Apache | Kafka
Apache Kafka is a robust open-source distributed streaming system that facilitates real-time data pipelines and integration at scale. It is crucial for handling large-scale data streams efficiently. Apache Kafka allows for the seamless processing of massive amounts of data in real-time, making it a valuable tool for companies looking to analyze and act on data quickly. Its fault-tolerant design ensures data integrity even in the event of node failures, making it a reliable choice for mission-critical applications. Overall, Apache Kafka plays a vital role in modern data architecture, enabling businesses to harness the power of big data for improved decision-making and operational efficiency.
ADOC Kafka Integration
ADOC supports Kafka integration in various modes and data formats such as JSON, AVRO, and Confluent AVRO, catering to different real-time data feeding requirements for AI and ML models.
- Full Mode: Processes entire Kafka data to address data quality and profiling.
- Incremental Mode: Processes only recent data, supporting two strategies:
- Offset Based: Uses checkpoints to process only new data since the last successful run.
- Timestamp Based: Starts processing from a specified timestamp, useful for omitting historical data.
Steps to Integrate Kafka as a Data Source
To add Kafka as a data source:
- Click the Register icon from the left pane.
- Click Add Data Source button.
- Select the Kafka data source. The Data Source Details page is displayed.
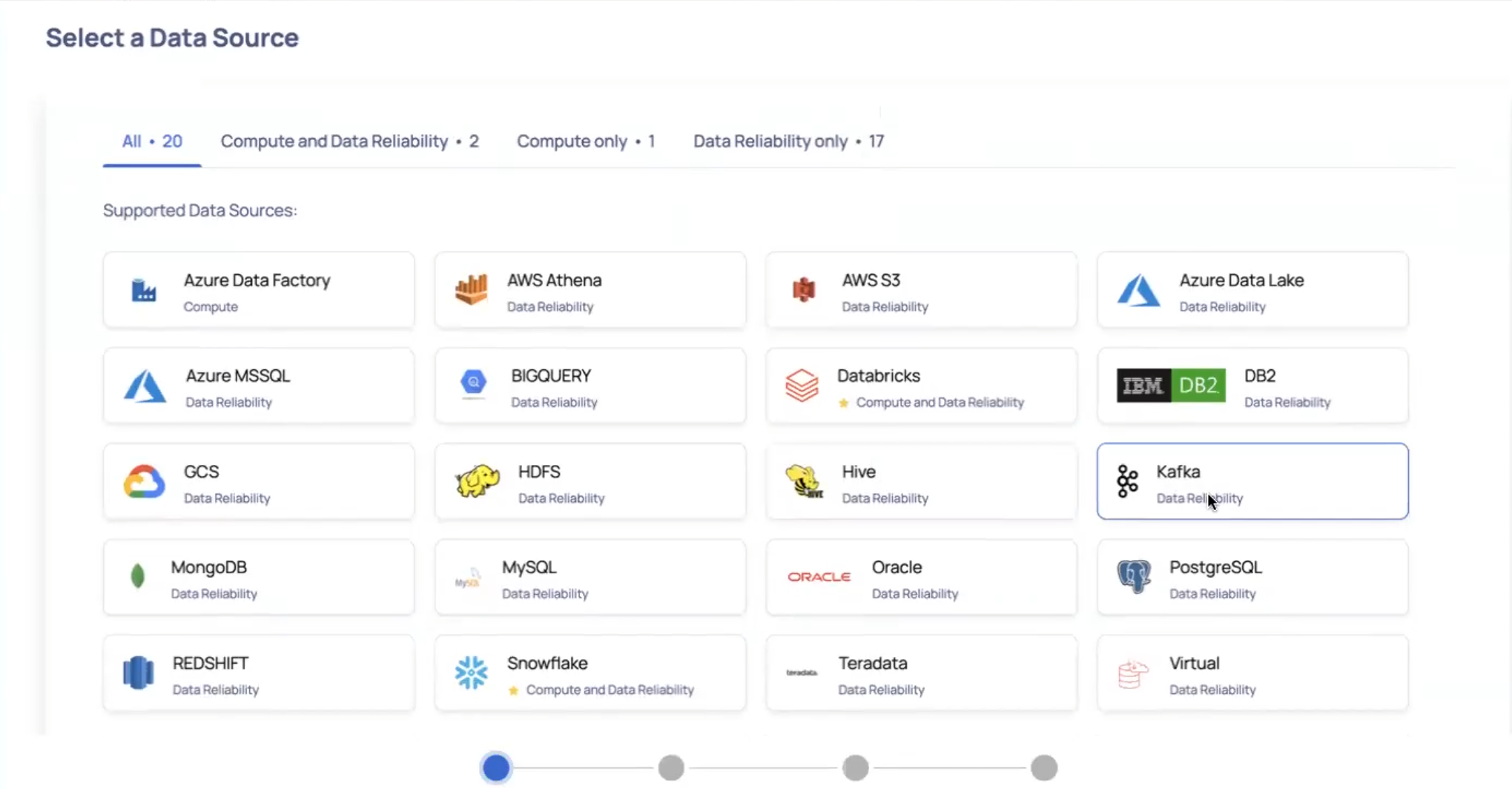
- Enter a name for the data source in the Data Source name field.
