You can create an action plan to automate tasks using one or more action runbooks.
Steps:
In the Pulse UI, go to Actions on the left navigation bar and select Actions. The list of existing action plans appears.
On the Actions page, click Create Action. The available action runbooks are displayed.
On the Action Runbooks page, drag a runbook into the Action Workflow box.
Note: You can create an action plan using one or more action runbooks.
Configure the runbook settings and click Submit.
For details on configuring runbooks, see below.
- An action plan is created and listed on the Actions page with an overview and available options.
- For details, see Actions Overview and Action Plan Options.
Set Configuration for Action Runbooks
To create an action plan, drag and drop an action runbook into the Action Workflow box, then configure the details for each runbook as described below.
Perform HDFS Non-Admin Operations
The HDFS NON-ADMIN OPERATIONS action lets you perform the most common HDFS operations:
- Copying files or directories from a local source to a destination in HDFS or vice versa
- Moving files or directories from a local source to a destination in HDFS or vice versa
- Copying files or directories within HDFS, i.e, where the source and destination are both on HDFS
- Moving files or directories within HDFS, i.e,. where the source and destination are both on HDFS.
This configuration allows non-admin users to perform specific HDFS operations (like copying or moving files) while using Kerberos for secure authentication.
Configure the action runbook details as below:
- Is Cluster Kerberized?: Enable this option if the cluster is Kerberized.
- krb5.conf File Path: Enter the
Krb5.conffile path. - Name Node Address: Enter the NameNode address. Refer to the value of
dfs.namenode.rpc-address/dfs_namenode_servicerpc_addressto ensure the address to be entered. - Destination File/Directory: Enter the path to the destination file or directory in HDFS where you want to copy or move the file.
- HDFS Operation Type: Enter the HDFS operation type from the drop-down list.
- Source File/Directory: Enter the path to the source file or directory, either from the local system or HDFS, depending on the operation type.
- Kerberos Principal: Enter the Kerberos principal for authentication.
- Kerberos Realm: Enter the Kerberos realm, which defines the administrative domain for Kerberos.
- Service Principal Name: The name of the service principal for the HDFS NameNode. This is required if the cluster is Kerberized. For example,
hdfs/node_hostnameon CDP andhdfs/node_hostnameon HDP.
HDFS Top 10 Directories
The HDFS top 10 Directories action runbook enables you to get the top 10 HDFS directories in your ecosystem.
Configure the action runbook details as below:
- Is Cluster Kerberized?: Enable this option if the cluster is Kerberized.
- Krb5.conf File Path: Enter the
Krb5.conffile path. - Name Node Address: Enter the NameNode address. Refer to the value of
dfs.namenode.rpc-address/dfs_namenode_servicerpc_addressto ensure the address is entered. - Kerberos Principal: If Kerberos is enabled, enter the Kerberos principal in the format for secure authentication. If Kerberos is disabled, the value of this field must be simply the HDFS username.
- Kerberos Realm: Enter the name of the Kerberos realm your system will authenticate against.
- Service Principal Name: Enter the service principal name.
Kerberos
The Kerberos action lets you perform the most common Kerberos operations. You can use it to do kinit, kdestroy, etc., before and after performing actions in a Kerberized environment.
Configure the action runbook details as below:
- Keytab: Enter the Keytab file path.
- krb5.conf File Path: Enter the
Krb5.conffile path. - Logout (Delete Ticket): Toggle this setting based on whether you want the Kerberos ticket to be deleted after logout. Set to ON to delete the ticket or OFF to retain it.
- Output: Toggle this based on whether you want the Kerberos authentication process to display output logs. ON for logging or OFF for no logs.
- Kerberos Principal: Enter the Kerberos Principal used for
kinit.
Log Rotation
The Log Rotation action is a plugin for Hadoop services that facilitates log rotation. This action allows you to specify custom log patterns, log directory paths, and retention policies for their Hadoop service logs.
Configure the action runbook details as below:
- Custom Log Pattern: Enter the custom log patterns for the service logs, separated by commas. If not specified, the default log pattern for the service will be used.
- Log Directory Path: The path of the log directory where the service logs are being stored. If not specified, the default log directory will be used for that service, which is
/var/log/hadoop. - Output: Click the checkbox if you want the log rotation output to be sent to the logs.
- Retention Days: Enter the number of days’ worth of logs to retain. If not specified, the default retention period of 30 days will be used.
- Service Name: Enter the name of the Hadoop service for which you want to rotate logs.
- Timeout (in seconds): Specify the timeout duration in seconds for the log rotation to complete.
Make API Request
The Make API Request action allows you to execute REST API calls with ease directly from our platform. By providing configurable parameters such as method, URL, and host tags, you can tailor your requests to fetch specific data. Optionally, you can log the API call output for further analysis.
Configure the action runbook details as below:
- Timeout (in seconds): Specify the timeout duration for the API request in seconds.
- Headers: Enter headers for the API call and specify them as a string. Each header must be separated and prefixed with -H. For example, -H "Content-Type: application/json" -H "Host: VM001".
- Skip SSL Certificate Verification: If you set it to
true, the API call ignores the SSL certificate verification. - Is Kerberized: Set this to
trueIf the API call needs Kerberos authentication. - krb5.conf File Path: Enter the path to the
krb5.conffile for Kerberos authentication. - Method: Enter the HTTP method (GET, POST, PUT, DELETE, etc.) for the API request.
- Output: Check this box to log the output of the API call to the platform's logs.
- Password For Basic Authentication: Provide the password for basic authentication if it applies to the API call.
- URL: Enter the endpoint URL of the REST API to be called in the format (http|https)://host.domain[]/path.
- Username For Basic Authentication: Enter the Username for basic authentication if it applies to the API call.
Copy Item
The Copy Item runbook in our product enables you to copy files and directories, functioning similarly to the cp command. You can specify various parameters such as the source and destination paths, whether to overwrite existing files and ownership details.
Configure the action runbook details as below:
- Destination File/Directory: Enter the path where the file or directory will be copied to. The destination can be a directory or a file.
- Force Copy: Indicate whether the copy should be overwritten if the destination file already exists.
- Group: Specify the group for the copied item.
- Owner: Specify the owner of the copied item.
- Permission: Enter the permissions for the copied item (e.g., 644).
- Source File/Directory: Enter the path from where the file or directory will be copied. The source can be a directory or a file.
Execute Command
The Execute Command action is a test plugin for Axn that allows you to run shell commands on specified hosts. You can specify the command to be executed and choose to log the output.
Configure the action runbook details as below:
- Specify Command Parameters:
- Command: Enter the shell command to be executed (default is ls -al).
- Output: Check this box if you want the output of the provided command to be written to the logs.
Run Script
The Run Script action allows you to execute a script on specified hosts and optionally return the output. You can choose the script to run and decide whether to wait for the script to finish execution.
Important: The maximum script file size supported is 8 MB.
Configure the action runbook details as below:
- Specify Script Parameters:
- Output: Check this box if you want the output of the provided script to be written to the logs.
- Script File: Choose the file or enter the script to run.
