Fileset Catalogs
Overview
Fileset catalogs connect xStore to object stores and distributed file systems — AWS S3, Google Cloud Storage, Azure Data Lake, and Hadoop HDFS. Rather than browsing individual files, a fileset catalog organizes access through named Filesets: registered storage paths that your compute engines can read and write.
The hierarchy for fileset catalogs is: Metalake → Catalog → Schema → Filesets
When to Use
Use a fileset catalog when:
You need to register and organize access to files on S3, GCS, ADLS, or HDFS within the Catalog Browser.
You want to expose named storage paths (filesets) to compute engines without requiring manual path configuration on each cluster.
You are building a data lake and want to manage both relational catalogs (Hive, Iceberg) and file-based catalogs in one place.
Prerequisites
A running xStore cluster. See xStore Clusters
A metalake. See xStore Catalogs
Access credentials for the target storage system (S3 access keys, GCS service account, ADLS account key or service principal, or HDFS Kerberos keytab).
Creating a Fileset Catalog
Navigate to Data Catalog → Browse → Catalog in the sidebar.
Select your metalake in the Catalog Browser tree and click + New Catalog.
In the Create Catalog form, select Fileset as the Catalog Type.
The Provider dropdown shows all available file store providers:
Select the provider that matches your storage system:
** Hadoop (HDFS)— for Hadoop Distributed File System **
AWS S3 — for Amazon S3 or S3-compatible storage (MinIO)
Google Cloud Storage — for GCS buckets
Azure Data Lake — for Azure Data Lake Storage Gen2
Under Basic Information, set the Catalog Name (for example,
hdfs_landing) and an optional Description.Fill in the provider-specific connection fields. See the configuration reference for each provider below.
Click Create Catalog.
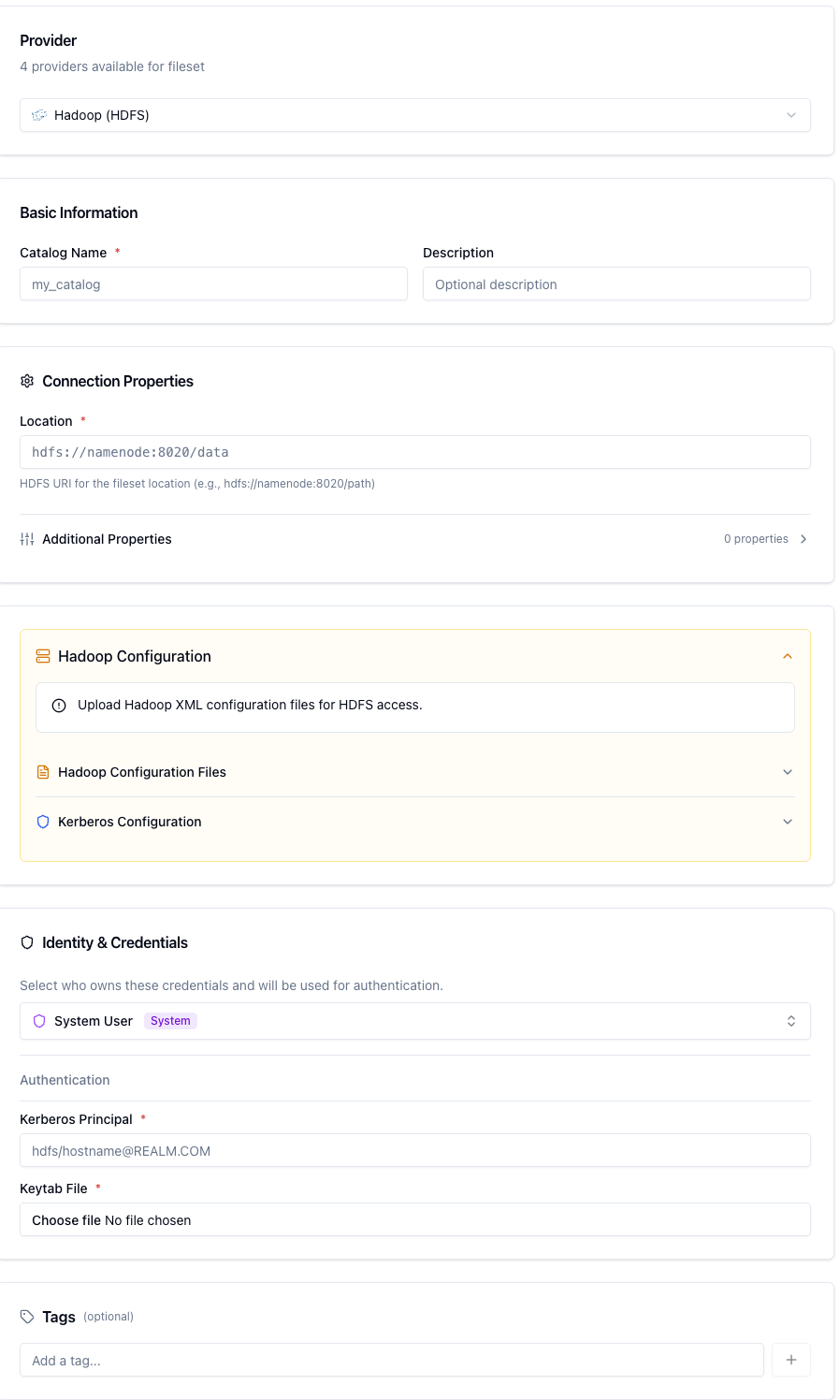
Hadoop (HDFS)
The HDFS provider connects to a Hadoop Distributed File System. Use this when your data files live on HDFS and you need to organize them as named filesets.
HDFS Fields
Field | Required | Description |
|---|---|---|
Location | Yes | HDFS root path for this catalog (e.g. |
HDFS — Additional Properties
File | Description |
|---|---|
Core Site XML | Upload your |
HDFS Site XML | Upload your |
Kerberos Config | Upload your |
HDFS — Authentication
Select the authentication type:
Simple — No authentication. Use for non-Kerberos HDFS clusters.
Kerberos — For secured HDFS clusters. Selecting Kerberos reveals additional fields:
Field | Required | Description |
|---|---|---|
Kerberos Principal | Yes | The principal xStore authenticates as (e.g. |
Kerberos Keytab | Yes | Upload the |
The screenshot below shows a completed HDFS fileset catalog form with the location, configuration files, and Kerberos authentication configured:
AWS S3
The S3 provider connects to Amazon S3 or any S3-compatible storage system (such as MinIO).
S3 Fields
Field | Required | Description |
|---|---|---|
Location | Yes | Root S3 path for this catalog (e.g. |
S3 Endpoint | No | Custom endpoint for MinIO or non-AWS S3 (e.g. |
S3 Region | No | AWS region (e.g. |
S3 — Authentication
Access Key — Provide an S3 Access Key ID and S3 Secret Access Key for programmatic access.
IAM Role — Use the IAM role attached to the xStore cluster's node. No credential fields are required. This option is only available when xStore is running on AWS.
