The following errors you might encounter during the migration.
HDFS Filepath exception
[2025-04-09T12:06:32.672+0530] {oozie_converter.py:125} INFO - Converting nodes to tasks and inner relationsTraceback (most recent call last): File "/root/finale/o2a/./bin/o2a", line 38, in <module> o2a.o2a.main() File "/root/finale/o2a/o2a/o2a.py", line 137, in main converter.convert() File "/root/finale/o2a/o2a/converter/oozie_converter.py", line 106, in convert self.convert_nodes() File "/root/finale/o2a/o2a/converter/oozie_converter.py", line 127, in convert_nodes tasks, relations = oozie_node.mapper.to_tasks_and_relations() ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/root/finale/o2a/o2a/mappers/shell_mapper.py", line 119, in to_tasks_and_relations prepare_task = self.prepare_extension.get_prepare_task() ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/root/finale/o2a/o2a/mappers/extensions/prepare_mapper_extension.py", line 40, in get_prepare_task delete_paths, mkdir_paths = self.parse_prepare_node() ^^^^^^^^^^^^^^^^^^^^^^^^^ File "/root/finale/o2a/o2a/mappers/extensions/prepare_mapper_extension.py", line 67, in parse_prepare_node node_path = normalize_path(node.attrib["path"], props=self.mapper.props) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/root/finale/o2a/o2a/utils/el_utils.py", line 147, in normalize_path raise ParseException(o2a.converter.exceptions.ParseException: Unknown path format. The URL should be provided in the following format: hdfs://localhost:9200/path. Current value: {{ params.get('USCCETLIngestDir') }}/{{ params.get('USCCETLIngestDoneIndFile') }} None 0 {{ params.get('USCCETLIngestDir') }}/{{ params.get('USCCETLIngestDoneIndFile') }}Add variables that resolve to HDFS locations, such as ${tmpLocation}, into the resolve_name_node method located in o2a/utils/el_utils.py.
xxxxxxxxxx106 def _resolve_name_node(translation: str, props: PropertySet) -> Tuple[Optional[str], int]:107 """108 Check if props include nameNode, nameNode1 or nameNode2 value.109 """110 merged = props.merged111 for key in ["nameNode", "nameNode1", "nameNode2", "dataNode", "tmpLocation""]:112 #Add the variables that resolve to an hdfs location "${tmpLocation}"113 start_str = "{{" + ' params.get(\\'' + key + '\\') ' + "}}"114 start_str_data_node = "${" + ' params.get(\\'' + "dataNode" + '\\') ' + "}"115 name_node = merged.get(key)116 if translation.startswith(start_str) and name_node:117 return name_node, len(start_str)118 if translation.startswith(start_str_data_node) and name_node:119 return name_node, len(start_str_data_node)120 return None, 0HDFS File Paths in Hiveconfs
Using HDFS File Paths in HiveOperator hiveconfs
When using the HiveOperator in Apache Airflow, it's important to correctly format the HDFS file paths passed as Hive configuration variables (hiveconfs). The incorrect path references can lead to runtime errors during Hive query execution.
Problem:
Users often pass HDFS paths dynamically via variables like JOB_PROPS['user.name'] or JOB_PROPS['examplesRoot'], which may not resolve correctly at runtime, especially if the paths assume a different user context.
For example:
xxxxxxxxxxhiveconfs={ "INPUT": f"/user/{JOB_PROPS['user.name']}/examples/input-data/table", "OUTPUT": f"/user/{JOB_PROPS['user.name']}/{JOB_PROPS['examplesRoot']}/output-data/hive2",}If JOB_PROPS['user.name'] resolves to something other than airflow, the query might fail with errors as below.
xxxxxxxxxxInput path does not exist: hdfs://.../user/airflow/user/oozie/examples/input-data/tableRecommended Fix:
Explicitly construct your HDFS paths to align with the runtime context of the Airflow user, as Airflow's Hive tasks often execute under that user's permissions.
Use paths as below:
xxxxxxxxxxhiveconfs={ "INPUT": "/user/airflow/examples/input-data/table", "OUTPUT": "/user/airflow/examples/output-data/hive2",}Ensure that the input and output directories exist in HDFS under the correct user path (/user/airflow/...).
Hive DAG: Cannot modify ***.ctx.try_number at runtime
The below image shows the Hive DAG logs.
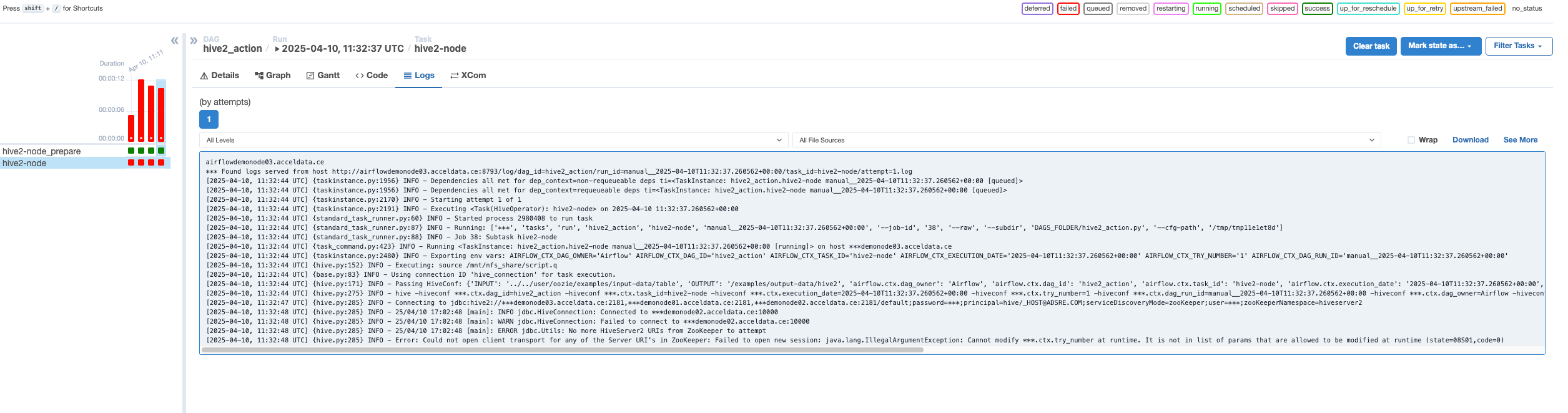
By default, the HiveOperator includes all context variables in the hiveconf. To enable Airflow to pass these variables, you can update the configuration shown below in your hive-site.xml.
xxxxxxxxxxhive.security.authorization.sqlstd.confwhitelist.append = airflow.ctx.*|mapred.job.name|INPUT|OUTPUTSkeleton Transformation
The O2A conversion supports several action and control nodes. The control nodes include fork, join, start, end, and kill. Among the action nodes, fs, map-reduce, and pig are supported.
Most of these are already handled, but when the program encounters a node it does not know how to parse, it performs a kind of "skeleton transformation" — converting all unknown nodes into dummy nodes. This allows users to manually parse those nodes later if they wish, as the control flow remains intact.
Decision Node
The decision node is not fully functional as there is not currently support for all EL functions. So in order for it to run in Airflow you may need to edit the Python output file and change the decision node expression.
The reference is here in the: Implement decision node.