- Wait to Finish: Check this box if you want to wait for the script to finish running before proceeding.
Kill Tez Queries
Terminates non-LLAP Tez queries that have been running for an extended period.
Is Cluster Kerberized: Turn on this option if the cluster is Kerberized.
Krb5.conf File Path: Enter the path to the
krb5.conffile.LLAP Queue Name: Specify the LLAP queue name to exclude from killing long-running queries.
RM URL: Enter the YARN Resource Manager URL for your cluster.
- Example:
http[s]://<RM Hostname>:<Web Port>/
- Example:
Threshold in Minutes: Specify the threshold duration in minutes. Queries running longer than this value will be terminated.
Kill Impala Query
Terminates an Impala query that has been running for an extended period.
Coordinator Host: Enter the coordinator host for the specified Impala query ID.
Coordinator URL: Enter the Impala coordinator URL.
- Example:
http[s]://<hostname>:<port>
- Example:
Is Kerberized: Turn on this option if the cluster is Kerberized.
Krbconfig: Enter the path to the
krb5.conffile.Op Type: Select the operation type based on where the query needs to be killed:
- Kill Query on ODP
- Kill Query on CDP
Query ID: Enter the Impala query ID.
Kill Spark - K8S Job
Terminates Spark applications that have been running for an extended period.
Namespace: Specify the Spark namespace.
Spark Value: Enter the Spark job identifier used to locate the application to be terminated.
- Client Mode: Enter the Spark application POD name.
- Cluster Mode: Enter the PID of the Spark application
Spark Job Execution Mode: Select the Spark execution mode for your application.
- Client Mode: Select this option when the Spark driver runs inside the Kubernetes cluster.
- Cluster Mode: Select this option when the Spark driver may run on either the Kubernetes cluster or a virtual machine (VM), and the executors run on the target cluster.
Note: Choose the execution mode that matches your Spark environment configuration.
This action runbook is applicable only for Standalone Spark on Kubernetes.
Kill YARN Applications
Terminates YARN applications that have been running beyond the defined threshold or meet specific filter criteria.
Application ID: Enter the Application ID to terminate a specific application. Enter
anyto automatically select applications based on threshold parameters.Confirm Application Was Killed Successfully: Select this option to verify whether the application was successfully terminated. The system checks the application status five seconds after sending the kill request.
Filter Criterion: Filter applications by allocated memory, allocated vCore, or user.
Is Cluster Kerberized: Turn on this option if the cluster is Kerberized.
Queue Name: Enter the queue name to terminate applications running on a specific queue. This field applies only when the filter option is User; otherwise, leave it blank.
RM URL: Enter the YARN Resource Manager URL for your cluster.
- Example:
http[s]://<RM Hostname>:<Web Port>/
- Example:
Value: Enter the threshold value based on the selected filter criterion:
- Memory: Specify in megabytes (for example,
100→100 MB). - vCore: Specify the number of cores (for example,
10→10 vCore). - User: Enter in CSV format (for example, single user →
user1; multiple users →user1,user2,user3).
- Memory: Specify in megabytes (for example,
Kill Trino Query
Terminates a Trino query that has been running for an extended period.
Password: Enter the Trino user password for authentication.
Trino Query ID: Enter the Trino query ID.
- Example:
20250912123456_00001_abcd1
- Example:
Trino Coordinator URL: Enter the Trino Coordinator URL for your cluster.
- Example:
http[s]://<Coordinator>
- Example:
Username: Enter the Trino username associated with the query.
This action runbook is applicable only for Trino on Kubernetes.
Move Pending App Queue
This runbook allows you to change the queue of a YARN application that is pending.
Application ID: Enter the ID of the pending application that needs to be moved. Enter
anyto automatically select applications based on threshold parameters.Elapsed Time: Enter the elapsed time in seconds to filter and move pending applications. Enter
0if you provided an application ID.Is Cluster Kerberized: Turn on this option if the cluster is Kerberized.
Queue Name: Enter the preferred leaf queue name (or names, separated by commas) where the pending application should be moved. You can enter
anyto automatically select a queue with available resources.Note: The user must have permission to submit jobs to the target queues.
RM URL: Enter the YARN Resource Manager URL for your cluster.
- Example:
http[s]://<RM Hostname>:<Web Port>/
- Example:
Make Ambari API Request
Performs a start, stop, or restart action on cluster services or components through the Ambari API.
Select Start, Stop, or Restart Action: Choose the action to perform on the cluster services.
- Stop
- Start
- Restart
Select Single Service, All Services, or a Host Component: Specify the target scope for the action—single service, all services, or a host component. Provide additional parameters as required.
Timeout (in Seconds): Specify the timeout duration in seconds for the Ambari API call.
Cluster Name for Ambari Action: Enter the cluster name for the Ambari API call.
Hostname of the Component: Enter the hostname of the component on which the action will be performed.
Skip SSL Certificate Verification: Select this option to skip SSL certificate verification.
Is Kerberized: Turn on this option if the Ambari UI is Kerberized.
Output: Select this option to write the output of the Ambari REST API call to the logs.
Password for Basic Authentication: Enter the password for basic authentication, if applicable to the Ambari API call.
Service Name / Component Name for Executing Action: Enter the service or component name on which to perform the action. (If you are applying the action to all services, you can leave this field blank.)
Ambari URL: Enter the Ambari HTTP or HTTPS URL.
- Example:
http[s]://<host>.<domain>[:port]
- Example:
Username for Basic Authentication: Enter the username for basic authentication, if applicable to the Ambari API call.