- (Optional) Enter a description for the Data Source in the Description field.
- Enable the Data Reliability capability by switching on the toggle switch.
- Select a Data Plane from the Select Data Plane drop-down menu. To create a new Data Plane, click Setup Dataplane.
You must either create a Data Plane or use an existing Data Plane to enable the Data Reliability capability.
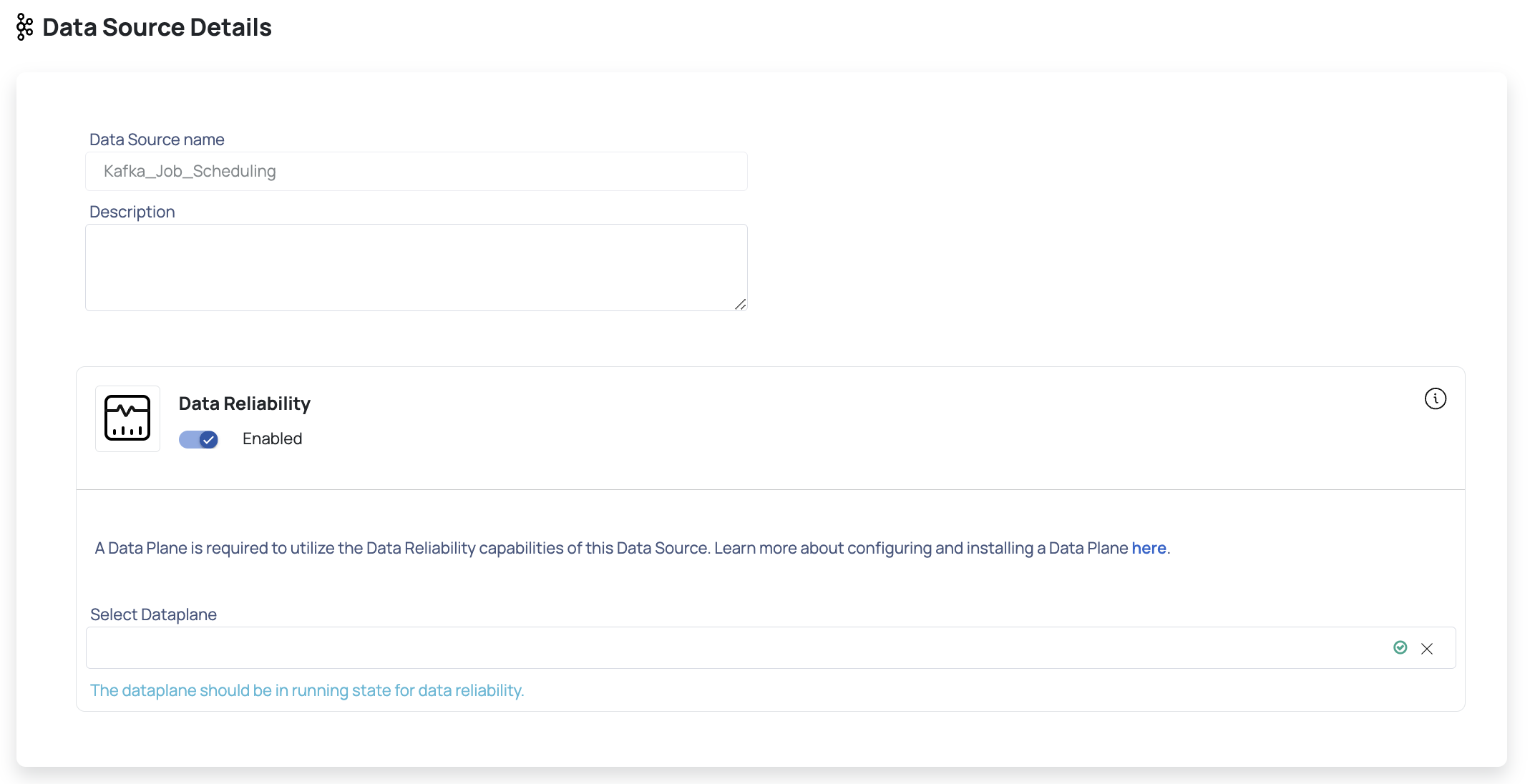
- Click Next. The Enter Connection Details page is displayed.
- Enter the Kafka connection details such as Bootstrap Servers, Security Protocol, SASL Mechanism, SASL Username, SASL Password.
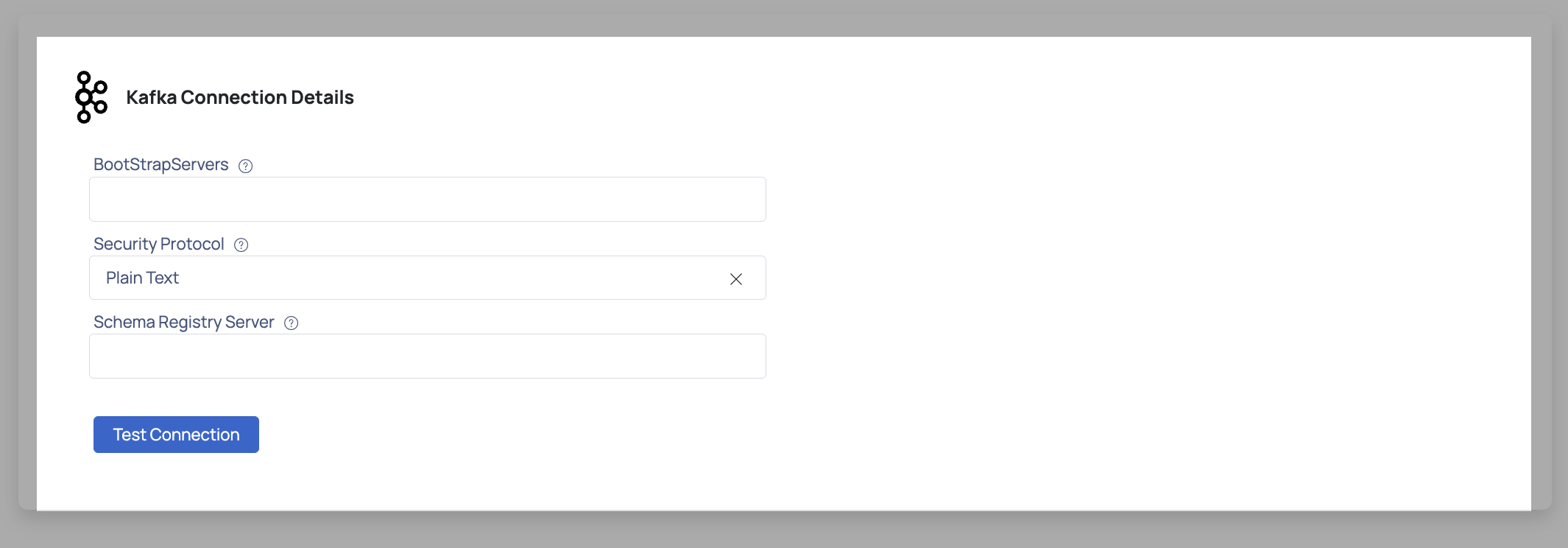
- Click Test Connection. If your credentials are valid, you receive a Connected message. If you get an error message, validate the Kafka credentials you entered.
- Click Next to proceed to the Observability Setup.
- Configure the settings:
Asset Name, Topic Name, Topic Format (JSON, AVRO, Confluent AVRO), Schema Registry Server.
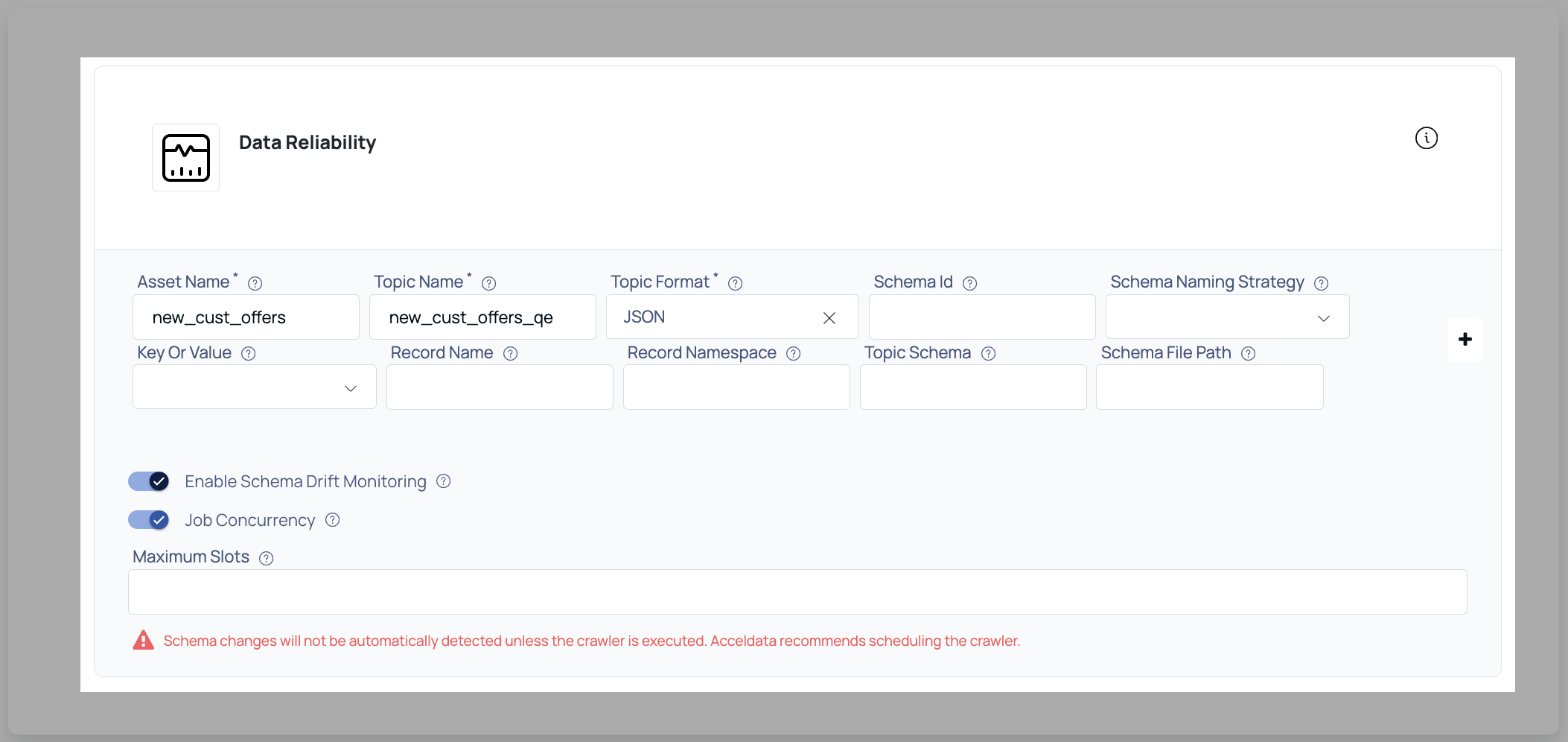
- Click Submit to complete the configuration. You will receive a confirmation message.
This guide provides a comprehensive step-by-step process to integrate Kafka as a data source in ADOC, ensuring that all necessary configurations and validations are performed for optimal data observability and reliability.
Control Plane Concurrent Connections and Queueing Mechanism
The ADOC Control Plane (CP) now supports a queueing mechanism for managing concurrent connections at the data source level. This feature is aimed at controlling and optimizing the execution of jobs, thereby preventing overload on customer databases and improving system performance and reliability. This guide provides an overview of how concurrent job execution is managed and queued, as well as details on the configuration process for manual and scheduled executions.
Key Features
- Concurrency Control at Datasource Level: Define the maximum number of concurrent jobs allowed for a specific data source.
- Queueing Mechanism for Jobs: Introduce a queueing mechanism to manage jobs that exceed the configured concurrency limit, ensuring smooth execution without overloading the database.
- Support for Multiple Job Types: Currently supports data quality, reconciliation, and profiling jobs.
- Flexibility in Slot Allocation: Users can set the number of available slots as per their performance needs.
Concurrency Control and Queueing Mechanism
Why Concurrency Control is Needed?
Previously, no concurrency control existed to manage numerous jobs on the Control Plane. This meant that users may submit a huge number of jobs at once, potentially overflowing their database and causing performance issues or even system breakdowns. The new concurrency management technique ensures that only a fixed number of jobs can run concurrently, with additional jobs queued.
The concurrency control and queueing mechanism has been implemented for SAP Hana data sources. The new feature allows users to set the maximum number of concurrent jobs for a particular data source. If the number of jobs triggered exceeds the defined limit, the remaining jobs are queued until a slot becomes available.
How the Mechanism Works
- Job Slots: Users can define the number of slots available for concurrent job execution for a given data source. For example, if a data source is configured with a maximum of 5 concurrent jobs, only five jobs will run simultaneously.
- Queueing Mechanism: If more than five jobs are triggered, the excess jobs are moved to a queue and marked as "waiting." As soon as a running job completes, a slot is freed, and a job from the queue is picked for execution.
- Slot Monitoring: A background service continuously monitors the availability of job slots, checking every minute to see if a queued job can be started.
