Scaling Glue Catalog Through Acceldata xStore
AWS Glue Data Catalog is widely adopted as the metadata system of record for data lakes on S3. It is well integrated with native AWS services, provides a stable schema, and has reasonable defaults. At scale, however, Glue exposes limits that constrain large data platforms — API throttling, no caching, no cross-source federation, no built-in lineage, no engine-agnostic protocol surface, and no first-class governance integration. Acceldata xStore is designed to sit on top of Glue (and other catalog backends) and provide the missing capabilities through a federated semantic catalog.
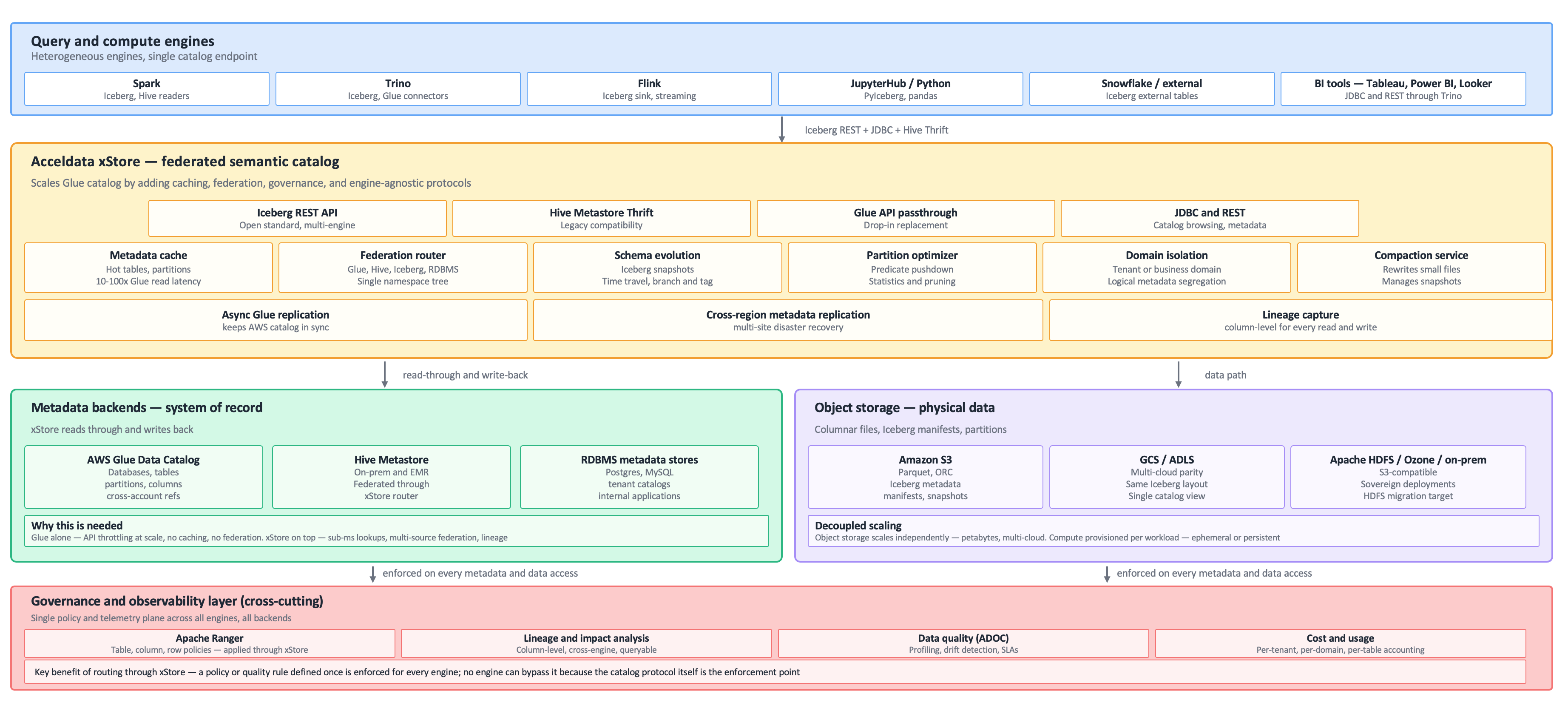
Figure : xStore as a federated semantic catalog over Glue, Hive, and object storage — engine-agnostic, governed, and horizontally scalable.
Why Glue alone is not enough at scale
Customers running petabyte-scale lakes on Glue routinely hit four classes of limit:
API throttling — Glue has per-account API quotas. A query plan that lists thousands of partitions can exhaust the quota and stall every other consumer in the account. Caching is not built-in; every engine call hits the API.
Single-source — Glue catalogs only AWS-resident metadata. Tables in on-prem Hive Metastores, RDBMS-backed catalogs, or other clouds need separate connectors and federation logic in every engine.
No engine-agnostic protocol — engines integrate with Glue through engine-specific connectors. Snowflake's Glue integration is different from Trino's, which is different from Spark's. There is no neutral catalog protocol that all engines speak.
Governance gaps — Lake Formation provides table-level access control but does not handle row and column policies uniformly across engines, does not capture lineage automatically, and does not integrate with non-AWS engines.
How xStore addresses these limits
xStore sits between query engines and metadata backends. It exposes multiple protocol surfaces upward (so any engine can connect using its native catalog protocol) and routes through a set of core capabilities to one or more metadata backends downward — Glue being one of them. The mapping from Glue's pain points to the xStore capability that resolves each one:
Glue limit | xStore capability that addresses it |
|---|---|
API throttling | Metadata cache — hot tables, partitions, and statistics are cached in memory; read latency drops 10 to 100 times and Glue API quota consumption drops correspondingly. The Glue API passthrough surface routes existing Glue clients through this cache transparently. |
Single-source | Federation router — a single namespace tree spans Glue, Hive Metastores, RDBMS-backed catalogs, Snowflake, Unity Catalog, and Kafka. A single query can reference tables in any of them, and xStore routes each reference to the correct backend. |
No engine-agnostic protocol | Iceberg REST API + Hive Metastore Thrift + Glue passthrough + JDBC/REST — every engine connects through whatever protocol it already speaks. New integrations use Iceberg REST as the open standard; legacy Spark and Hive workloads keep using Thrift unchanged. |
Governance gaps | xCentral Governance Link (Apache Ranger) — table, column, and row-level policies, RBAC and ABAC, plus tag-based classification. A policy authored once is enforced uniformly across Spark, Trino, Flink, and Snowflake because all of them go through xStore on every metadata request. |
For the full architecture — protocol surface, core capabilities, replication and lineage, object storage as the data layer, and governance enforced at the catalog protocol layer.
For AWS-native services that read directly from Glue (Athena, Redshift Spectrum, EMR), xStore replicates schema changes back to Glue asynchronously through its async Glue replication capability. Glue stays current; engines that go through xStore get richer features; nothing breaks.
Migration path from Glue-only to xStore
XDP supports a non-disruptive migration from a Glue-only deployment to xStore-on-Glue:
Step | Phase | Description |
|---|---|---|
1 | Deploy xStore | Stand up xStore inside the customer trust boundary. Configure it to point at the existing Glue catalog as a backend. No data movement; xStore reads through to Glue. |
2 | Validate equivalence | Compare query results between direct Glue and xStore-routed queries. Validate that every existing engine still works with no changes. |
3 | Switch read traffic | Repoint Trino, Spark, Flink, and other engines to xStore endpoints. Glue continues to be the system of record. Cache benefits start immediately. |
4 | Switch write traffic | New tables and writes go through xStore. xStore writes back to Glue asynchronously, preserving compatibility with native AWS services. |
5 | Federate additional sources | Add Hive Metastores, RDBMS catalogs, and other Glue catalogs to xStore. Engines see a unified namespace without changes. |
6 | Enable governance | Activate Ranger policies, lineage capture, and data quality at the xStore layer. Existing Lake Formation policies coexist. |
7 | Optional retirement | If desired, retire Lake Formation in favor of Ranger for uniform multi-engine governance. Glue itself remains as the AWS-native catalog backend. |
Summary and recommendations
The three architectural concerns covered in this document — multi-cluster federation, EMR-style lifecycle management, and federated catalog scaling — are not independent. They compose into a coherent platform model:
Multi-cluster federation gives operators a single pane of glass over many isolation zones, supporting both physical separation (Model A) and logical separation (Model B) under the same control plane.
EMR-style lifecycle management lets each cluster be sized and timed for its workload, with transient clusters for batch and persistent clusters for serving — all sharing the same catalog and storage.
xStore over Glue makes the catalog itself the federation point — engine-agnostic, governed, scalable, and the place where policy is enforced uniformly.
Recommended deployment patterns
For a typical enterprise data platform spanning multiple regions and many internal teams, the recommended pattern is:
One global control plane, deployed in the customer's primary cloud region with HA replicas.
One dataplane per major region or compliance zone (e.g., US, EU, on-prem prod, on-prem non-prod).
Multiple tenants per dataplane, isolated by namespace, Yunikorn queue, and catalog domain.
Mix of transient and persistent clusters per tenant, sized to the workload.
xStore deployed alongside the control plane, federating regional Glue and Hive catalogs.
Object storage as the canonical data layer (S3, GCS, ADLS, or Ozone), with Iceberg as the table format.
What this architecture optimizes for
The XDP design consistently optimizes for three properties that matter at enterprise scale: data sovereignty (customer data and credentials never leave the trust boundary), substrate portability (the same platform runs identically on AWS, Azure, GCP, OpenShift, and bare metal), and open-source leverage with operational guardrails (best-of-breed open engines and table formats, wrapped in a managed control plane that handles auth, observability, scheduling, and lifecycle). The architectural decisions described in this document — federated control plane, decoupled compute, catalog-layer governance — are the mechanisms by which those properties are delivered.