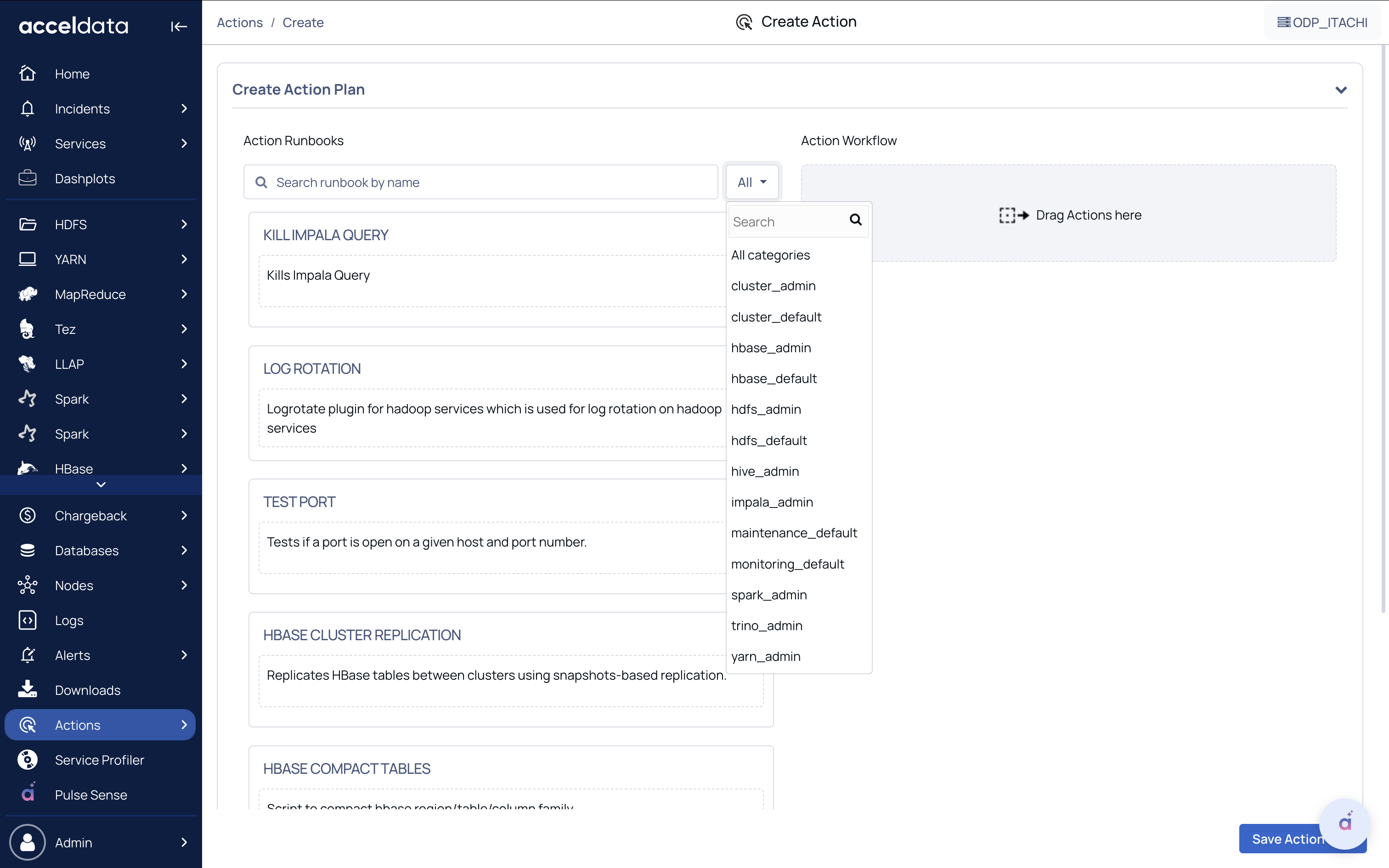
Perform HDFS Canary Operations
Performs HDFS canary tests to validate read, write, list, and delete performance in HDFS, ensuring cluster health and responsiveness.
Canary Test: Select one of the tests:
- hdfs-canary-create-read-delete-file
- hdfs-canary-list-dir
When hdfs-canary-create-read-delete-file is selected, fill in the details as below.
- Ccache_file_path: Path to Kerberos cache (usually /opt/pulse/actions/tmp/krb5cc*).
- File_size: Enter the file size in GB (minimum: 1 GB).
- HDFS User: Typically hdfs.
- Is Cluster Kerberized: Enable if Kerberos is configured.
- Krbconfig: Path to Kerberos configuration file (must exist on all nodes).
- list_dir_name: Directory to list in HDFS. Enter / for root.
- Name_node_address: NameNode address. For example, odp901.acceldata.dvl:8020.
- Service_principal_name: Required only for Kerberized clusters.
When hdfs-canary-list-dir is selected, fill in the fields as described in Step 2. The only differences are:
- File Size: Not required.
- list_dir_name: Specify any directory in HDFS (defaults to the root directory).
When configuring hosts in the next step for canary operations, specify a single host where the target service is running. This host will internally make requests and fetch the required data.
Perform HIVE Canary Operations
Performs Hive canary tests to measure query execution time, table operations, and overall Hive service stability.
- Ensure the Hive shell command-line tool is installed and configured on the host.
- Verify that the host can successfully connect to the Hive service.
- This host is typically the Hive client node specified in the Select Host field when configuring the Hive canary action in Pulse.
Canary Test: Select one of the tests:
- hive-canary-create-delete-table: Creates and deletes a table to measure query execution and error rates.
- hive-canary-select: Runs a select query to measure execution time and query latency.
When hive-canary-create-delete-table is selected, configure the following parameters to run the test:
- Is cluster kerberized: Enable this option if Kerberos authentication is enabled on the cluster.
- Principal: Enter the node where you want to run the canary test.
- Keytab: Provide the location of the Hive keytab file.
- db_name: Enter the database name. Ensure that the database already exists.
- Table_name: Specify the table name that the canary should create and then delete.
- Impala Coordinator Host: Hostname of the Impala coordinator node the canary connects to for running the test.
- Enable Impala SSL: Enable this to use TLS/SSL when connecting via impala-shell. This allows compatibility with clusters where Impala is configured with TLS/SSL.
- Impala CA Certificate Path: File path to the CA certificate used to verify the Impala server’s SSL certificate. If ssl is enabled, the user has to provide the ca cert path.
When hive-canary-select is selected, fill in the fields as described in Step 2.
When configuring hosts in the next step for canary operations, specify a single host where the target service is running. This host will internally make requests and fetch the required data.
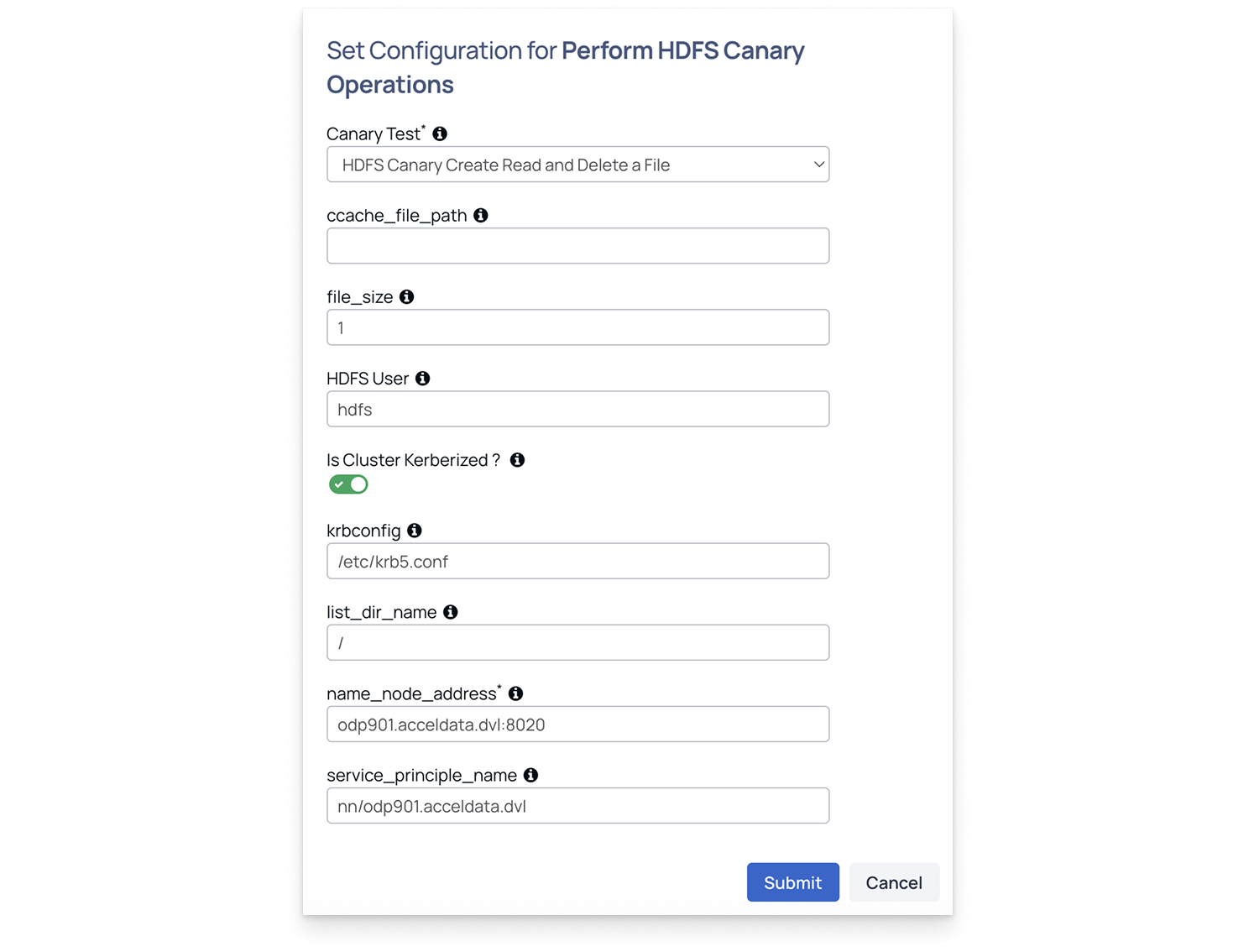
Perform Impala Canary Operations
Performs Impala canary tests to verify query performance, latency, and service responsiveness across the Impala environment.
- Ensure the Impala shell (impala-shell) command-line tool is installed and configured on the host.
- Verify that the host can successfully connect to the Impala service.
- This host is typically the Impala client node specified in the Select Host field when configuring the Impala canary action in Pulse.
Canary Test: Select one of the tests:
- impala-canary-create-delete-table: Creates and deletes a table in Impala to validate responsiveness and stability.
- impala-canary-select: Executes a select query to measure query latency and success rate.
When impala-canary-create-delete-table is selected, configure the following parameters to run the test:
- db_name: Enter the database name. Ensure that the database already exists.
- Is cluster kerberized: Enable this option if Kerberos authentication is enabled on the cluster.
- Keytab: Provide the location of the Hive keytab file.
- Principal: Enter the node where you want to run the canary test.
- Table Name: Specify the table name that the canary should create and then delete.
When impala-canary-select is selected, fill in the fields as described in Step 2.
When configuring hosts in the next step for canary operations, specify a single host where the target service is running. This host will internally make requests and fetch the required data.
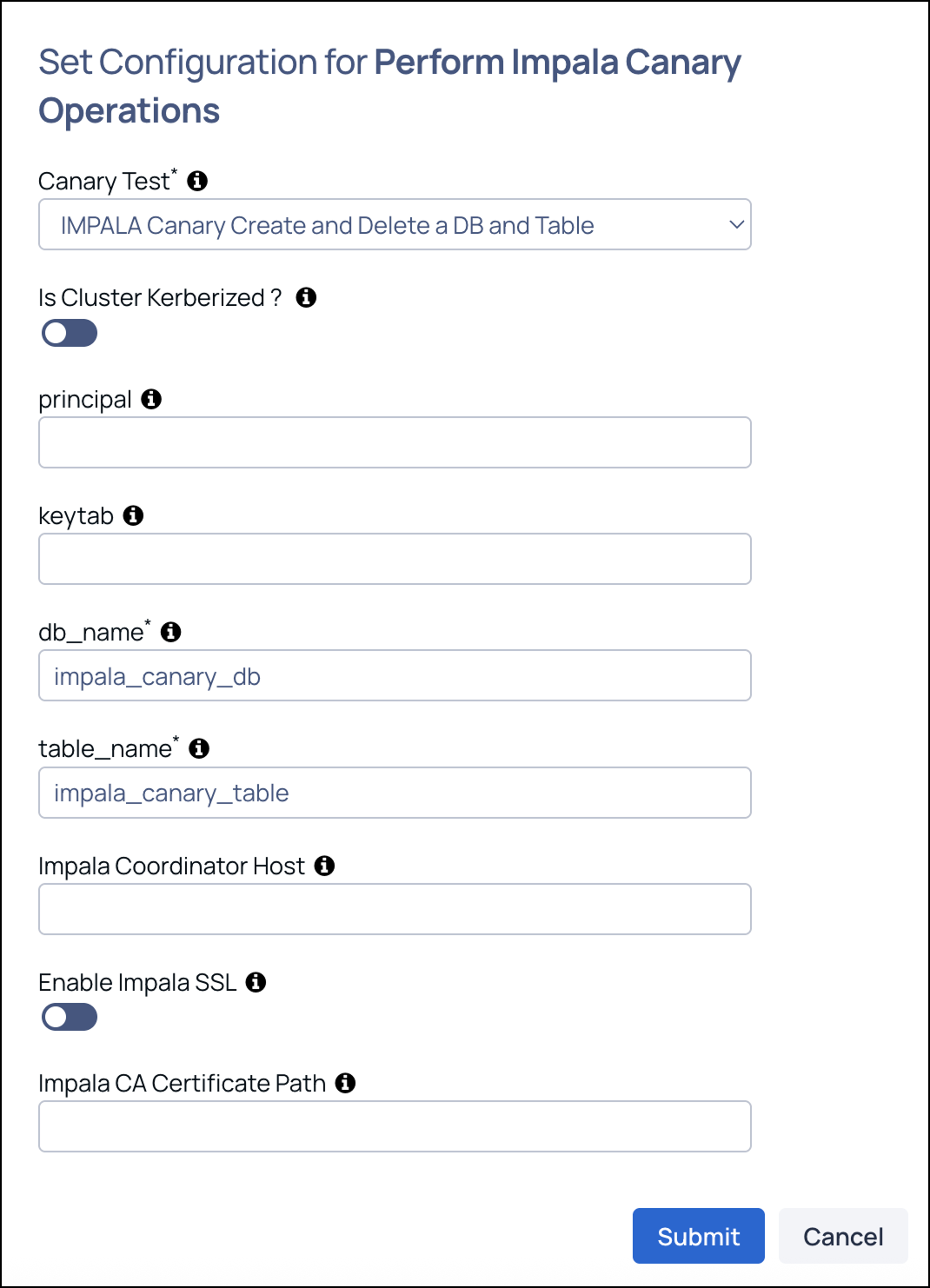
Hadoop DR Cluster Sync
This action enables incremental disaster recovery (DR) synchronization between two Hadoop clusters using HDFS snapshots and DistCp. It replicates only newly added or modified data from the source cluster to the destination DR cluster, ensuring efficient and consistent cross-cluster backup.
Enable Replication Action Plugin
You can reach out to Acceldata Support to enable the plugin.
- Select the DR_ACTIONS component in the License to enable the replication action plugin.
- Take the updated License and update it in pulse-ui.
- Restart the
ad-axnserver:
xxxxxxxxxxaccelo restart ad-axnserverPrerequisites
- System Requirements
- Hadoop 2.7.0 or later
- Bash 4.0 or later
- User Permissions
The HDFS user and DistCp user must have superuser privileges through one of the following:
- Membership in the HDFS supergroup
- The
dfs.permissions.superusergroupconfiguration
- Kerberos (Optional)
If Kerberos is enabled:
- A valid
kinitticket is required - A keytab is recommended
- Cross-realm trust must be configured, if applicable
- HDFS Configuration
- Snapshots must be enabled
- Sufficient snapshot quota must be available
- Adequate storage capacity must be available
- YARN Configuration
- Queue submission access must be granted
- Adequate memory and vCores must be available
- Queue capacity must be planned appropriately
- Out-of-Memory (OOM) Condition
This plugin spawns a DistCp JVM process. If the process is terminated by the operating system with a SIGKILL, the most likely cause is an Out-of-Memory (OOM) condition or the process exceeding the configured systemd memory limit.
Because the plugin runs under the axnserver agent, the default 1 GB MemoryMax limit may not be sufficient for large data operations. To avoid this issue, increase the axnserver memory limit so it can accommodate the heap required by the DistCp JVM process on your cluster.
Update override.yml as shown below:
xxxxxxxxxxsystemd: - case: - range: From: "0" To: "231" pulseaxn: - service: CPUShares: "1024" MemoryLimit: 2G pulsejmx: - service: CPUShares: "1024" MemoryLimit: 1G pulselogs: - service: CPUShares: "1024" MemoryLimit: 1G pulsenode: - service: CPUShares: "1024" MemoryLimit: 1G pulseprofiler: - service: CPUShares: "1024" MemoryLimit: 1G pulseyarnmetrics: - service: CPUShares: "1024" MemoryLimit: 1G - case: - range: From: "232" To: "0" pulseaxn: - service: CPUWeight: "100" MemoryMax: 2G pulsejmx: - service: CPUWeight: "100" MemoryMax: 1G pulselogs: - service: CPUWeight: "100" MemoryMax: 1G pulsenode: - service: CPUWeight: "100" MemoryMax: 1G pulseprofiler: - service: CPUShares: "100" MemoryLimit: 1G pulseyarnmetrics: - service: CPUWeight: "100" MemoryMax: 1GAfter updating the file, run the following command to apply the agent configuration changes:
xxxxxxxxxxaccelo reconfig clusterConfiguration
- Source Cluster HDFS URI: Provide the NameNode host and port in the format
hostname:port; if HA is enabled, provide the NameService name of the source cluster. - Destination Cluster HDFS URI: Provide the NameNode host and port in the format
hostname:port; if HA is enabled, provide the NameService name of the destination cluster. - Source Directories: Comma-separated list of source HDFS directories to replicate, for example
/apps/hive/warehouse,/tmp/tpcds-generate. - Snapshot Prefix: Prefix used for creating HDFS snapshots during replication, for example
dr_snap. - Snapshot Retention: Number of snapshots to retain on the clusters, for example
3. - HDFS User: User used to run
hdfs dfsandhdfs dfsadmincommands (default:hdfs); also used forhadoop distcpif DistCp User is not provided. - DistCp User: User used to run
hadoop distcp(default: same ashdfs_user); if not provided or empty, the value of HDFS User is used. - DistCp Options: Additional
distcpoptions (default:--strategy dynamic -direct -update -pugptx -skipcrccheck). - YARN Queue: YARN queue used to run DistCp jobs (default:
default). - Log File Path: Path to the replication script log file (default:
/var/log/hadoop-dr-replicate.log).
Host Selection
Ensure that only one host is selected when executing the script.
If multiple hosts are selected, the Disaster Recovery script may run on more than one host at the same time. This can result in one of the following:
- Duplicate data being ingested into the destination cluster
- Replication failure due to concurrent execution
Timeout Settings
Benchmark Results
The following results were observed using the default DistCp configuration with no competing jobs running:
| Data Size (GB) | Observed Time (In Seconds) |
|---|---|
| 10 | 500 |
| 50 | 4900 |
| 60 | 4900 |
Test environment: Benchmarking was performed on a 2-node ODP cluster, where each node had:
- 8 CPU cores
- 32 GB RAM
- 200 GB disk
Recommended Action Timeout
Set the action timeout to 1000 seconds per GB of replication data.
This recommendation provides a buffer over the observed benchmark rate of approximately 76 seconds per GB, accounting for real-world conditions such as:
- Delayed YARN resource availability
- Limited network bandwidth
- Other production workload contention
Limitation
If replication exceeds the configured action timeout, the Action Server reports a timeout failure. However, the replication script continues to run in the background on the VM.
If the action reports a timeout:
- SSH into the VM where the plugin is running.
- Check the replication log:
xxxxxxxxxx/var/log/hadoop-dr-replicate.logIf replication takes longer than 1000 seconds per GB, investigate cluster resource constraints or network issues before re-running the replication
Hive Cluster Replication
Use this action to replicate Hive tables between clusters by using the native Hive replication mechanism (REPL DUMP / REPL LOAD).
Enable Replication Action Plugin
You can reach out to Acceldata Support to enable the plugin.
- Select the DR_ACTIONS component in the License to enable the replication action plugin.
- Take the updated License and update it in pulse-ui.
- Restart the
ad-axnserver:
xxxxxxxxxxaccelo restart ad-axnserverHive Replication — Prerequisites & Configuration
- Prerequisites
Hive Version
- Requires Hive 3.0.0 or later
Network
- Source and destination clusters must have network connectivity
- Required for DistCp-based data transfer
Cross-Realm Setup (If Kerberos Enabled)
- Cross-realm trust must be configured between clusters
- Required for secure authentication during replication
- Replication Base Directory
The plugin performs:
- REPL DUMP on the source cluster (stored in HDFS)
- REPL LOAD on the destination cluster
The <REPLICATION_BASE_DIRECTORY>:
- Stores dump data
- Must exist on both source and destination clusters
- Default path:
xxxxxxxxxx/user/hive/repl/If using a custom path, configure it in:
Action Plugin → Replication Base Directory parameter
Source Cluster Setup
xxxxxxxxxxhdfs dfs -mkdir -p <REPLICATION_BASE_DIRECTORY>hdfs dfs -chown -R hive:hadoop <REPLICATION_BASE_DIRECTORY>Destination Cluster Setup
xxxxxxxxxxhdfs dfs -mkdir -p <REPLICATION_BASE_DIRECTORY>hdfs dfs -chown -R hive:hive <REPLICATION_BASE_DIRECTORY>- Proxy User Configuration
The user running the replication job must:
- Be part of the HDFS supergroup
- Have proxy permissions configured on both clusters
Example (core-site.xml)
xxxxxxxxxx<property> <name>hadoop.proxyuser.smith.hosts</name> <value>*</value></property> <property> <name>hadoop.proxyuser.smith.groups</name> <value>*</value></property>Replace smith with the actual user executing the job.
