Torch uses Apache Spark for running jobs. Torch can deploy a Spark cluster on Kubernetes or you can also connect to an existing Apache Livy cluster in your existing Hadoop infrastructure or you can connect to your databricks cluster. You can configure the settings for Spark support here.
Torch allows the user to configure the Spark Job Resources at the asset level. To configure the job resources at the asset level, click the Settings tab of the asset, and select Job Resources.
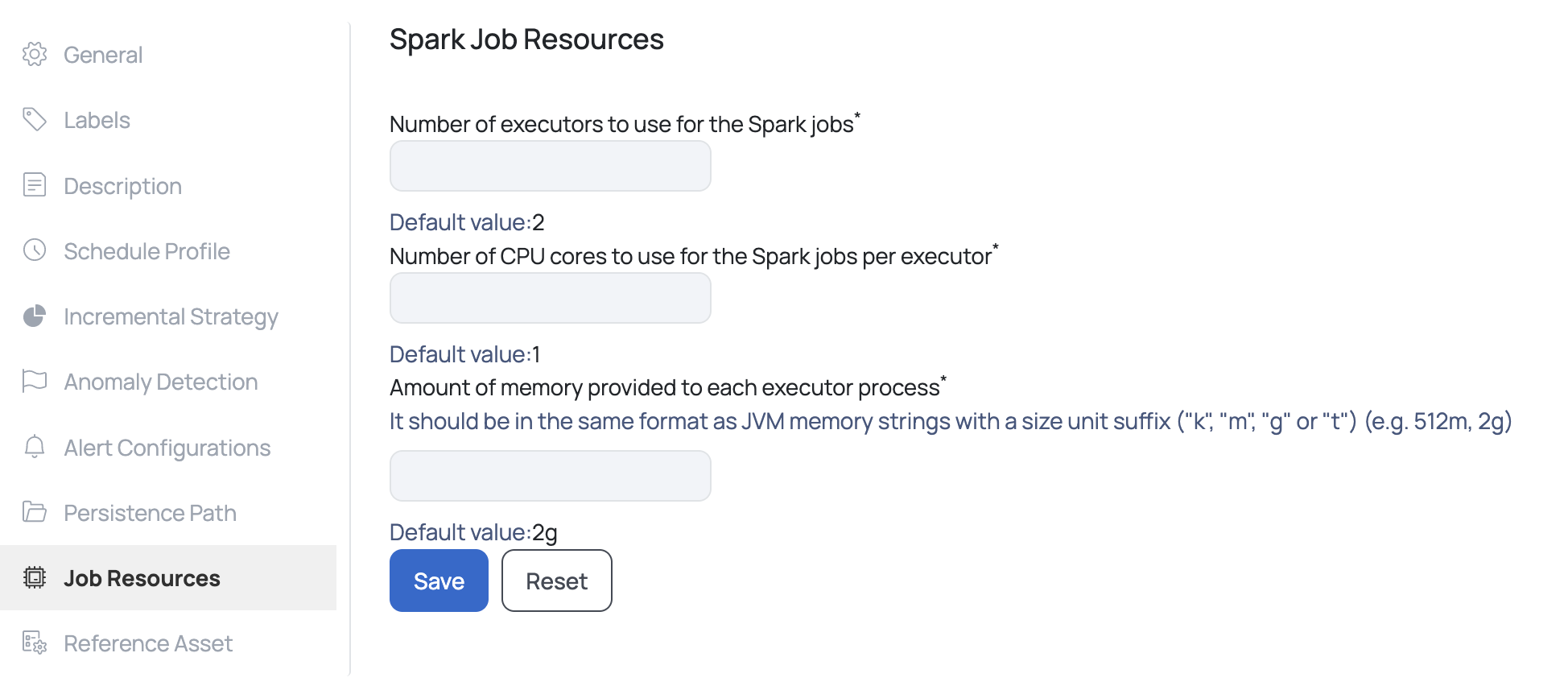
If the option, Use Existing Spark Cluster was selected during the deployment, then you must enter the following values:
- Number of executors: Number of executors that are spawned for each job
- Number of CPU cores: Number of CPU cores per executor
- Memory per executor: Amount of memory to be allocated to each executor
If the option, Use Databricks was selected during the deployment, then you must enter the following values:
- Minimum Number of Worker Nodes: Minimum number of worker nodes required
- Maximum Number of Worker Nodes: Maximum number of worker nodes required
- Databricks Cluster Worker Type: The type of worker node i.e., Standard, High Concurrency, and Single Node
- Databricks Cluster Driver Type: The type of driver node.
Click the Save button.
Was this page helpful?