Overview
This document provides a step-by-step guide for batch importing data into Apache Pinot using HDFS as the storage backend.
Before running any Pinot commands, make sure to set Java 11 on the CLI and export other required configurations.
Create different tables and schemas.
Prepare the Data
Create a directory to store raw data.
Create a sample CSV file with transcript data:
Define Schema and Table Configuration
Schema Definition
Table Definition
Upload Schema and Table Configuration
Register the schema:
Register the table:
Configure Batch Ingestion Job
Configuration in case of Kerberos Enabled Cluster
In case you are using Kerberos, add the below properties.
Note In Advanced pinot-controller-conf, add the below properties, save, and restart the Pinot Service from Ambari.
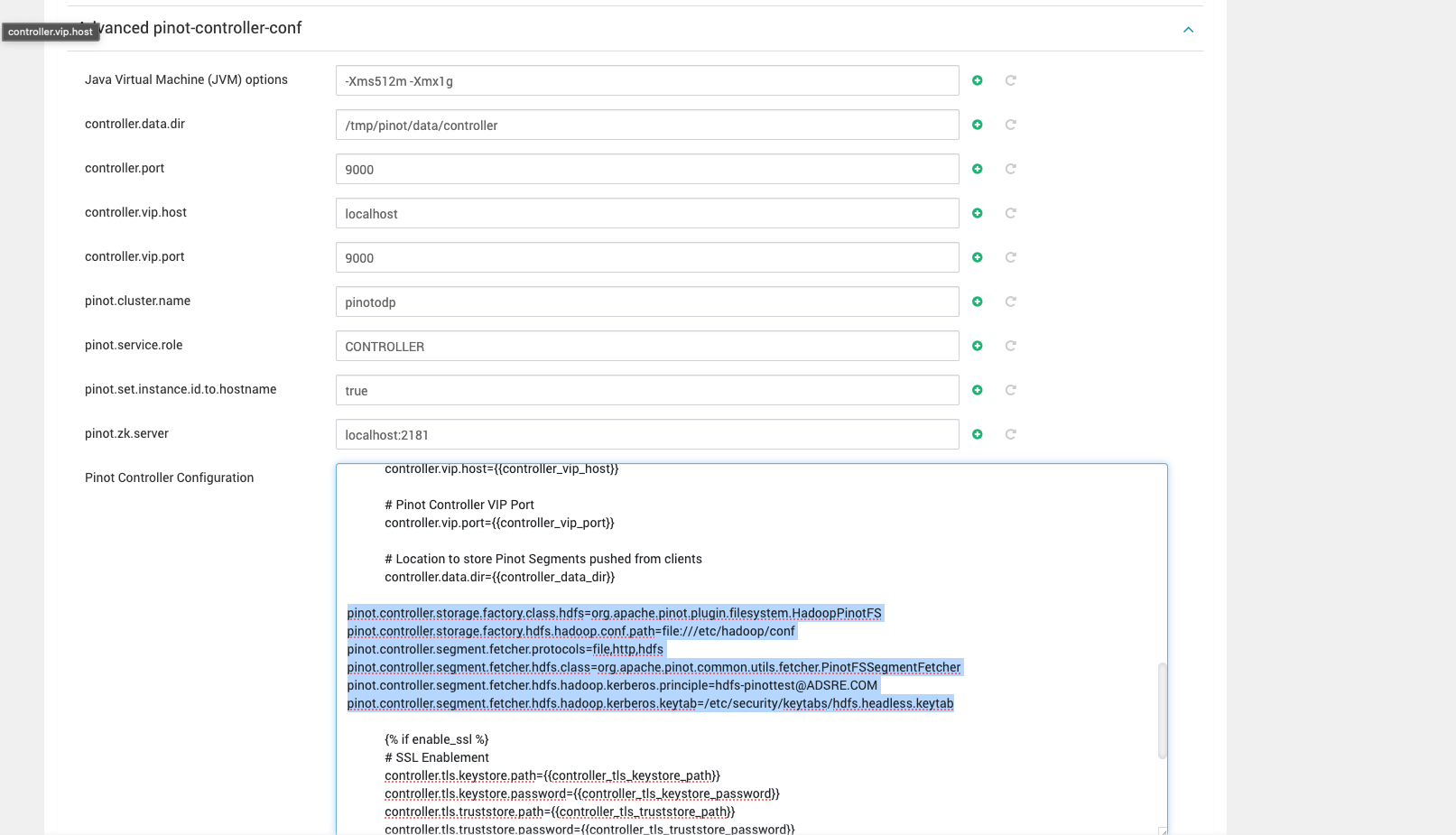
Make sure to update the values based on your requirements.
