Google | BigQuery
BigQuery is a server-less data warehouse developed by Google. You can use BigQuery to analyze huge amounts of data. BigQuery supports query operations through American National Standard Institute's Structured Query Language (ANSI SQL). In ADOC, you can use BigQuery as a data source to analyze your data present in BigQuery.
BigQuery in ADOC
ADOC provides data reliability capability for data stored in your BigQuery data source. You must create a data plane or use an existing data plane to add BigQuery as a data source in ADOC. Once you add BigQuery as a data source, you can view the details of your assets in BigQuery database in the Data Reliability section in ADOC.
Prerequisites
Before adding BigQuery as a data source in the ADOC platform, ensure the appropriate permissions are granted to the service account used for integration.
Required Permissions
Dataset-level permissions recommended (not project-level): Instead of granting broad access at the project level, it is sufficient—and more secure—to grant the following roles at the dataset level:
BigQuery Data Viewer— For datasets you want to monitor or analyze.BigQuery Data Editor— Only needed if temporary tables are created (see below).
When Are Temporary Tables Created?
Temporary tables are used only during Spark-based processing in ADOC. This includes:
- Working with BigQuery views (or external tables) using Spark
- Using SQL-based policies with Spark as the processing engine
- Any scenario where Spark requires intermediate computation or staging
If Pushdown processing is used:
- Temporary tables are not created
- No additional
Data Editorpermissions are required, even for views or external tables
If you're unsure whether Spark processing is used (vs. Pushdown), or if your workflows involve BigQuery views or SQL-based policies, it's safest to grant the BigQuery Data Editor role on the specific dataset intended for temporary/intermediate table creation.
Optional: Multi-Project Setup (for advanced use cases)
To better manage roles and access boundaries, you may organize your BigQuery resources across multiple GCP projects:
- Project A – For service account provisioning and secrets
- Project B – As the primary data source
- Project C – For staging or temporary processing
You may set up the Read or Write privileges in your BigQuery configuration by understanding the flow of organized data access and processing, with clear boundaries between service, source, and temporary session management.

Multi Project Permission
Permissions
Project used as a Service:
| Roles or Permissions |
|---|
| BigQuery Read Session User |
| BigQuery Job User |
secretmanager.versions.access
