Starting, Stopping, or Restarting a Crawler
When you start a crawler, metadata from a data lake is crawled into your data source. Similarly, when you stop a crawler, the crawler stops crawling metadata from a data lake.
Start Crawler
To start crawlers from crawling metadata, do the following:
- Click the Data Source tab from the Data Sources window.
- Click the
icon in the selected data source. - Click Start Crawler. A pop-up message "Crawler Running Successfully" is displayed.
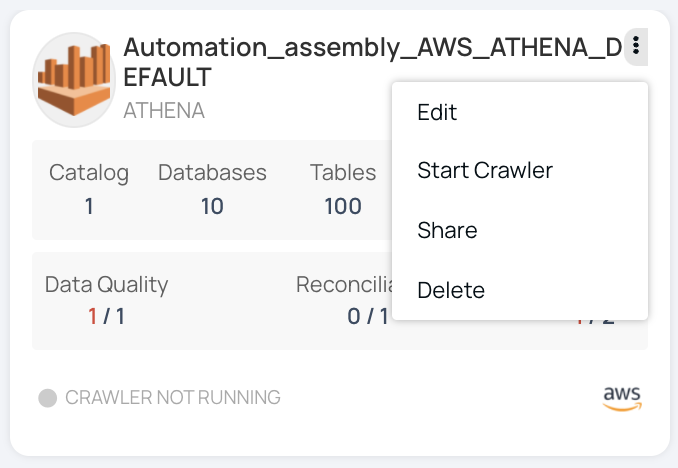
Start Crawler
Single Asset Crawling
Acceldata provides you with an option to crawl either a single asset or select specific assets to add to an existing Snowflake, Redshift, or Databricks data source. This way, you can avoid the need to crawl the entire data source whenever new tables, columns, schemas, catalogs, or databases are added, saving valuable time and resources.
Performing this action is not possible through the Torch user interface; instead, it must be executed via the API by appending the 'assets' variable to the API request URL, followed by the asset UIDs.
For example, suppose you have an existing data source named 'Databricks_Unity_Catalog_DS' and you wish to crawl only the 'employee3' table within it. The request URL would appear as follows: https://acceldata/catalog-server/api/crawler/Databricks_Unity_Catalog_DS assets=Databricks_Unity_Catalog_DS.torch_catalog.employee.employee3.
In a similar manner, you can include multiple assets by separating their UIDs with commas.
View Crawler Logs
The current logs that are being generated by the analysis service that is operating on the data plane side can be viewed while crawlers have started to run. You will also be able to view the running logs on data sources that are generated by the crawlers.
To utilize this, perform the following:
- Start the Crawler by clicking on the ellipsis button on the right side of the data source
- Navigate and click on the Start Crawler option. The status will change to Crawler Starting.
- After the Crawler status changes to the Crawler Running. Click on View Crawler Logs.

Stop Crawler
To stop crawlers from crawling metadata, do the following:
- Click the Data Source tab from the Data Sources window.
- Click the
icon in the selected data source. - Click Stop Crawler. A pop-up message "Crawler Stop Successful" is displayed.
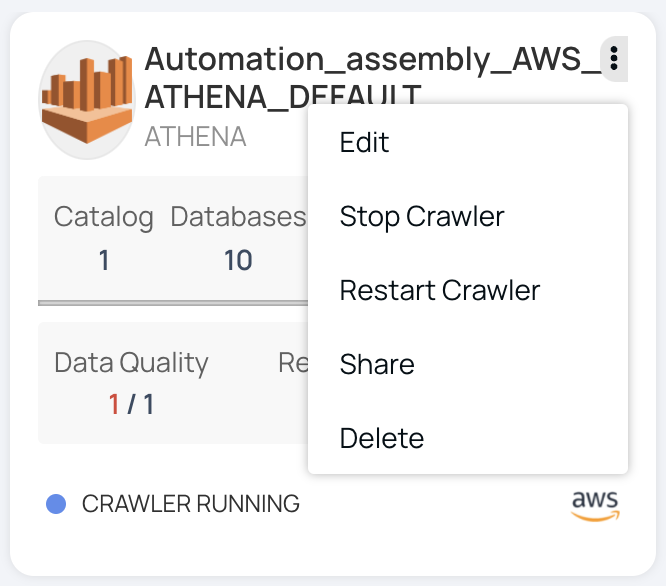
Stop Crawler
Restart Crawler
To restart a crawler, do the following:
- Click the Data Source tab from the Data Sources page.
- Click the
icon in the selected data source. - Click Restart Crawler. A pop-up message "Crawler Restart Successful" is displayed.
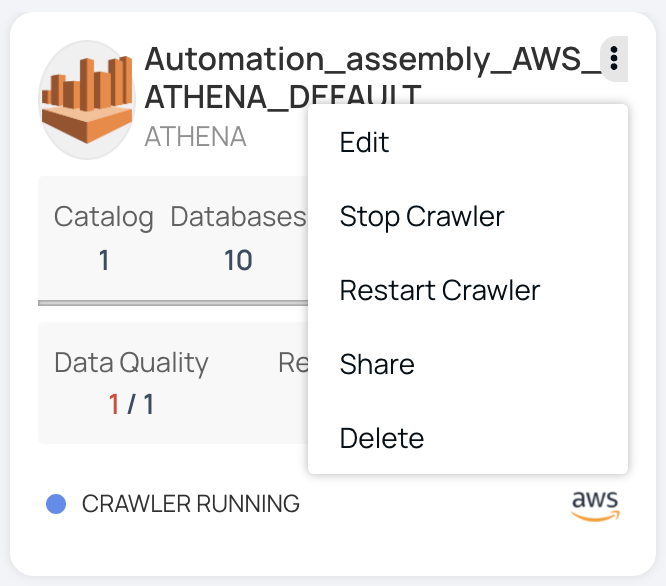
Restart Crawler
REST APIs
The process of extracting data from data sources using a program is known as crawling.
Start Crawler
The POST Start Crawler method initiates crawling in a specified data source.
Resource URL:
POST /catalog-server/api/crawler/{assemblyName}
Get Crawler Status
The GET Crawler Status method returns the stage of crawling that is currently in progress. For example, if a data source's crawling is still in progress, the crawling process's status will be returned as RUNNING.
Resource URL:
GET /catalog-server/api/crawler/{assemblyName}