Remove the following properties in case you are not using Kerberos from the below yaml file and above mentioned Kerberos configurations from the Pinot Controller conf.
Create a batch ingestion job configuration file:
Set Up Hadoop Environment Variables
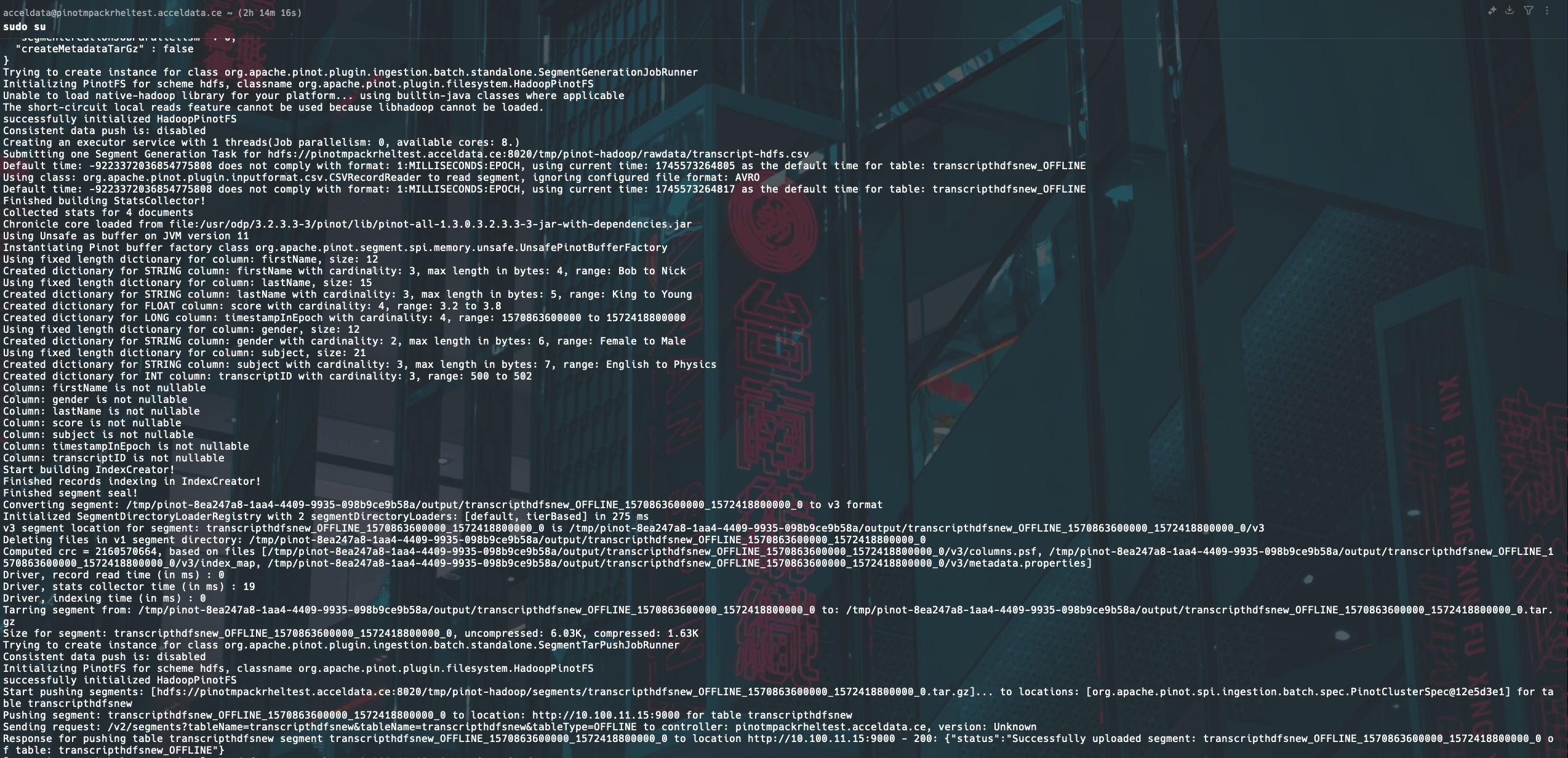
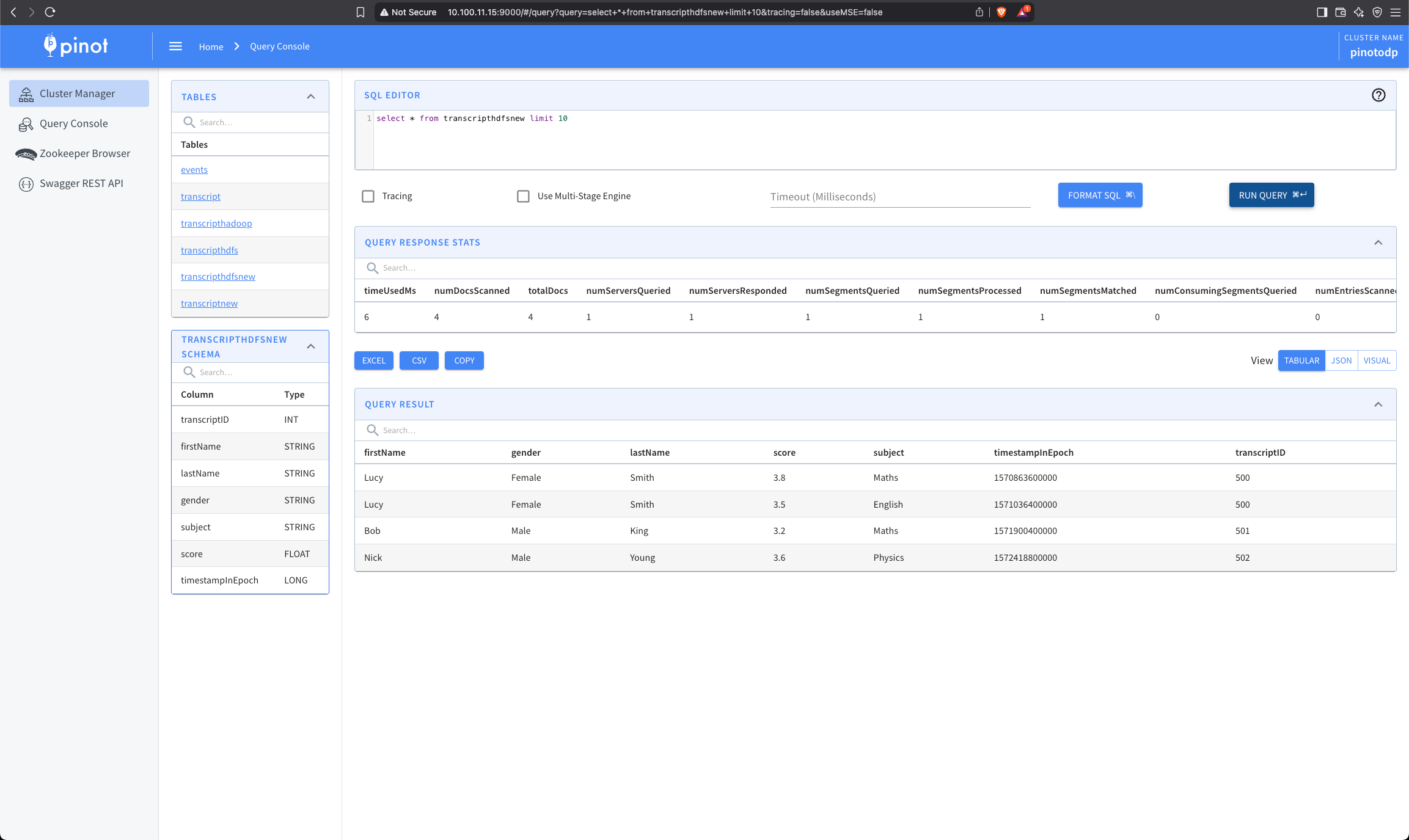
Run the Batch Ingestion Job
Execute the following command to launch the data ingestion job: