Search
Architecture Comparison
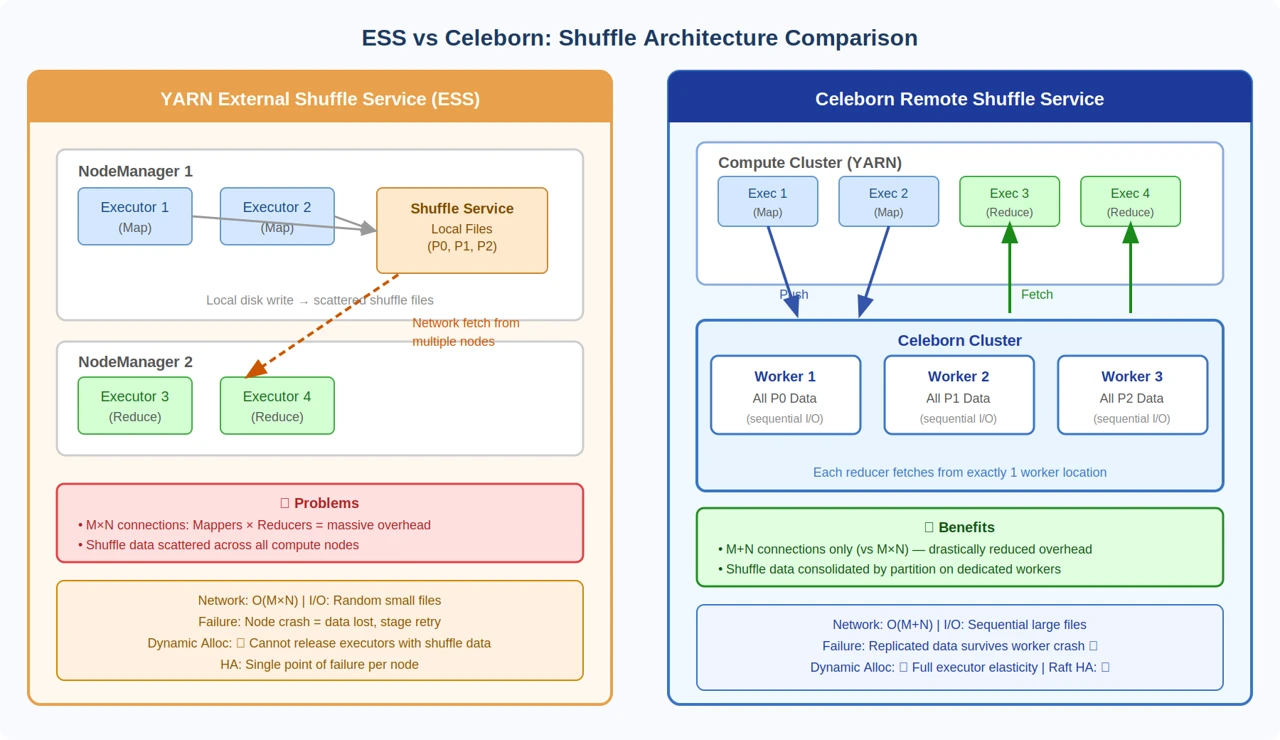
The diagram below illustrates the fundamental architectural difference between YARN ESS and Celeborn. ESS scatters shuffle data across all compute nodes and creates M×N network connections. Celeborn consolidates all data for a given partition onto a single worker, reducing connections to M+N.
Feature Comparison
| Feature | YARN ESS | Celeborn |
|---|---|---|
| Architecture | Co-located with compute nodes | Dedicated shuffle cluster |
| Data Location | Local disks on compute nodes | Remote shuffle workers |
| Network Pattern | M×N (mappers × reducers) | M+N (mappers + reducers) |
| I/O Pattern | Random I/O (many small files) | Sequential I/O (consolidated files) |
| Replication | None | Configurable (1 or 2 copies) |
| Node Failure | Shuffle data lost, stage retries | Data survives, job continues |
| Dynamic Allocation | Limited by shuffle locality | Full executor elasticity |
| Storage Disaggregation | Not supported | Yes — HDFS, S3 supported |
| Multi-Tenant Isolation | No isolation | Quota & worker tags supported |
| High Availability | Single point of failure | Raft-based Master HA (3+ nodes) |
Performance Comparison
| Metric | YARN ESS | Celeborn | Improvement |
|---|---|---|---|
| Shuffle Time | