECT cc.config_id, cc.type_name, service_name, sc.version, sc.note, (SELECT MAX(version) FROM ambari.serviceconfig s WHERE s.service_name = sc.service_name) AS max_versionFROM ambari.serviceconfig scINNER JOIN ambari.serviceconfigmapping scmON sc.service_config_id = scm.service_config_idINNER JOIN ambari.clusterconfig ccON cc.config_id = scm.config_idWHERE sc.service_name IN ("RANGER_KMS", "RANGER") and sc.version=(SELECT MAX(version) FROM ambari.serviceconfig s WHERE s.service_name = sc.service_name)) as res where type_name in ("kms-log4j", "admin-log4j", "tagsync-log4j", "usersync-log4j");- Response:
+-----------+----------------+--------------+---------+----------------------------------------+-------------+| config_id | type_name | service_name | version | note | max_version |+-----------+----------------+--------------+---------+----------------------------------------+-------------+| 232 | kms-log4j | RANGER_KMS | 4 | Enabling Kerberos for added components | 4 || 218 | admin-log4j | RANGER | 4 | | 4 || 228 | tagsync-log4j | RANGER | 4 | | 4 || 229 | usersync-log4j | RANGER | 4 | | 4 |+-----------+----------------+--------------+---------+----------------------------------------+-------------+Ranger-Admin Service Required Change
Update kms-log4j to kms-logback:
UPDATE ambari.clusterconfig SET type_name = "kms-logback" WHERE config_id = 232;From the Ambari-Server host, perform the following steps:
- Edit the File:
Path: /var/lib/ambari-server/resources/stacks/ODP/3.0/services/RANGER_KMS/package/scripts/kms.py
Locate the following lines:
File(os.path.join(params.kms_conf_dir, "kms-log4j.properties"), owner=params.kms_user, group=params.kms_group, content=InlineTemplate(params.kms_log4j), mode=0644 )Comment them out as shown below:
"""File(os.path.join(params.kms_conf_dir, "kms-log4j.properties"), owner=params.kms_user, group=params.kms_group, content=InlineTemplate(params.kms_log4j), mode=0644 )"""- Restart the Ambari-Server.
ambari-server restartYou can now proceed with restarting the Ranger-KMS service from the Ambari UI. It must start smoothly.
Update the Ranger KMS Configuration
- Log into the Ambari UI and navigate to
RANGER→CONFIGS->ADVANCED->Advanced admin-logback,update the following content, and save.
<?xml version="1.0" encoding="UTF-8"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.--><configuration scan="true"> <appender name="kms-audit" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--See http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <!--and http://logback.qos.ch/manual/appenders.html#TimeBasedRollingPolicy--> <!--for further documentation--> <Append>true</Append> <File>${kms.log.dir}/kms-audit-${hostname}-${user}.log</File> <encoder> <pattern>%d{ISO8601} %m%n</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${kms.log.dir}/kms-audit-${hostname}-${user}.log.%d{yyyy-MM-dd}</fileNamePattern> <maxHistory>15</maxHistory> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> </appender> <appender name="kms-metric" class="ch.qos.logback.core.FileAppender"> <!--See also http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <Append>false</Append> <File>${kms.log.dir}/ranger_kms_metric_data_for_${metric.type}.log</File> <encoder> <pattern>%m%n</pattern> </encoder> </appender> <appender name="kms" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!--See http://logback.qos.ch/manual/appenders.html#RollingFileAppender--> <!--and http://logback.qos.ch/manual/appenders.html#TimeBasedRollingPolicy--> <!--for further documentation--> <File>${kms.log.dir}/ranger-kms-${hostname}-${user}.log</File> <Append>true</Append> <encoder> <pattern>%d{ISO8601} %-5p [%t] %c{1} \(%F:%L\) - %m%n</pattern> </encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${kms.log.dir}/ranger-kms-${hostname}-${user}.log.%d{yyyy-MM-dd}</fileNamePattern> <maxHistory>15</maxHistory> <cleanHistoryOnStart>true</cleanHistoryOnStart> </rollingPolicy> </appender> <logger name="com.sun.jersey.server.wadl.generators.WadlGeneratorJAXBGrammarGenerator" level="OFF"/> <logger name="kms-audit" additivity="false" level="INFO"> <appender-ref ref="kms-audit"/> </logger> <logger name="org.apache.hadoop" level="INFO"/> <logger name="org.apache.hadoop.conf" level="INFO"/> <logger name="org.apache.hadoop.crypto.key.kms.server.KMSMetricUtil" level="INFO"> <appender-ref ref="kms-metric"/> </logger> <logger name="org.apache.ranger" level="INFO"/> <root level="WARN"> <appender-ref ref="kms"/> </root></configuration>- Restart the Ranger KMS service from the Ambari UI.
HDFS
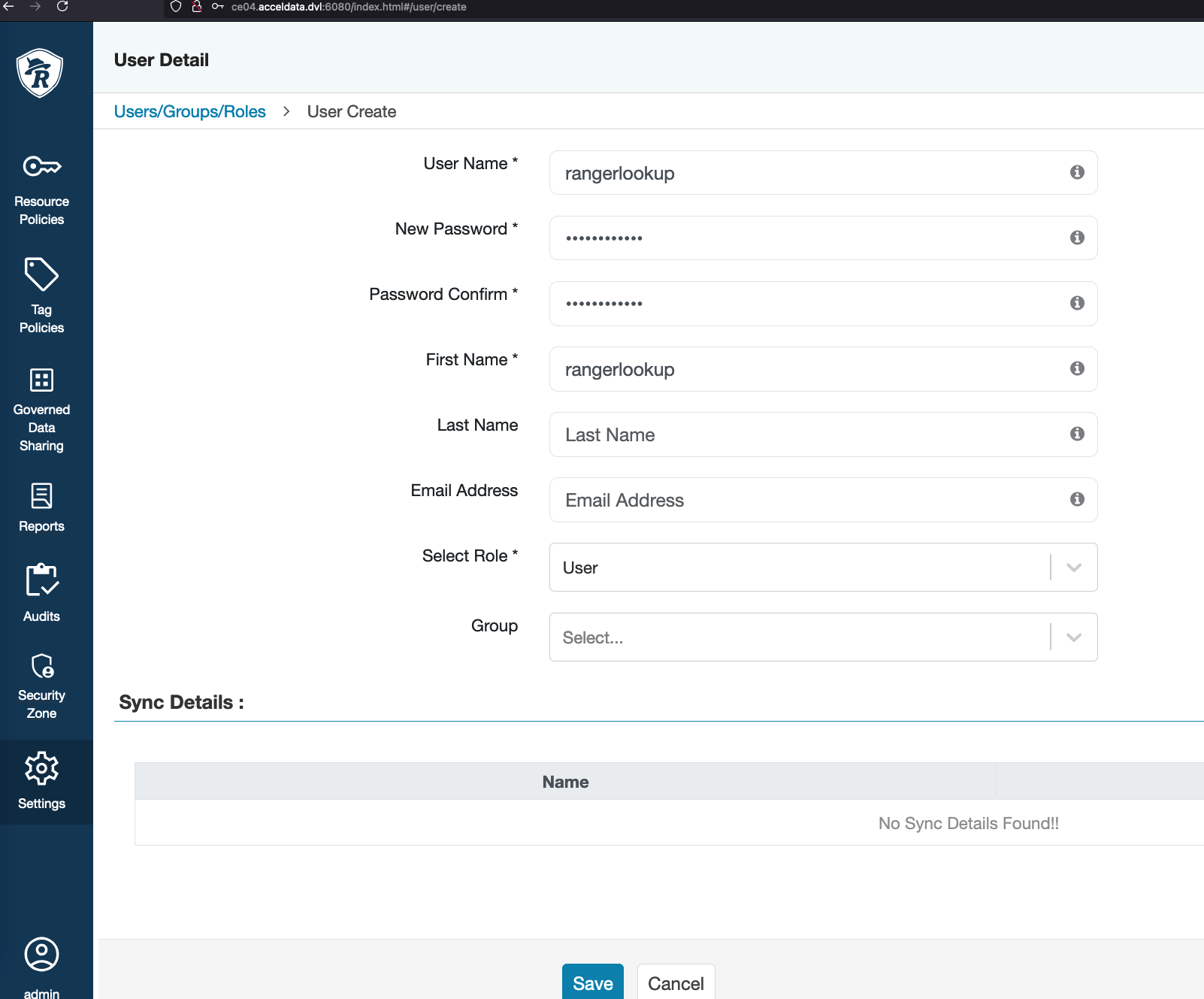
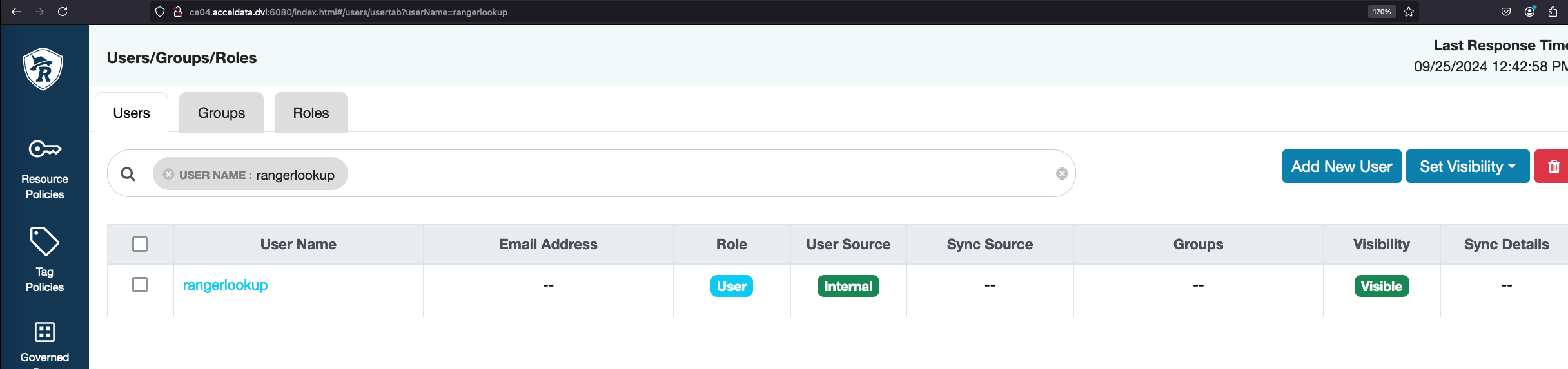
Name node or any service fails - rangerlookup not found
2025-04-25 12:38:32,687 - get_user_call_output returned (0, '{"statusCode":400,"msgDesc":"Operation denied. User name: rangerlookup specified in policy does not exist in ranger admin."}', ' % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n\r 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0\r100 1918 0 124 100 1794 2883 41720 --:--:-- --:--:-- --:--:-- 44604')2025-04-25 12:41:28,288 - get_user_call_output returned (0, '{"statusCode":400,"msgDesc":"Operation denied. User name: rangerlookup specified in policy does not exist in ranger admin."}', ' % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n\r 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0\r100 780 0 124 100 656 1675 8864 --:--:-- --:--:-- --:--:-- 10540')Solution:
Add rangerlookup in the Ranger users list.
