Until now, JupyterHub has supported only a single kernel, i.e., IPython, which primarily enables Python-based workflows. Running other technologies or connecting to services such as ODP Spark required additional prerequisites and manual configuration steps, as described here: Documentation for Spark Notebook Examples.
This release introduces improvements aimed at simplifying and expanding the JupyterHub experience by providing additional kernels that support multiple languages, connectors, libraries, and frameworks. This documentation/task specifically focuses on the addition of these new kernels.
Navigation
Login to Jupyterhub.
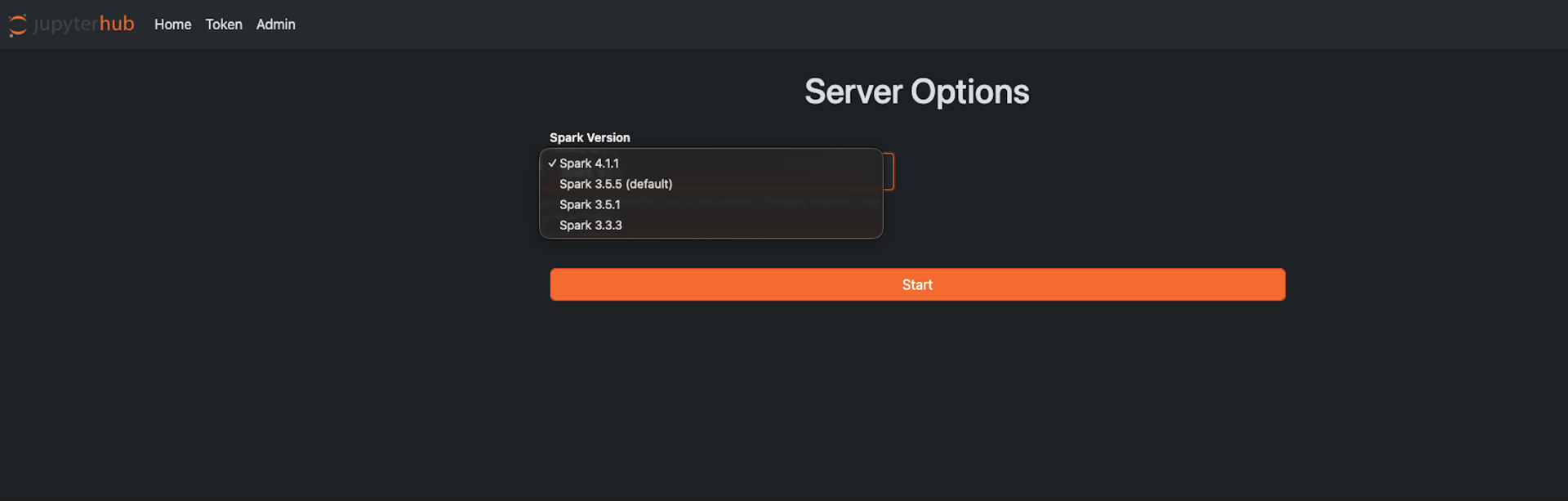
Select the Spark version.
The Launcher UI is displayed with Notebooks, Consoles and other configurations.

Kernel support with Spark 4 is currently limited. While PySpark and SparkR kernels are fully supported and function as expected, the Scala kernel in JupyterHub is currently known to be incompatible with Spark 4. Support for the Scala kernel with Spark 4 will be addressed in a future release.
Kernels / Interpreters
The following kernels are available in JupyterHub and can be used with the selected ODP Spark 3 environment (with Spark 4 support coming soon) after the user logs in.