- Hive Configuration
Enable Notification Listener
xxxxxxxxxxhive.metastore.transactional.event.listeners=org.apache.hive.hcatalog.listener.DbNotificationListenerEnable DML Event Capture
xxxxxxxxxxhive.metastore.dml.events=trueNotes:
- By default, only DDL events are captured
- Enabling this ensures DML events (INSERT, UPDATE, DELETE) are also replicated
- Out-of-Memory (OOM) Condition
Description
The process may be terminated with a SIGKILL due to:
- Out-of-Memory (OOM)
- Exceeding systemd memory limits
Since the plugin spawns a DistCp JVM process, the default:
MemoryMax = 1 GB(axnserver agent)
may not be sufficient for large replication jobs.
Recommended Action
Increase the memory limit for the axnserver agent.
Update the override.yml configuration accordingly (example):
xxxxxxxxxxsystemd: - case: - range: From: "0" To: "231" pulseaxn: - service: CPUShares: "1024" MemoryLimit: 2G pulsejmx: - service: CPUShares: "1024" MemoryLimit: 1G pulselogs: - service: CPUShares: "1024" MemoryLimit: 1G pulsenode: - service: CPUShares: "1024" MemoryLimit: 1G pulseprofiler: - service: CPUShares: "1024" MemoryLimit: 1G pulseyarnmetrics: - service: CPUShares: "1024" MemoryLimit: 1G - case: - range: From: "232" To: "0" pulseaxn: - service: CPUWeight: "100" MemoryMax: 2G pulsejmx: - service: CPUWeight: "100" MemoryMax: 1G pulselogs: - service: CPUWeight: "100" MemoryMax: 1G pulsenode: - service: CPUWeight: "100" MemoryMax: 1G pulseprofiler: - service: CPUShares: "100" MemoryLimit: 1G pulseyarnmetrics: - service: CPUWeight: "100" MemoryMax: 1GConfiguration
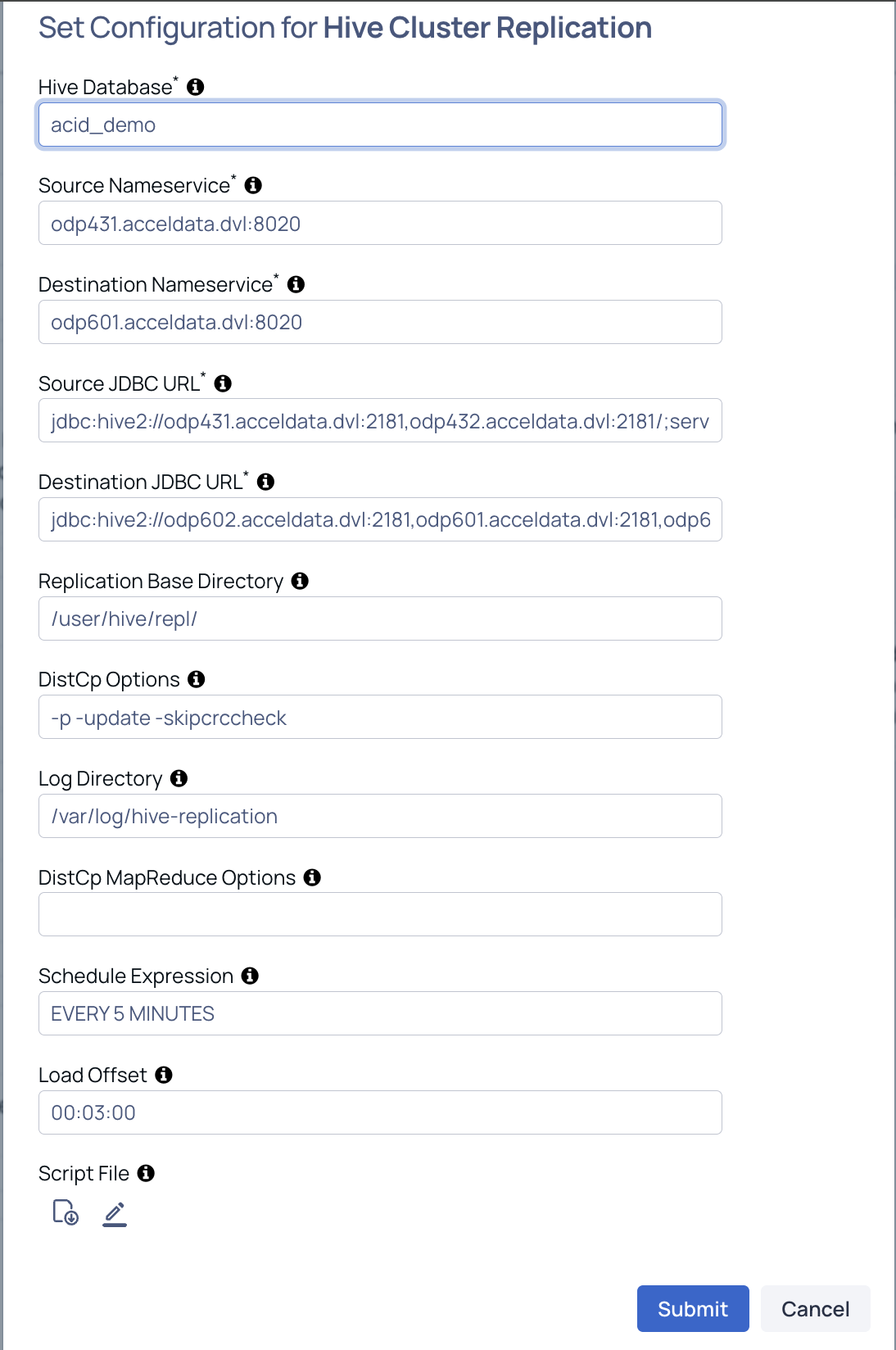
HBase table name: Specify the HBase table name or a wildcard pattern.
- Single table:
namespace:table - Wildcard:
namespace:table*or*:table - Example:
prod:customer_*
- Single table:
Snapshot name prefix: Specify a prefix for snapshot names.
- Example:
bdr_snap
- Example:
Snapshot retention count: Specify the number of snapshots to retain. Older snapshots are deleted when the limit is reached.
Destination NameNode URI: Specify the HDFS URI of the destination cluster.
- Example:
hdfs://odpkronos101.acceldata.dvl:8020
- Example:
Destination host: Specify the hostname or IP address of the destination cluster node used for SSH restore operations.
- Example:
odpkronos101.acceldata.dvl
- Example:
Destination SSH user: Specify the SSH username for the destination host.
- Example:
hdfs-odp_kronos
- Example:
Security Settings
Is the cluster kerberized?: Enable this option if the cluster uses Kerberos authentication. When enabled, you must provide the principal and keytab details.