Project used as a Data source:
| Roles or Permissions |
|---|
| BigQuery Data Viewer |
| Storage Object Viewer |
Project used for Temp Table:
| Roles or Permissions |
|---|
| BigQuery Data Editor |
Steps to Add BigQuery as a Data Source
To add BigQuery as a Data source:
- Click Register from the left pane.
- Click Add Data Source.
- Select the BIGQUERY Data Source. BigQuery Data Source basic Details page is displayed.
- Enter a name for the data source in the Data Source name field.
- (Optional) Enter a description for the data source in the Description field.
- Select a Data Plane from the Select Data Plane drop-down menu.
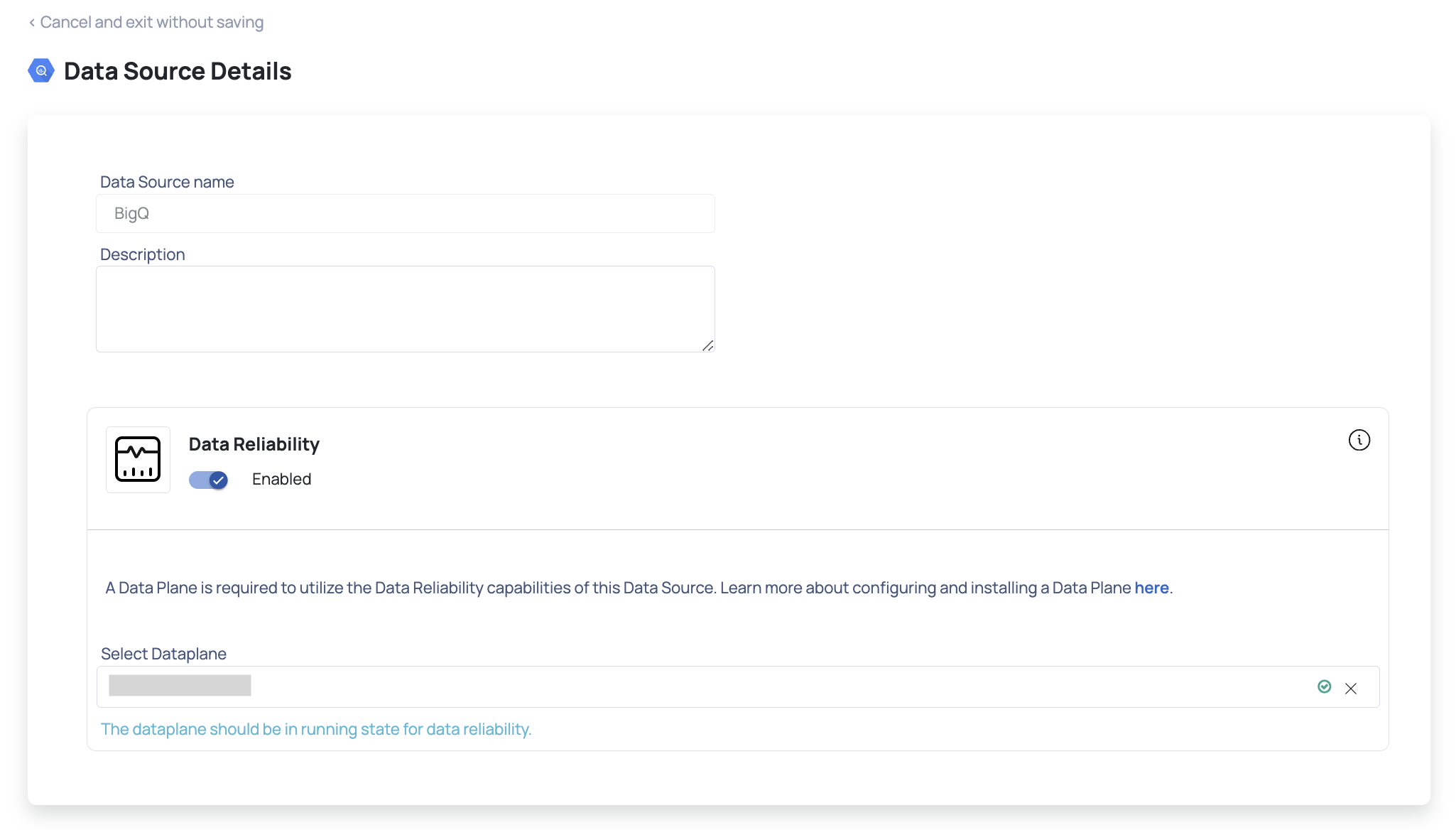
To create a new Data Plane, click Setup Dataplane.
You must either create a Data Plane or use an existing Data Plane to enable the Data Reliability capability.
- Click Next. The BigQuery Connection Details page is displayed.
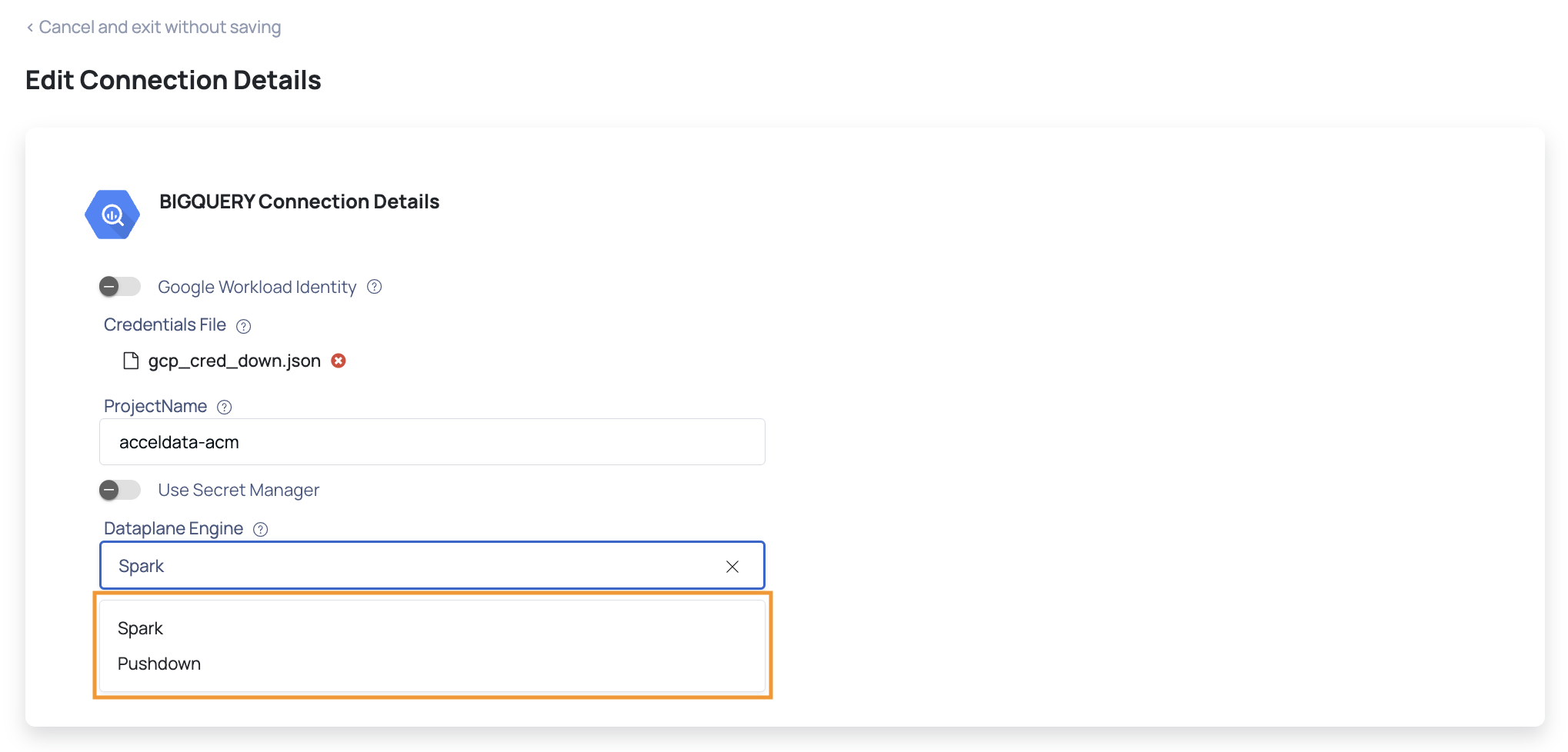
- Upload the credentials file of your GCS account.
- Enter the name of a project, in the Project Name field.
- Select the Dataplane Engine, either Spark or Pushdown Data Engine, for profiling and data quality.
- Click Test Connection.

If your credentials are valid, you receive a
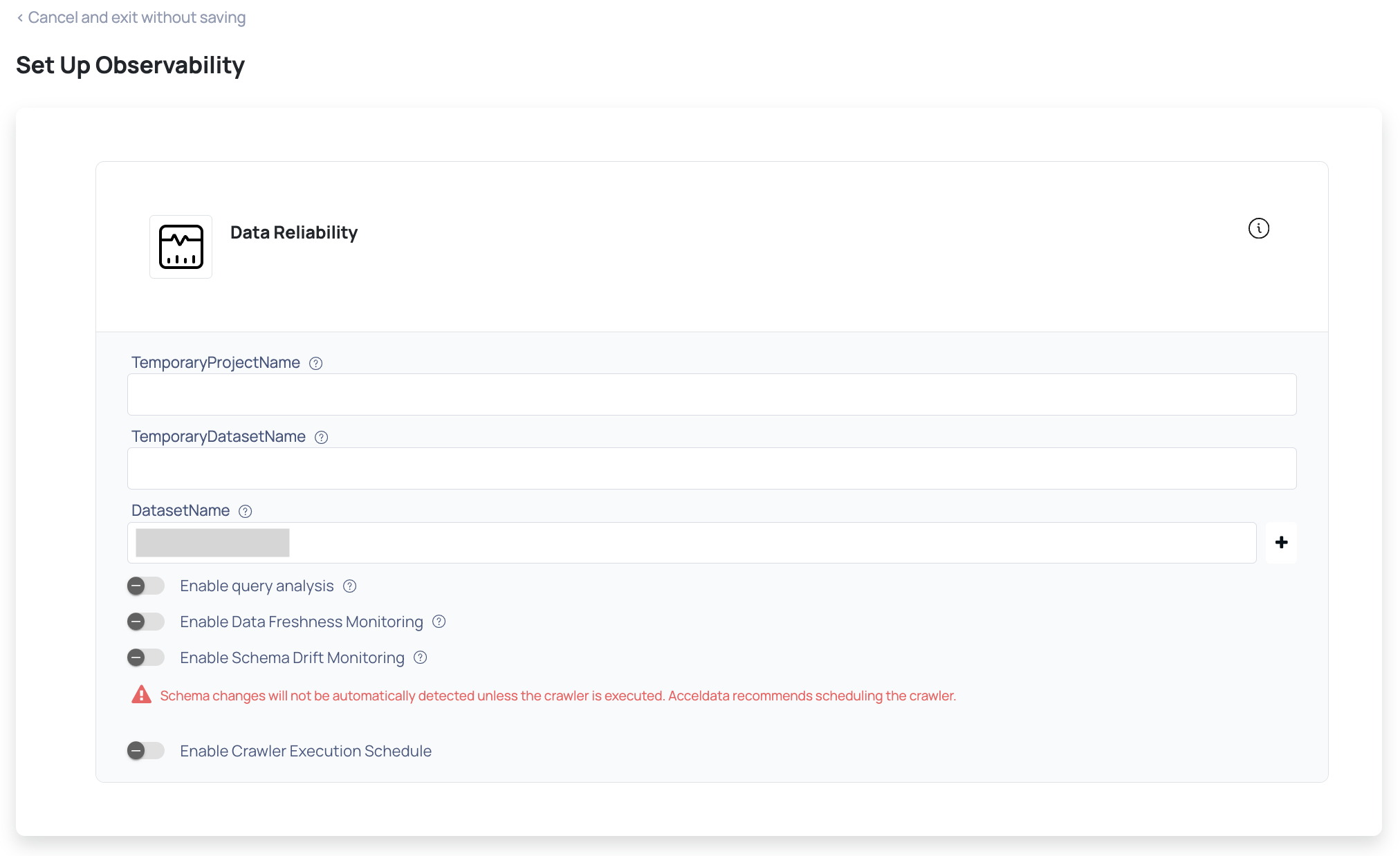
- Click Next. The Observability Setup page is displayed.