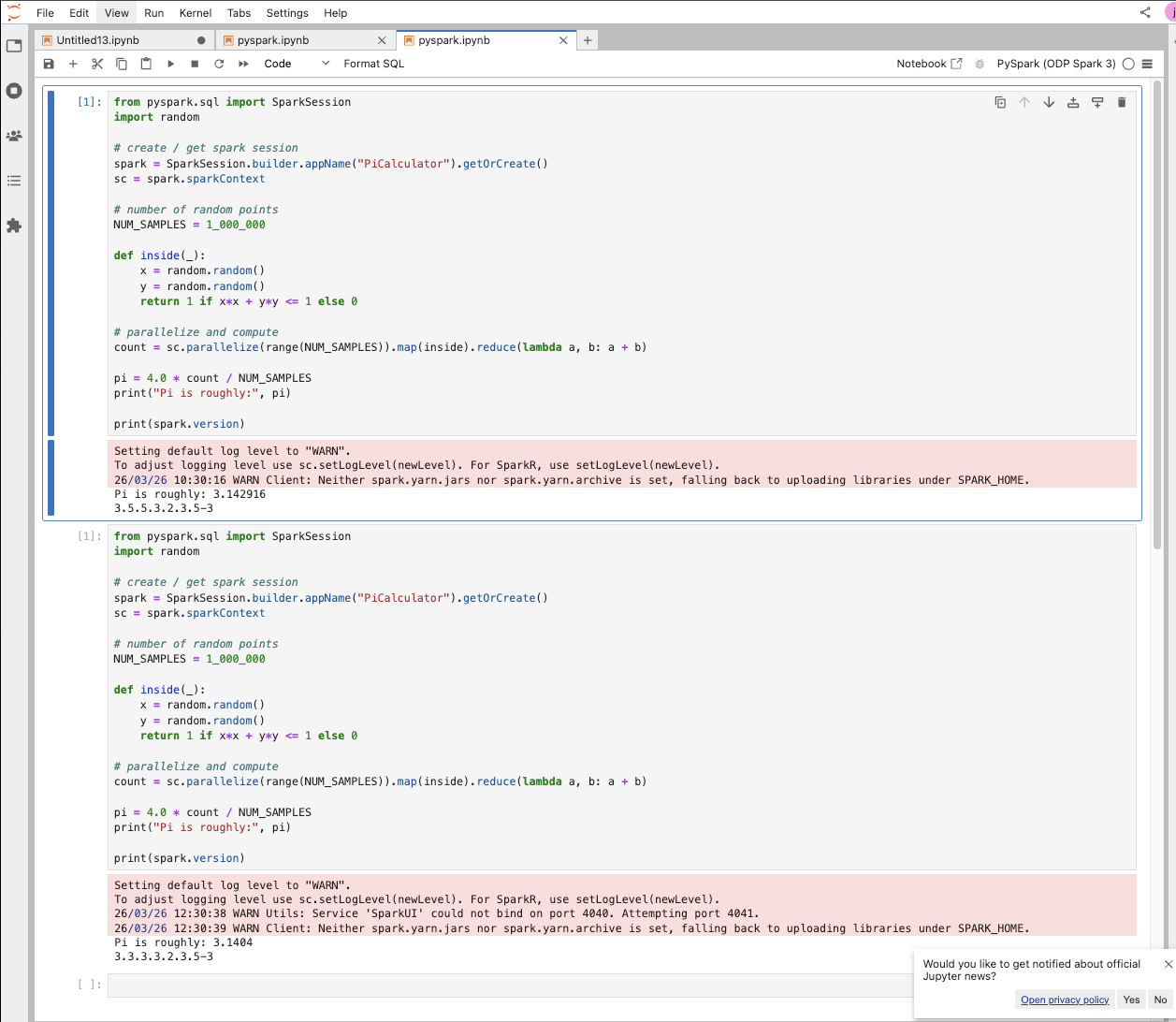
PySpark
Example Job:
The following screenshot shows the output from the above run. As shown, different Spark versions were printed because the user stopped the server and restarted it after switching the Spark version.
