MLflow is an open-source platform that helps you manage the complete machine learning lifecycle from tracking experiments to packaging code, deploying models, and managing versions in production. It offers four core components designed to streamline collaboration, reproducibility, and operationalization across teams.
Core Components of MLflow
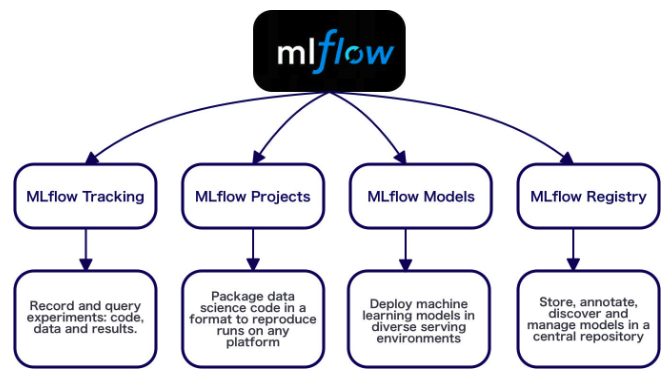
MLflow provides four key components to manage the end-to-end machine learning lifecycle:
- MLflow Tracking: Tracks log and query parameters, metrics, and artifacts from ML experiments to analyze and compare runs in a consistent and centralized way.
- MLflow Projects: Packages ML code with dependencies to ensure reproducibility and portability across environments and teams.
- MLflow Models: Saves and serves models in standard formats to support deployment across various platforms and tools.
- MLflow Model Registry: Manages model versions, stages (e.g., Staging, Production), and annotations in a central model store for better lifecycle control and governance.
MLflow Tracking
MLflow Tracking helps you log and manage everything you do while building machine learning models. It acts like a digital lab notebook for your experiments.
xxxxxxxxxximport mlflow with mlflow.start_run(): mlflow.log_param("learning_rate", 0.01) mlflow.log_metric("accuracy", 0.94)This code logs the learning rate and accuracy. MLflow stores them under a unique run ID and displays the results in the user interface.
MLflow Projects
MLflow Projects help you package your machine learning (ML) code so it can be run anywhere, by anyone, with minimal setup and zero confusion. Each project includes configuration files that define dependencies, entry points, and parameters, ensuring consistency and reproducibility.
How It Works
To define a project, create an MLproject file like the example below:
xxxxxxxxxxname: my_projectconda_env: conda.yamlentry_points: main: parameters: alpha: {type: float, default: 0.5} command: "python train.py --alpha {alpha}"This file tells MLflow:
- Environment to use –
conda.yamlspecifies the required dependencies. - Script to run –
train.pyis the main training script. - Parameters to pass –
alphais a configurable input.
How to Run a Project
Run the project locally:
xxxxxxxxxxmlflow run .Or run it directly from a Git repository:
xxxxxxxxxxmlflow run https://github.com/username/my-ml-projectMLflow automatically sets up the environment and executes the code with no manual configuration needed.
MLflow Models
MLflow Models helps you save, share, and reuse machine learning models regardless of which library you used to build them.
Save a model with a single line
xxxxxxxxxximport mlflow.sklearnmlflow.sklearn.log_model(model, "model")This command:
- Saves the trained model
- Stores model metadata
- Makes it easy to reload the model later using MLflow
Load the model for predictions
xxxxxxxxxxloaded_model = mlflow.sklearn.load_model("runs:/<run_id>/model")You can use loaded_model directly for predictions. You do not need to remember the training code or environment setup.
MLflow Model Registry
MLflow Model Registry is a centralized store to track, version, and manage your machine learning models throughout their lifecycle.
What you can do
Register models after training
Track model versions automatically (v1, v2, v3…)
Assign stages to models:
- Staging – for testing and validation
- Production – actively used in deployment
- Archived – deprecated or unused models
Add notes and comments for collaboration, reviews, or audit trails
Model Registry helps streamline deployment, approvals, and rollback — all in one place.