Data Node Start Issue
In upgraded clusters, the DataNodes fail to start and hang forever without much logging:
2025-04-24 15:14:58,346 - Writing File['/usr/odp/3.3.6.1-1/hadoop/conf/hadoop-metrics2.properties'] because contents don't match2025-04-24 15:14:58,346 - File['/usr/odp/3.3.6.1-1/hadoop/conf/task-log4j.properties'] {'content': StaticFile('task-log4j.properties'), 'mode': 0o755}2025-04-24 15:14:58,346 - File['/usr/odp/3.3.6.1-1/hadoop/conf/configuration.xsl'] {'owner': 'hdfs', 'group': 'hadoop'}2025-04-24 15:14:58,347 - File['/etc/hadoop/conf/topology_mappings.data'] {'content': Template('topology_mappings.data.j2'), 'owner': 'hdfs', 'group': 'hadoop', 'mode': 0o644, 'only_if': 'test -d /etc/hadoop/conf'}2025-04-24 15:14:58,349 - Writing File['/etc/hadoop/conf/topology_mappings.data'] because contents don't match2025-04-24 15:14:58,349 - File['/etc/hadoop/conf/topology_script.py'] {'content': StaticFile('topology_script.py'), 'mode': 0o755, 'only_if': 'test -d /etc/hadoop/conf'}2025-04-24 15:14:58,351 - Skipping unlimited key JCE policy check and setup since the Java VM is not managed by Ambari2025-04-24 15:14:58,605 - Using hadoop conf dir: /usr/odp/3.3.6.1-1/hadoop/conf2025-04-24 15:14:58,605 - Stack Feature Version Info: Cluster Stack=3.3, Command Stack=None, Command Version=3.3.6.1-1, Upgrade Direction=upgrade -> 3.3.6.1-12025-04-24 15:14:58,611 - Using hadoop conf dir: /usr/odp/3.3.6.1-1/hadoop/confThere will be no more logging after that, will be timed out later.
Solution:
Log on to the Ambari UI → HDFS → configs → Advanced → custom hdfs-rbf-site
dfs.federation.router.rpc-address=0.0.0.0:20010Complete the configurations template for custom hdfs-rbf-site.
DFSRouter component configs list
If the router component is to be used in the ODP cluster, add the below configurations.
Log on to the Ambari UI → HDFS → configs → Advanced → custom hdfs-rbf-site.
dfs.federation.router.admin-address=0.0.0.0:8111dfs.federation.router.admin-bind-host=0.0.0.0dfs.federation.router.admin.enable=truedfs.federation.router.admin.handler.count=1dfs.federation.router.cache.ttl=1mdfs.federation.router.client.allow-partial-listing=truedfs.federation.router.client.mount-status.time-out=1sdfs.federation.router.client.reject.overload=falsedfs.federation.router.client.retry.max.attempts=3dfs.federation.router.client.thread-size=32dfs.federation.router.connect.max.retries.on.timeouts=0dfs.federation.router.connect.timeout=2sdfs.federation.router.connection.clean.ms=10000dfs.federation.router.connection.creator.queue-size=100dfs.federation.router.connection.min-active-ratio=0.5fdfs.federation.router.connection.pool-size=1dfs.federation.router.connection.pool.clean.ms=60000dfs.federation.router.dn-report.cache-expire=10sdfs.federation.router.dn-report.time-out=1000dfs.federation.router.file.resolver.client.class=org.apache.hadoop.hdfs.server.federation.resolver.MountTableResolverdfs.federation.router.handler.count=10dfs.federation.router.handler.queue.size=100dfs.federation.router.heartbeat-state.interval=5sdfs.federation.router.heartbeat.enable=truedfs.federation.router.heartbeat.interval=5000dfs.federation.router.http-address=0.0.0.0:50071dfs.federation.router.http-bind-host=0.0.0.0dfs.federation.router.http.enable=truedfs.federation.router.https-address=0.0.0.0:50072dfs.federation.router.https-bind-host=0.0.0.0dfs.federation.router.metrics.class=org.apache.hadoop.hdfs.server.federation.metrics.FederationRPCPerformanceMonitordfs.federation.router.metrics.enable=truedfs.federation.router.monitor.localnamenode.enable=truedfs.federation.router.mount-table.cache.enable=truedfs.federation.router.mount-table.cache.update=truedfs.federation.router.mount-table.cache.update.client.max.time=5mdfs.federation.router.mount-table.cache.update.timeout=1mdfs.federation.router.mount-table.max-cache-size=10000dfs.federation.router.namenode.heartbeat.enable=truedfs.federation.router.namenode.resolver.client.class=org.apache.hadoop.hdfs.server.federation.resolver.MembershipNamenodeResolverdfs.federation.router.quota-cache.update.interval=60sdfs.federation.router.quota.enable=falsedfs.federation.router.reader.count=1dfs.federation.router.reader.queue.size=100dfs.federation.router.rpc-address=0.0.0.0:20010dfs.federation.router.rpc-bind-host=0.0.0.0dfs.federation.router.rpc.enable=truedfs.federation.router.safemode.enable=truedfs.federation.router.safemode.expiration=3mdfs.federation.router.safemode.extension=30sdfs.federation.router.secret.manager.class=org.apache.hadoop.hdfs.server.federation.router.security.token.ZKDelegationTokenSecretManagerImpldfs.federation.router.store.connection.test=60000dfs.federation.router.store.driver.class=org.apache.hadoop.hdfs.server.federation.store.driver.impl.StateStoreZooKeeperImpldfs.federation.router.store.enable=truedfs.federation.router.store.membership.expiration=300000dfs.federation.router.store.membership.expiration.deletion=-1dfs.federation.router.store.router.expiration=5mdfs.federation.router.store.router.expiration.deletion=-1dfs.federation.router.store.serializer=org.apache.hadoop.hdfs.server.federation.store.driver.impl.StateStoreSerializerPBImplNode manager start failed
2025-04-25 12:00:41,360 ERROR nodemanager.NodeManager (NodeManager.java:initAndStartNodeManager(965)) - Error starting NodeManagerorg.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.lang.ClassNotFoundException: org.apache.spark.network.yarn.YarnShuffleService at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices.initAuxService(AuxServices.java:482) at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices.serviceInit(AuxServices.java:758) at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164) at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:109) at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.serviceInit(ContainerManagerImpl.java:327) at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164) at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:109) at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceInit(NodeManager.java:494) at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164) at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartNodeManager(NodeManager.java:962) at org.apache.hadoop.yarn.server.nodemanager.NodeManager.main(NodeManager.java:1042)Caused by: java.lang.ClassNotFoundException: org.apache.spark.network.yarn.YarnShuffleService at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:581) at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178) at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:527) at org.apache.hadoop.util.ApplicationClassLoader.loadClass(ApplicationClassLoader.java:189) at org.apache.hadoop.util.ApplicationClassLoader.loadClass(ApplicationClassLoader.java:157) at java.base/java.lang.Class.forName0(Native Method) at java.base/java.lang.Class.forName(Class.java:398) at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxiliaryServiceWithCustomClassLoader.getInstance(AuxiliaryServiceWithCustomClassLoader.java:165) at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices.createAuxServiceFromLocalClasspath(AuxServices.java:242) at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices.createAuxService(AuxServices.java:271) at org.apache.hadoop.yarn.server.nodemanager.containermanager.AuxServices.initAuxService(AuxServices.java:452)Solution:
Remove the following from yarn configurations:
spark_shufflefromyarn.nodemanager.aux-services
Remove the following from
Custom yarn-site:
yarn.nodemanager.aux-services.spark2_shuffle.classyarn.nodemanager.aux-services.spark2_shuffle.classpathyarn.nodemanager.aux-services.spark_shuffle.classpathyarn.nodemanager.aux-services.spark_shuffle.classKafka
After completing the Ambari upgrade, during the express upgrade, Kafka needs to be up and running in a healthy mode. However, Kafka might be in a stopped state due to the following errors:
raise Fail("Configuration parameter '" + self.name + "' was not found in configurations dictionary!")resource_management.core.exceptions.Fail: Configuration parameter 'kafka-connect-distributed' was not found in configurations dictionary!These issues occur because Kafka Connect and MirrorMaker were added in this release.
Solution
To start Kafka, add the following configurations in Ambari:
Custom kafka-mirrormaker2-common
replication.factor =1
Custom kafka-mirrormaker2-destination
replication.enabled=truedestination.cluster.name=desttopics.whitelist=.*
Custom kafka-mirrormaker2-source
replication.enabled=truesource.cluster.name=sourcetopics.whitelist=.*
Custom kafka-connect-distributed
bootstrap.servers=localhost:6667
Proceed with restarting the Kafka service. It must start smoothly.
###