Example Runs:
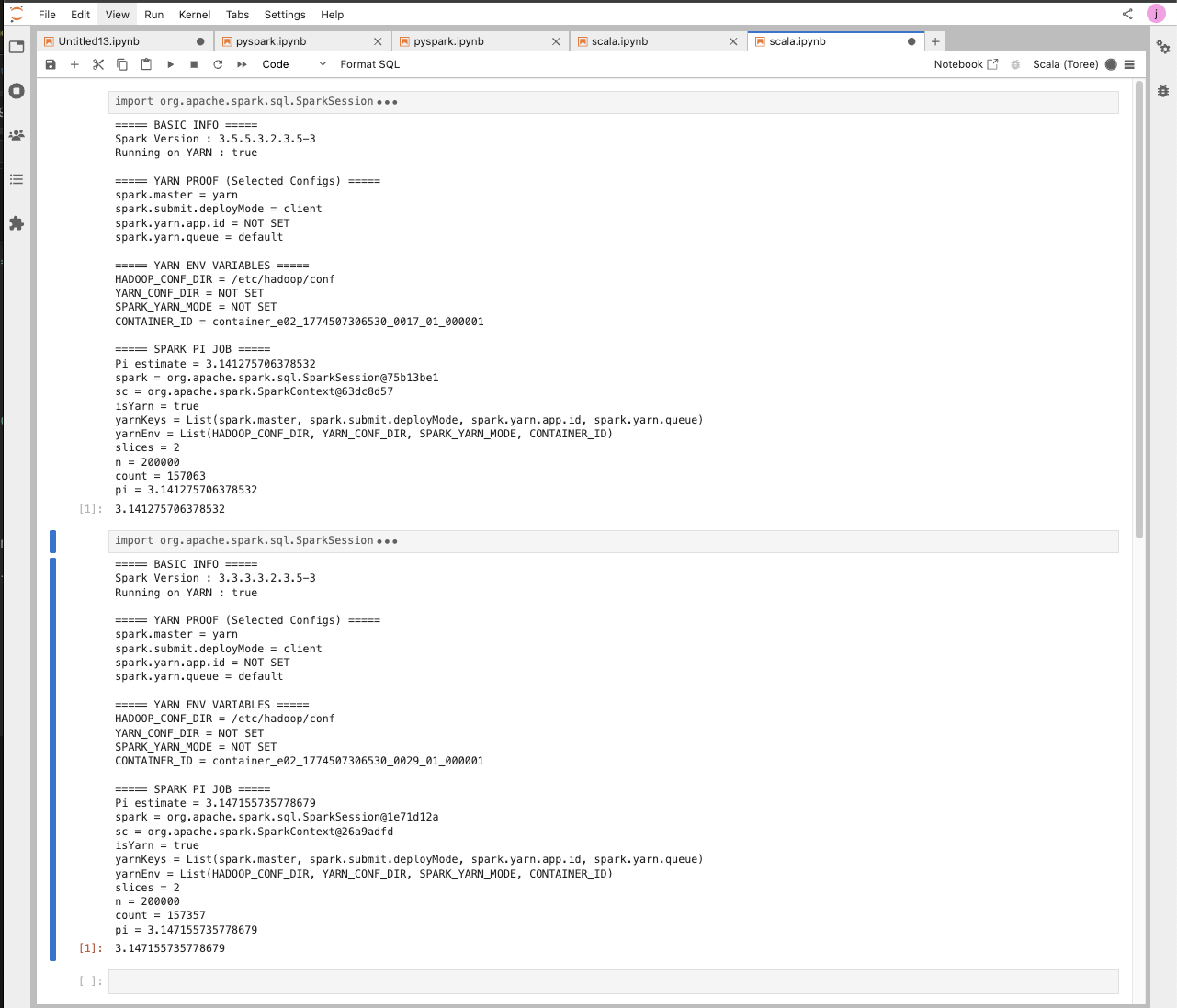
Scala Spark
Example Job:
Example Runs:
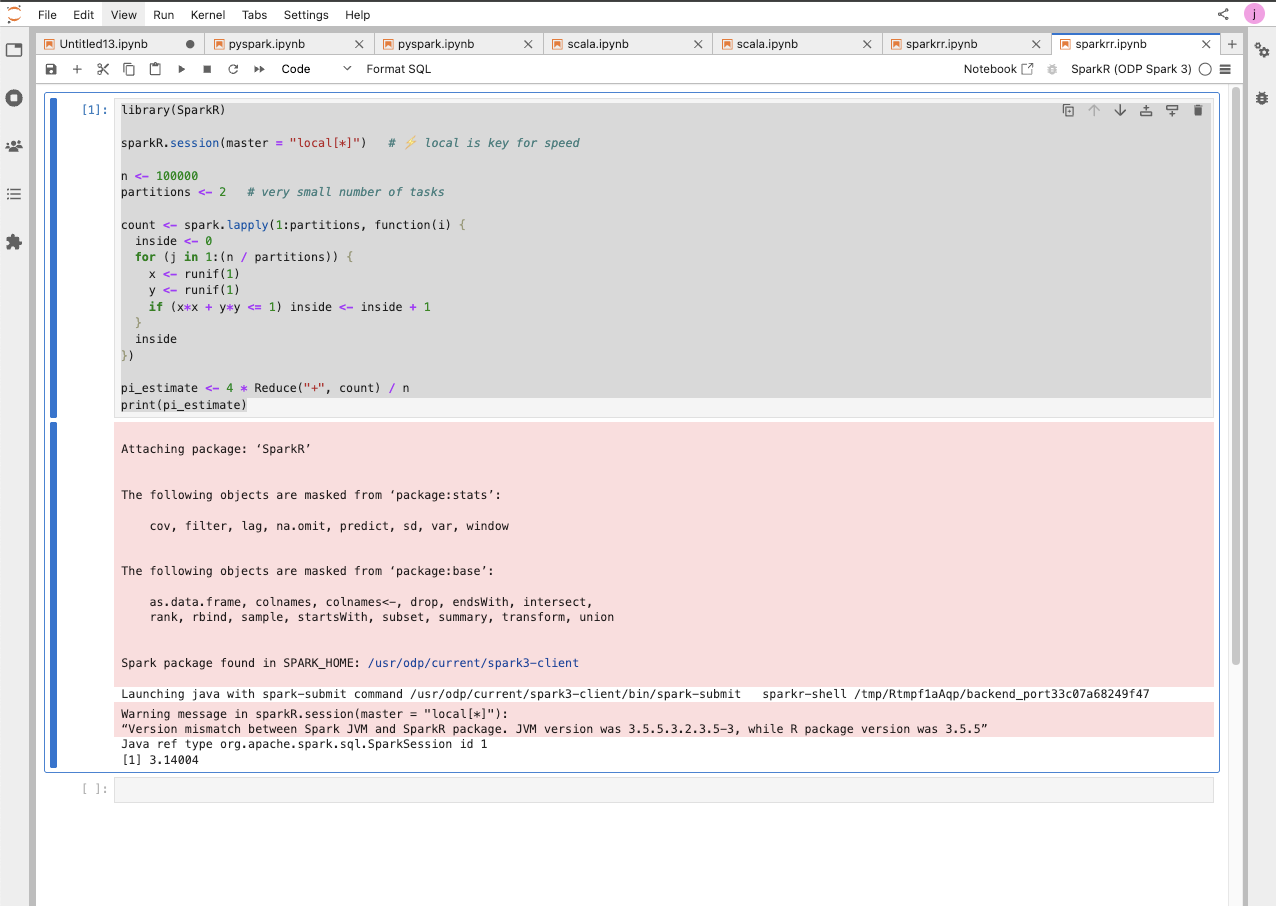
