Overview
Trino is a high-performance, distributed SQL query engine designed for running fast, interactive analytics on large datasets. Originally developed at Facebook as PrestoSQL, it enables querying data across various sources like Hadoop, S3, relational databases, and NoSQL systems through a single interface. Trino separates compute and storage, offering scalability and flexibility for modern data architectures. It supports ANSI SQL, complex joins, and advanced query optimization.
Prerequisites and Supported Environment
Additional JDK 23 required on nodes
Supported on ODP-3.2.3.3-2, ODP-3.2.3.3-3, and 3.3.6.x release onwards.
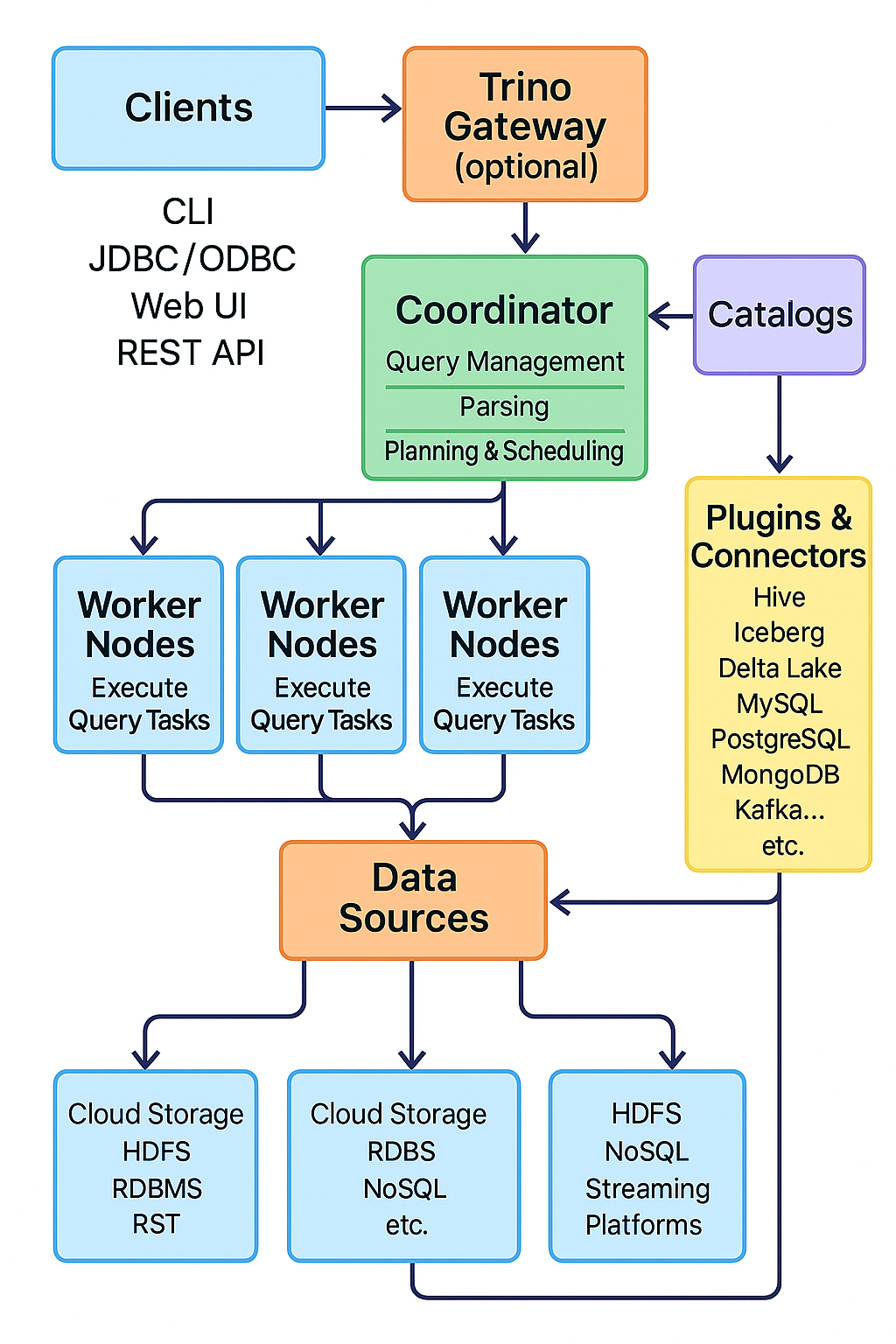
Architecture Overview
Components
The basic Trino architecture components are as follows.
Clients (For example, CLI, JDBC, ODBC, and Web UI)
Coordinator (Manages queries, parsing, planning, and scheduling)
Workers (Execute query tasks, do actual data processing)
Connectors (Interfaces to various data sources such as Hive, Iceberg, Delta Lake, MySQL, etc.)
Understanding Architecture
Trino operates in a distributed architecture with distinct server types that collaborate to process queries in parallel across multiple nodes. Before diving into capacity planning, it's essential to understand how these components work together:
Coordinator: The "brain" of your Trino installation, responsible for parsing statements, planning queries, and managing worker nodes.
Workers: Servers that perform actual data processing in parallel.
Cluster: The complete Trino installation consisting of one coordinator and multiple workers.
Each query is a stateful operation orchestrated by the coordinator and executed in parallel across workers. Processing is further parallelized using threads within each node's JVM instance.
Data Flow
Client sends SQL query to Coordinator.
Coordinator parses, plans, schedules tasks to Workers.
Workers read from data sources through Connectors and process the query.
Workers return results back to Coordinator.
Coordinator returns final result to Client.
Key Components
Component | Purpose | Implications |
|---|---|---|
Coordinator | Parses queries, manages workers and tasks, aggregates results. | Single point of failure without HA setup. |
Worker Nodes | Execute query tasks and fetch data from sources. | Scaling workers improves parallelism and performance. |
Catalogs | Define data source connection configurations. | Allow fine-grained control over access to services/databases. |
Plugins and Connectors | Connect to sources like Hive, PostgreSQL, Kafka, Iceberg, etc. | 37+ official connectors, enables federated queries. |
Trino Gateway (optional) | Load-balancing and cluster management for HA. | Needed to achieve high availability and smooth upgrades. |
Trino setup on ODP
The setup pre-requisite and resource requirements are as follows.
JDK Compatibility: Trino 472 requires additional Java 23 installation whereas usual other stack’s components & Ambari runs on Java 8 (3.2.x) or Java 11 (3.3.6.x). Configurable on the same node to have 2 JDK versions.
RAM Requirements: Tune and configure available memory requirement; insufficient memory causes failure to launch service.
Coordinator/Worker Nodes: Coordinator and Worker are not allowed to install on the same node for better memory assessment and configuration management.
Repo Refresh to include updated Pinot and dependent packages (with ODP-3.3.6.1-1, all these changes are included as part of stack).
Cluster pointing to local repo: Download the latest 3.2.3.3-2.tar.gz and update the local repository accordingly. Manually perform the
odp-select reinstallon all the Trino nodes before the next step.Cluster Pointing to Acceldata Mirror Repo: If the cluster is pointed to the Acceldata Mirror Repository, manually perform the
odp-select reinstallon all nodes where Pinot components are intended to be installed.
Deploy and start the service. Trino must be up and running without LDAP/Kerberos/SSL with HTTP at port 9095.