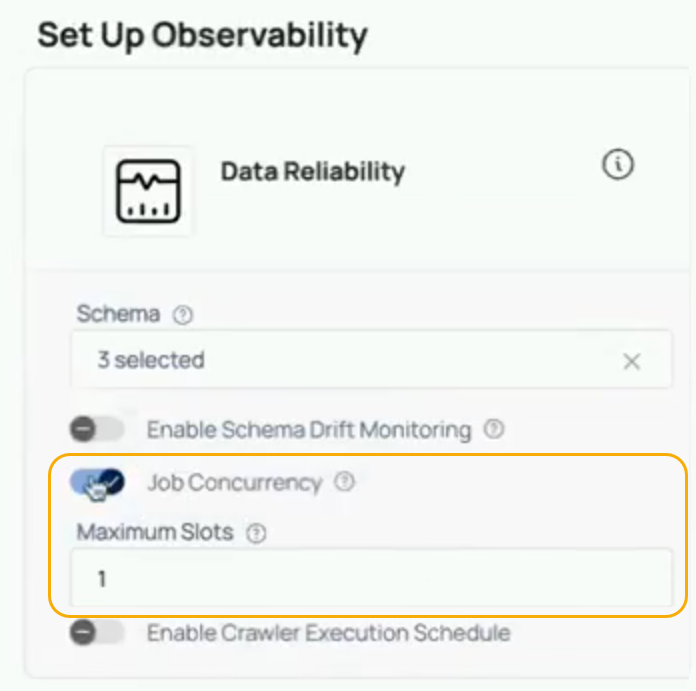
Configuration
Setting Concurrent Job Limits
When configuring a new data source or editing an existing one, users have the option to enable job concurrency control. By default, this setting is disabled, but it can be enabled, and users can set the Maximum Slots to define how many jobs can run concurrently.
Steps to Configure Job Concurrency:
- Navigate to the data source configuration page.
- Enable Job Concurrency Control by toggling the setting.
- Enter the number of slots (e.g., 1, 5, 10) that should be available for concurrent job execution.
- Save the configuration.
- Slot Setting: Suppose a user sets the Maximum Slots to 1 for a particular data source.
- Job Submission: The user then triggers three profiling jobs simultaneously.
- Queueing: Only one job will start immediately. The remaining two jobs are queued, and their status is shown as waiting.
- Slot Release: Once the first job completes, a slot is released, and the next job in the queue is started.
Benefits
- Prevents Overload: By limiting the number of concurrent jobs, the feature helps prevent overloading of customer databases, thus maintaining performance and avoiding potential crashes.
- Flexible Configuration: Users can adjust the number of concurrent slots based on their performance needs, giving them control over the workload being processed.
- Scalable: While this feature is currently implemented for SAP Hana data sources, it can be extended to other data sources such as Snowflake with minimal changes.
The queueing method for concurrent connections at the data source level is critical for maintaining system stability and optimal performance when dealing with multiple task executions. By restricting the amount of concurrent jobs and implementing a queueing system, the Control Plane may effectively manage workloads without overflowing the database.
ADOC now supports cadence and freshness policies for Kafka topics from v 3.15.0 onwards. This enables hourly collection of key metrics for Kafka topics, similar to other data sources.
Cadence Metrics and Freshness Policies for Kafka
Key Metrics Collected
For each Kafka topic asset configured on the Datasource Integration page (where the topic names are specified), the following metrics are collected:
- Number of messages: Total count of messages available in the topic, providing insight into the volume of data.
- Last message update time: The timestamp of the most recent message in the topic, based on the latest offset record timestamp across all partitions.
- Number of messages received per hour: Tracks the hourly message inflow to the topic.
- Size of messages: Total size of all messages in the topic.
These metrics can be used to create freshness policies tailored for Kafka, ensuring data reliability and monitoring. For more information on how to enable data freshness for a data source, see Data Freshness Policy.
Important Considerations
Retention Policies: Cadence metrics are affected by Kafka's retention settings. Deleted or compacted messages are not included in these metrics.
Timestamp Types: Kafka record timestamps can represent:
- Event Time (
CreateTime): Set by the producer, reflects when the event occurred. - Log Append Time (
LogAppendTime): Set by the Kafka broker, reflects when the event was stored.
- Event Time (
Scope of Monitoring: Current support is limited to monitoring incoming data in Kafka topics. Monitoring of producers and consumers is not included.