Spark R
Example Job:
Example Runs:
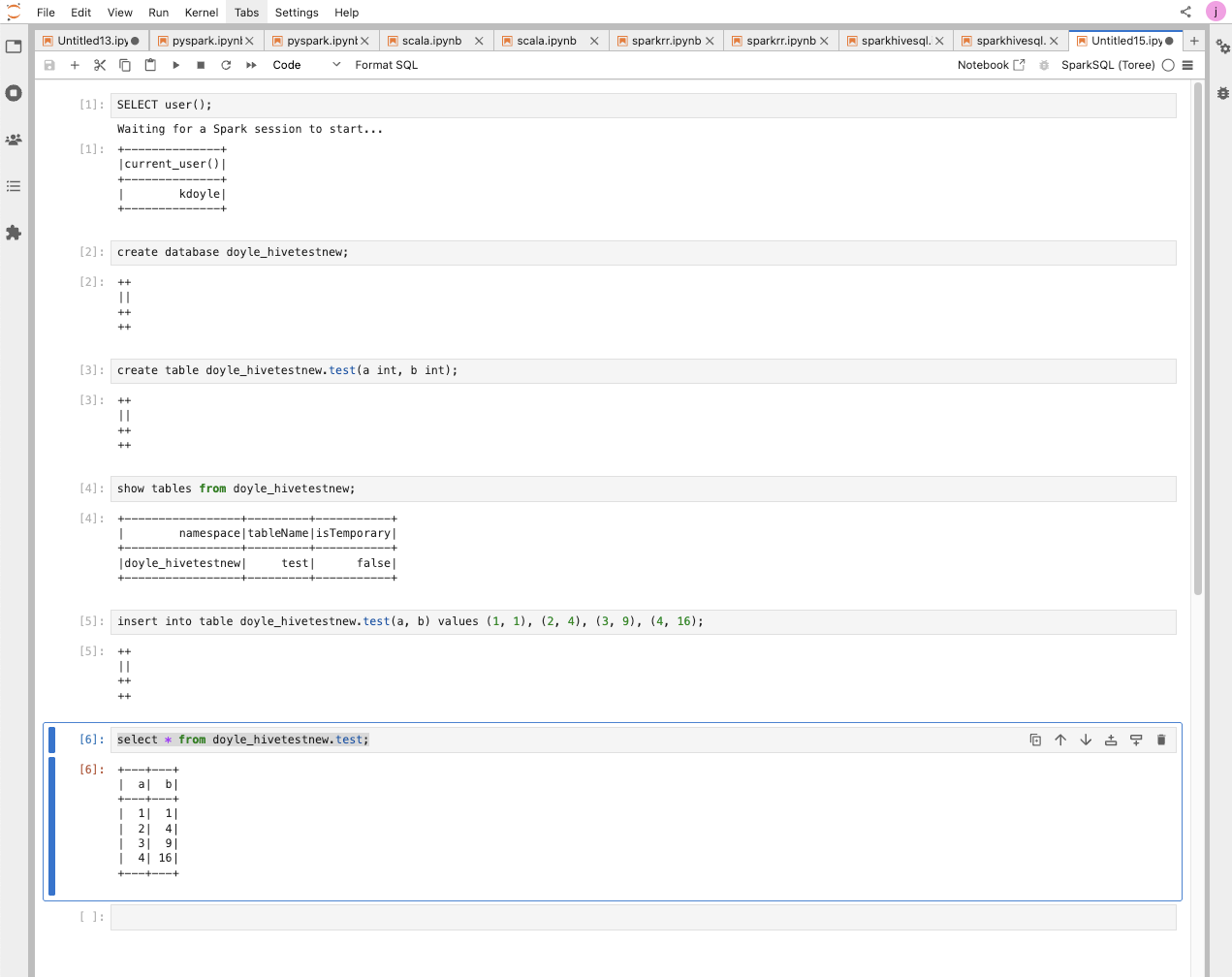
Spark SQL
Example Jobs:
Example Runs:
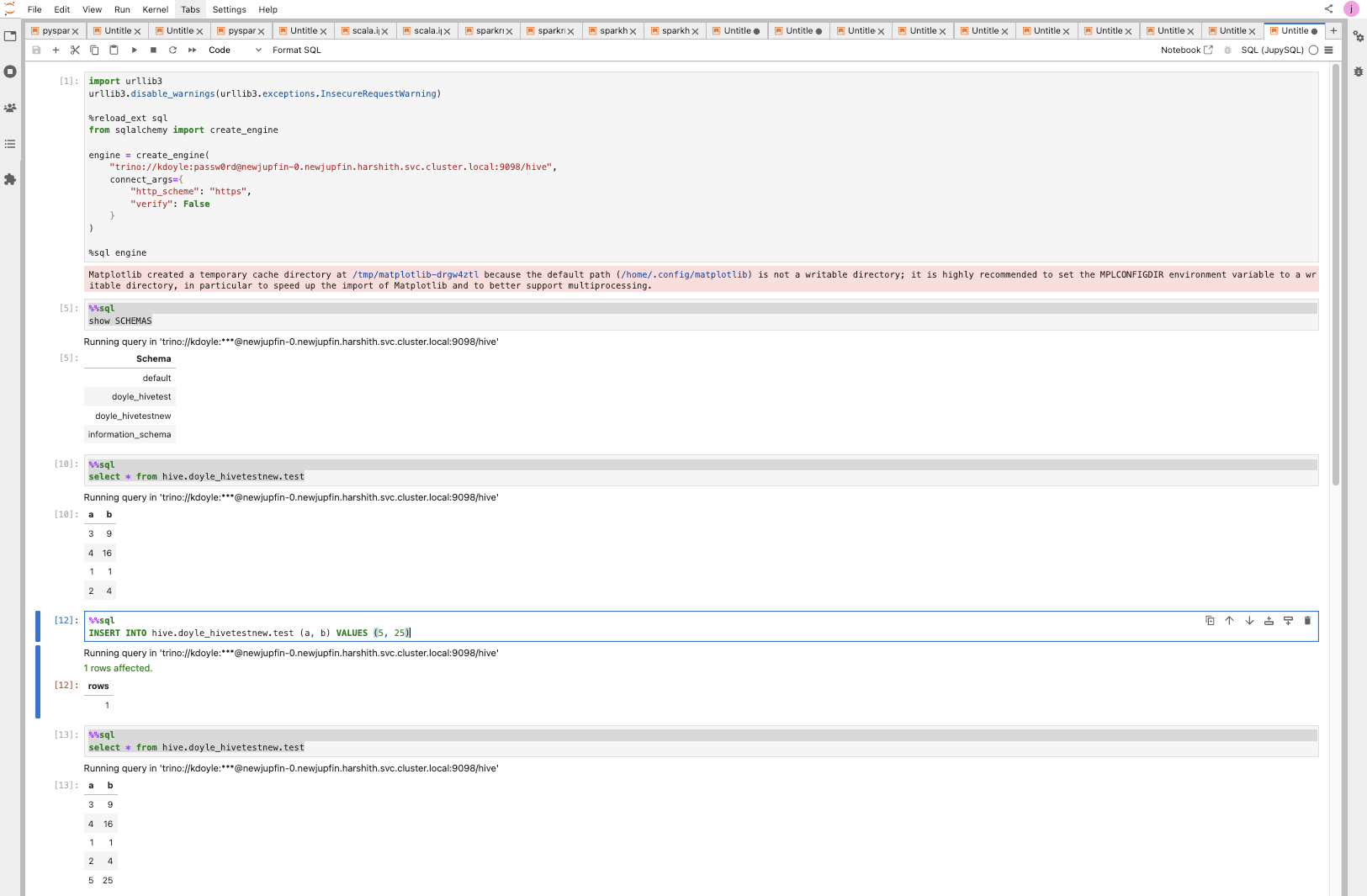
JupySQL
Trino
Create a connection.
You should now be able to access a Trino SQL–like shell by simply adding %%sql at the top of each notebook cell, for example:
Example Run:
This can be extended to any sqlalchemy compatible connector or database.