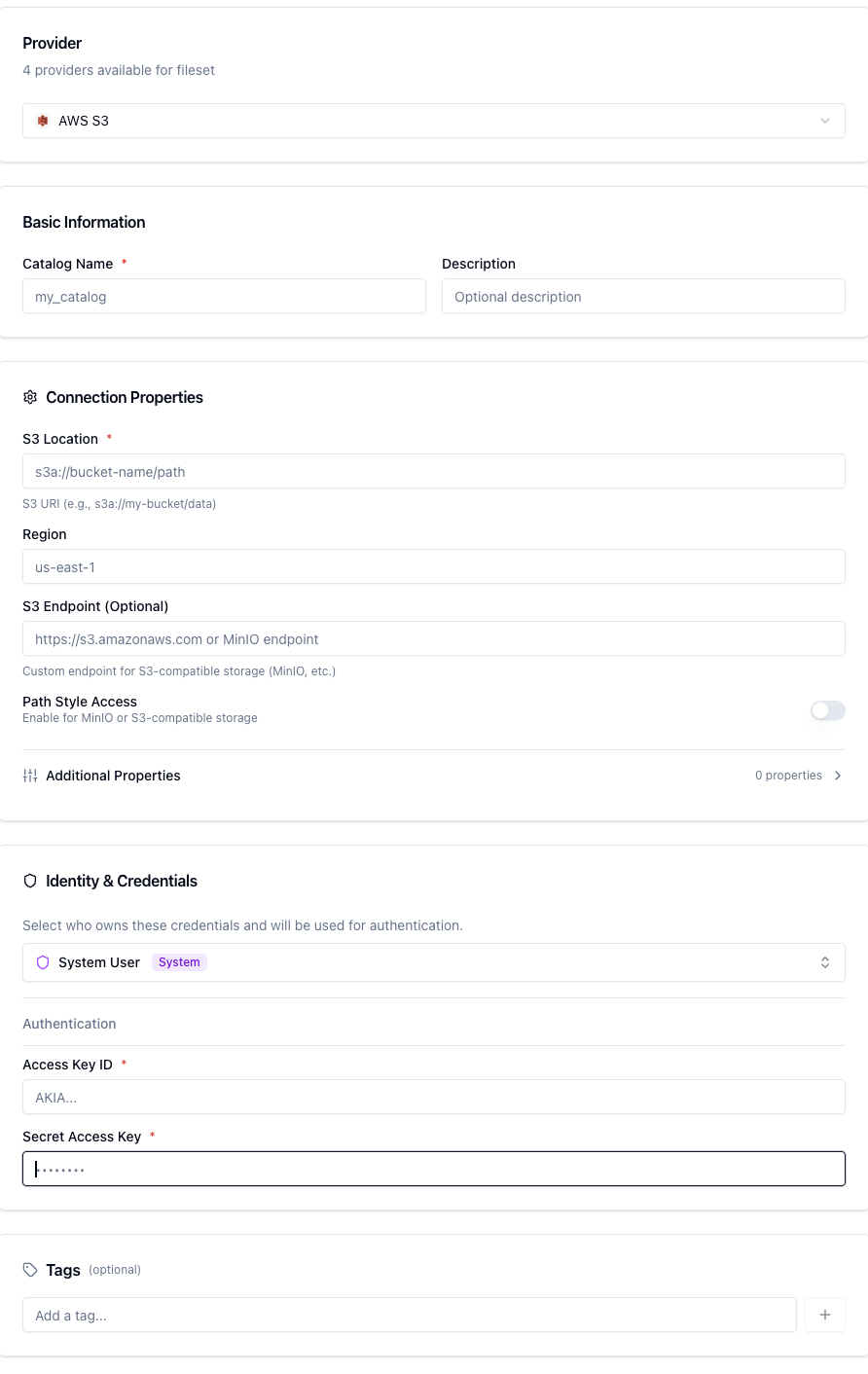
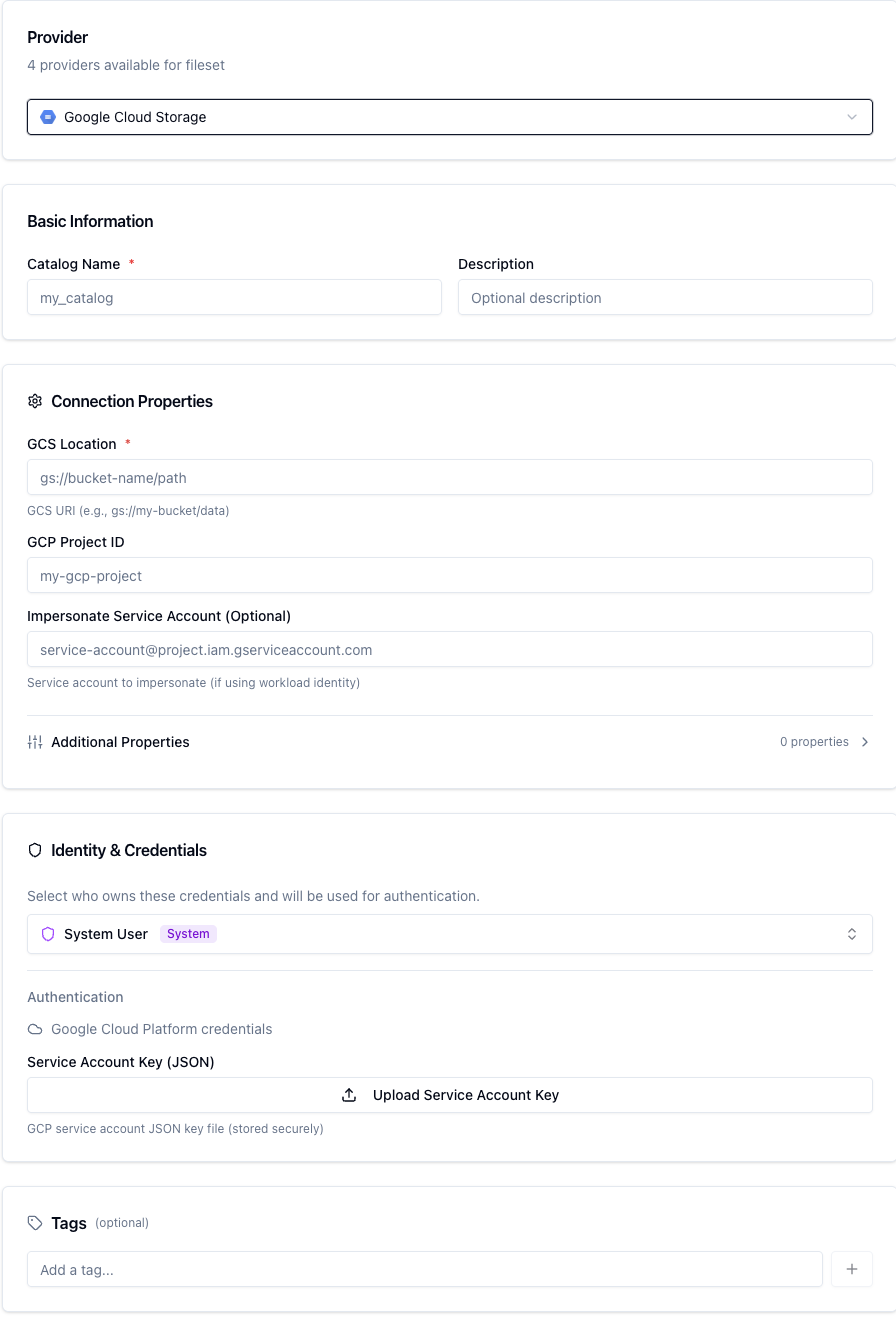
Google Cloud Storage
The GCS provider connects to Google Cloud Storage buckets.
GCS Fields
Field | Required | Description |
|---|---|---|
Location | Yes | Root GCS path (e.g. |
GCS — Authentication
Service Account — Upload a GCS Service Account JSON key file. The service account must have Storage Object Viewer (read) or Storage Object Admin (read/write) permissions on the bucket.
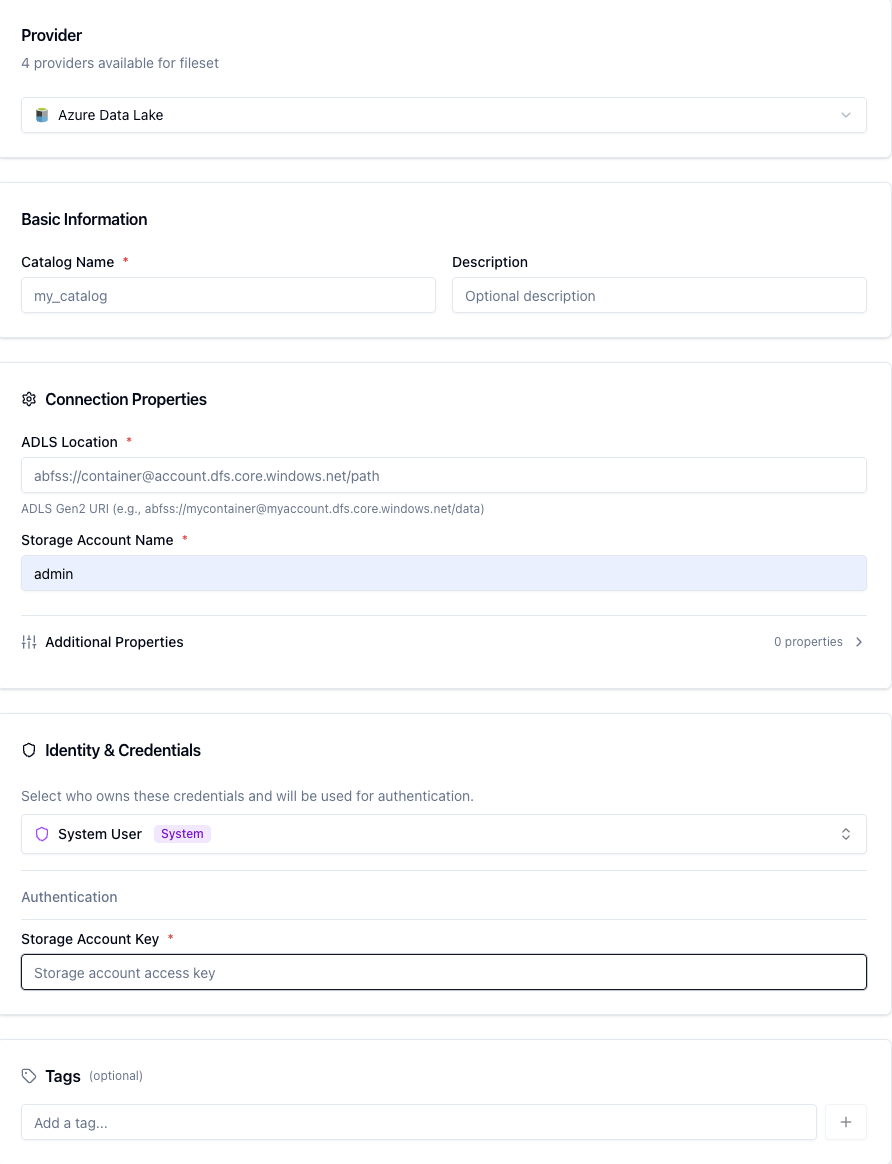
Azure Data Lake
The ADLS provider connects to Azure Data Lake Storage Gen2.
ADLS Fields
Field | Required | Description |
|---|---|---|
Location | Yes | ADLS Gen2 path (e.g. |
Storage Account Name | Yes | Your Azure Storage account name (without |
ADLS — Authentication
Account Key — Provide the Azure Account Key (storage account key from the Azure portal).
Service Principal — Provide Azure Tenant ID, Azure Client ID, and Azure Client Secret for an Entra ID (Azure AD) service principal with Storage Blob Data Contributor access.