- Specify the name of the project for temporary data processing, in the Temporary Project Name and Temporary Dataset Name in the field.
- Enter the name of the dataset, in the Dataset Name field.
- Enable Crawler Execution Schedule: Turn on this toggle switch to select a time tag and time zone to schedule the execution of crawlers for Data Reliability.
- Click Submit.
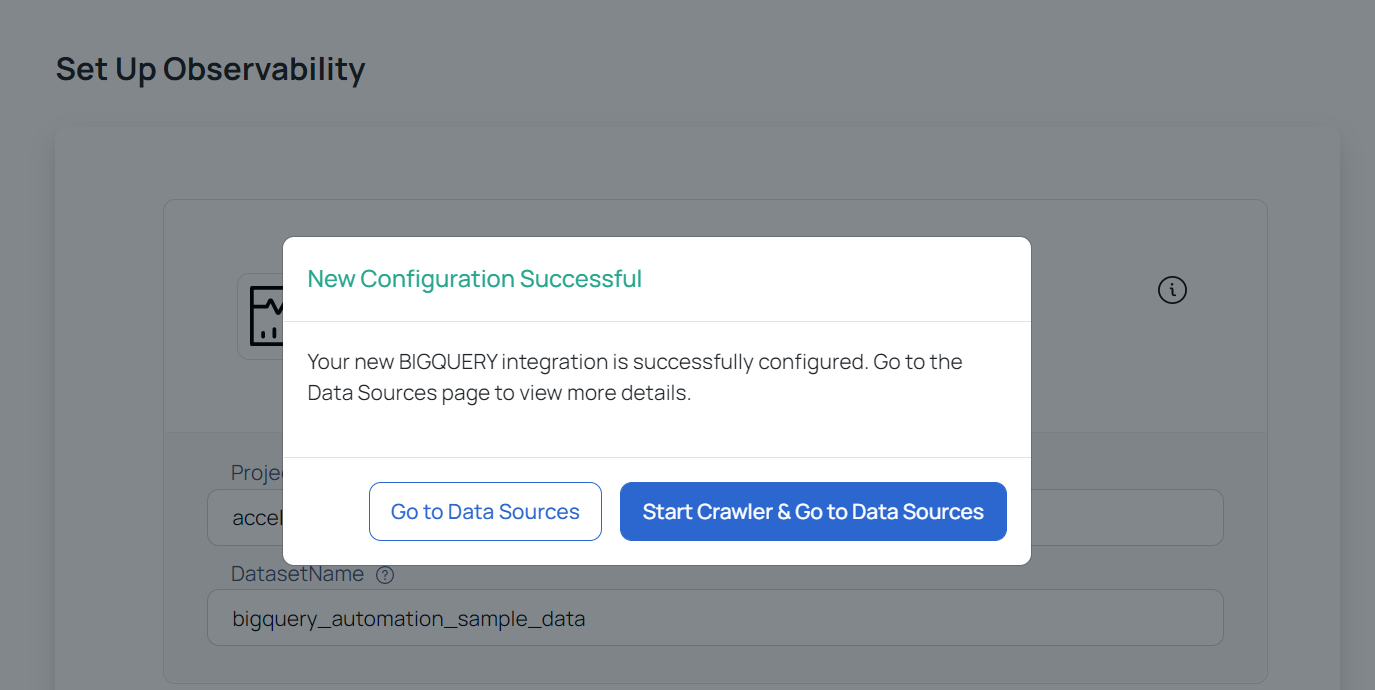
BigQuery is now added as a data source. You can choose to crawl your BigQuery Data Source now or later.
You can see that a new card is created for BigQuery on the data sources page. This card displays the crawler status and other details of your BigQuery data source.