Kerberos principal: Specify the Kerberos principal used for authentication.
- Example:
hdfs-odp_itachi@ADSRE.COM
- Example:
Keytab file path: Specify the full path to the keytab file on the source cluster.
- Example:
/home/acceldata/odp_itachi.keytab
- Example:
Destination keytab path: Specify the full path to the keytab file on the destination host.
- Example:
/home/acceldata/odp_kronos.keytab
- Example:
Run as user: Specify the user to run commands as for non-Kerberos clusters.
- Example:
hbase
- Example:
Advanced Options
- ExportSnapshot mappers: Specify the number of mappers to use for the ExportSnapshot operation.
- SSH options: Specify additional SSH options for remote operations.
- ExportSnapshot options: Specify additional options for the ExportSnapshot command. Supported options include:
--overwrite,--bandwidth <MB/s>,--chuser <user>,--chgroup <group>,--chmod <mode>,--no-checksum-verify,--no-target-verify - Log directory: Specify the directory for replication log files.
- Extra arguments passed in script: Provide additional arguments as a comma-separated list.
Hive Cluster Recovery — Execution Guidelines
- Host Selection
Ensure that only one host is selected when executing the script.
If multiple hosts are selected, the Hive Cluster Recovery script may:
- Run simultaneously on multiple hosts
- Ingest duplicate data into the destination cluster
- Fail due to concurrent execution conflicts
- Timeout Settings
Benchmark Results
The following results were observed using:
- Hive configuration with 8 DistCp mappers
- No competing jobs
| Data Size (in GB) | Observed Time (In Seconds) |
|---|---|
| 5 | 200 |
| 35 | 1140 |
| 40 | 1500 |
| 60 | 2930 |
Test environment:
- 2-node ODP cluster
- Each node:
- 8 CPU cores
- 32 GB RAM
- 200 GB disk
Recommended Action Timeout
Set the action timeout to:
250 seconds per GB of replication data
This provides approximately a 5× buffer over the observed rate (~50 s/GB), accounting for:
- YARN resource contention
- Network bandwidth limitations
- Production workload variability
- Limitation
If replication exceeds the configured action timeout:
- The Action Server reports a timeout failure
- However, the replication process continues running in the background
If Timeout Occurs
- SSH into the VM where the plugin is running
- Check the replication log:
xxxxxxxxxx/var/log/hive-replication/hive_bdr_<DB>_<TIMESTAMP>.logIf replication exceeds 250 s/GB:
- Investigate cluster resource utilization
- Check network performance
- Validate YARN queue availability before re-running
Execution Behavior
The plugin is designed to run only once per database.
What Happens During Execution
Initial Bootstrap Replication
- Performs a full data copy (REPL DUMP + REPL LOAD)
Scheduled Queries Creation
- Automatically created on both:
- Source cluster
- Destination cluster
- Automatically created on both:
Incremental Replication
Scheduled queries:
- Periodically dump changes from the source
- Load them into the destination
No manual intervention required
Important Notes
After the initial run:
- The plugin does not need to be executed again for the same database
Incremental replication is handled automatically via scheduled queries
Advanced Usage (Optional)
If needed, users can:
Modify the script to:
- Customize dump/load behavior
- Handle additional replication scenarios
Schedule these custom workflows using Actions
HBASE Cluster Replication
HBase Replication — Prerequisites
- SSH Access to Destination Cluster
The following connectivity must be ensured:
- The configured action plugin parameters:
DEST_SSH_USERDEST_HOST
must allow:
- SSH login from the source cluster (where the action runs) to the destination host
- From the destination host:
- Ability to run
scp(to copy the restore script) - Ability to run
ssh(to execute the script)
- Ability to run
Recommendation
- Use passwordless SSH (key-based authentication) for seamless execution
- Security Configuration
Kerberos-enabled Clusters
For Kerberos environments, the following are required for both source and destination clusters:
- Valid Kerberos principal
- Corresponding keytab file
These are required for:
- Authentication
- Snapshot operations
- Restore and replication workflows
Non-Kerberos Clusters
For non-Kerberos environments:
- The configured user must have appropriate HBase permissions, including:
- Snapshot creation
- Restore operations
- Clone operations
Configuration
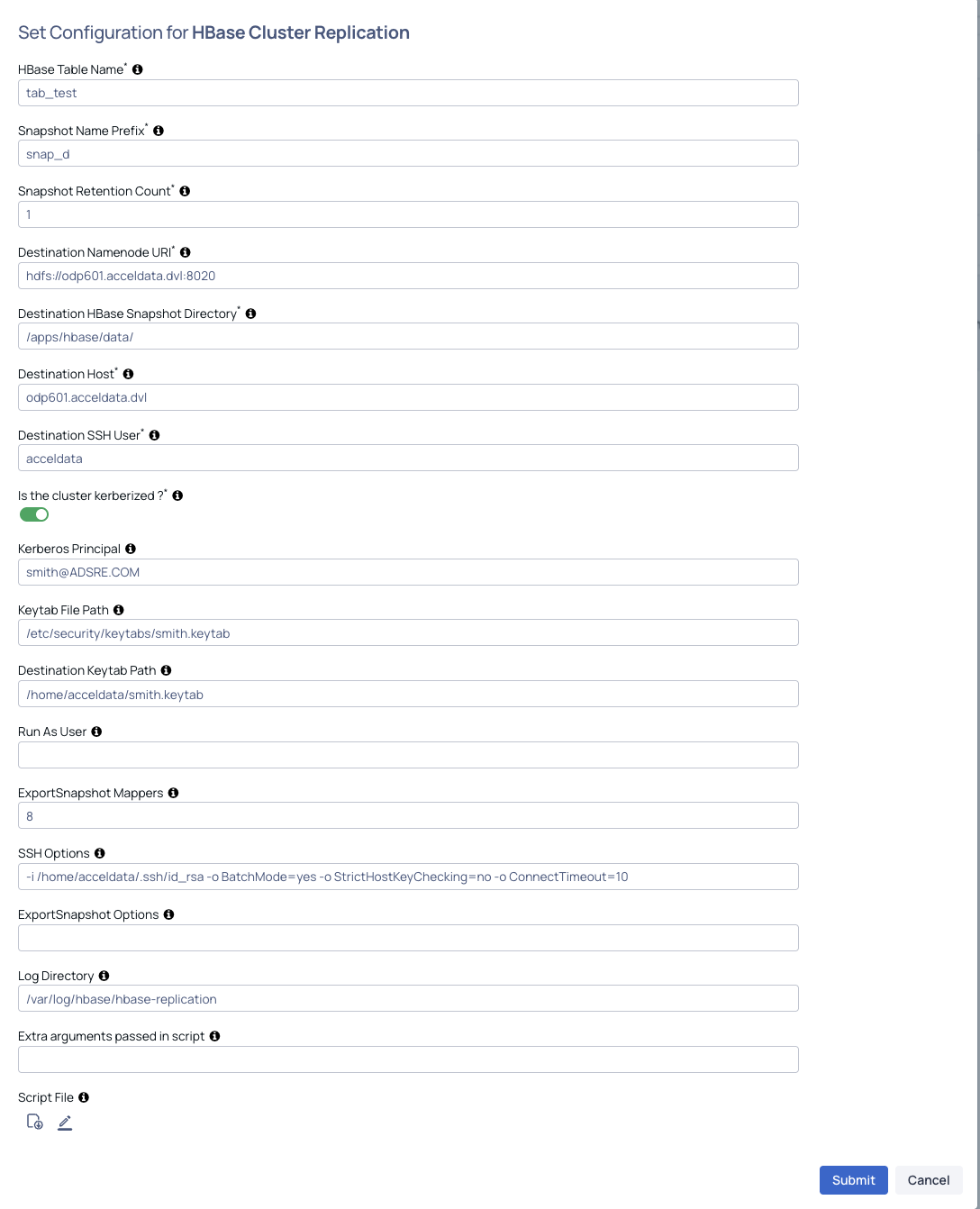
- HBase Table Name: HBase table name or wildcard pattern. Single table:
table(default namespace) ornamespace:table. Wildcard:namespace:table*,*:table, ornamespace:*. Example:prod:customer_*matches all tables inprodnamespace starting withcustomer_. - Snapshot Name Prefix: Prefix for HBase snapshot names, e.g.,
bdr_snap. For wildcard patterns, the table name is automatically appended to create unique prefixes per table (e.g.,bdr_snap_prod_customers). - Snapshot Retention Count: Number of snapshots to keep in rotation (default: 1). When this limit is reached, the oldest snapshot is deleted before creating a new one.
- Destination Namenode URI: Destination cluster HDFS URI, e.g.,
hdfs://hostname:8020. - Destination HBase Snapshot Directory: HDFS directory on destination where HBase snapshots reside, e.g.,
/apps/hbase/data/. - Destination Host: Hostname or IP of a destination cluster node for SSH-based restore operations.
- Destination SSH User: SSH username for the destination host.
- Kerberos Enabled:
yesorno. Whenyes, Principal, Keytab, and Destination Keytab are required. - Principal: Kerberos principal for source cluster authentication (required if Kerberos enabled).
- Keytab File Path: Path to the keytab file on the source cluster (required if Kerberos enabled).
- Destination Keytab Path: Path to the keytab file on the destination host (required if Kerberos enabled).
- Run As User: User to run commands as for non-Kerberos clusters (e.g.,
hdfs). Commands usesu - <user> -c "command". - ExportSnapshot Mappers: Number of mappers for the ExportSnapshot operation (default: 8).
- SSH Options: Additional SSH options (default:
-o BatchMode=yes -o StrictHostKeyChecking=no -o ConnectTimeout=10). - ExportSnapshot Options: Additional options for the ExportSnapshot command (e.g.,
--overwrite --bandwidth 100 --chuser MyUser --chgroup MyGroup --chmod 700 - Log Directory: Directory for replication log files (default:
/var/log/hbase-replication). - Script File: When no script is provided, the default script is automatically applied.
HBase Disaster Recovery — Execution Guidelines
- Host Selection

Ensure that only one host is selected when executing the script.
If multiple hosts are selected, the Disaster Recovery script may:
- Run simultaneously on multiple hosts
- Ingest duplicate data into the destination cluster
- Fail due to concurrent execution conflicts
- Timeout Settings

Benchmark Results
The following results were observed under test conditions:
| Data Size (GB) | Observed Time (In Seconds) |
|---|---|
| 10 | 2430 |
| 20 | 5100 |
| 40 | 9240 |
Test environment:
- 2-node ODP cluster
- Each node:
- 8 CPU cores
- 32 GB RAM
- 200 GB disk
Minimum configured timeout value: 1000 seconds
Recommended Action Timeout
Set the action timeout to:
1000 seconds per GB of replication data
This recommendation provides a buffer over the observed rate (~250 s/GB), accounting for:
- YARN resource availability delays
- Network bandwidth limitations
- Production workload contention
- Limitation
If replication exceeds the configured action timeout:
- The Action Server reports a timeout failure
- However, the replication process continues running in the background on the VM
If Timeout Occurs
- SSH into the VM where the plugin is running
- Check the replication log:
xxxxxxxxxx/var/log/hbase-replication- If replication exceeds 1000 s/GB:
- Investigate cluster resource utilization
- Check network performance
- Validate YARN queue availability before re-running
HDFS Balancer
Creates an action script to run HDFS datanode balancer with network bandwidth option. User requires path privileges and permissions.
Enter the following parameters and click Next:
- (Optional) Network Bandwidth: Enter the network bandwidth consumed by each DataNode, default bandwidth is 500MB/s.
- (Optional) Threshold: Enter the threshold(%) limit for balancer to move data, default threshold is 5.
- (Optional) Moved Window Width: Time window for moved blocks to avoid redundant moves. Default value = (from hdfs-site.xml OR 5400000 ms).
- (Optional) Mover Threads: Enter the number of threads to move blocks during balancing. Default value = (from hdfs-site.xml OR 1000).
- (Optional) Dispatcher Threads: Enter the size of the thread pool for the HDFS balancer block mover. Default value = (from hdfs-site.xml OR 200).__
- (Optional) Maximum Concurrent Moves: Enter the maximum number of concurrent block moves allowed for the balancer. Default value = (from hdfs-site.xml OR 100).
- (Optional) Get Blocks Size: Size of blocks fetched from data nodes during balancing. Default value = (from hdfs-site.xml OR 2147483648 bytes (2GB)).
- (Optional) Get Blocks Min Block Size: Enter the minimum size of blocks to be considered during balancing. Default value = (from hdfs-site.xml OR 10485760 bytes (10MB)).
- (Optional) Maximum Size to Move: Enter the maximum size of a single block to move during balancing. Default value = (from hdfs-site.xml OR 10737418240 bytes (10GB)).
- (Optional) Block Size: The HDFS block size. Default value = (from hdfs-site.xml OR 134217728 bytes (128MB)).
- __(Optional) Maximum Idle Iterations: Enter the maximum number of idle iterations before exit. Default value = (from hdfs-site.xml OR 5).
- (Optional) Maximum Queries Per Second: Enter the maximum number of getBlocks RPCs, data movement utilities can make to a NameNode per second. Default value = (from hdfs-site.xml OR 20).
For the following actions, a separate Kerberos tile is not required:
- HDFS Balancer
- HBase Compact Tables
- HBase Hbck
These tiles already include Kerberos fields, which the user can fill in when the cluster is Kerberized.
For all other actions where the is_kerberized option is present, a separate Kerberos tile should be shown.
Hbase Compact Tables
Creates an action script to compact Hbase region/table/column family.
Enter the following parameters and click Next:
- Hbase Object: Enter the HBase object to be compacted.
- Compaction Type: Enter the HBase compaction type 'major' / 'minor'.
Hbase Hbck Action
Creates an Action script to run Hbck command to detect and fix the region inconsistencies.
Enter the Action Command. Enter the single operation in the field.