Browsing Filesets
After creating a fileset catalog:
Expand the catalog in the Catalog Browser tree and click a schema.
The Filesets tab lists all registered filesets within that schema.
Each fileset row shows:
Fileset Name
Type — Managed (xStore controls the path lifecycle) or External (points to existing files)
Storage Location — the full storage path this fileset points to
Creating a Fileset
With a schema selected, click New Fileset.
Fill in the form:
Fileset Name (required) — a short, lowercase name.
Fileset Type (required):
Managed — xStore manages the storage path; the location is derived from the schema's root path. Use this for new data you are creating.
External — points to an existing path in the storage system. Use this to register data that already exists.
Storage Location — required for External filesets; optional for Managed. Provide a full path (e.g.
s3a://my-bucket/data/events).
Description (optional)
Click Create.
Common Issues
Catalog creation fails with connection error
For HDFS: verify the namenode address and port in the Location field. Ensure the xStore cluster can reach HDFS on the network.
For S3: verify the endpoint URL and that the bucket exists.
For GCS/ADLS: verify the storage path format and that the account/container exists.
No filesets or schemas appear
Filesets must be explicitly created within a schema — unlike relational catalogs, fileset catalogs do not auto-discover content.
Create a schema first, then create filesets within it.
Permission denied when accessing filesets
For S3, ensure the access key or IAM role has
s3:GetObjectands3:ListBucketon the bucket.For GCS, ensure the service account has Storage Object Viewer or higher.
For ADLS, ensure the service principal has Storage Blob Data Reader or higher.
For HDFS with Kerberos, verify the keytab matches the principal and the KDC is reachable.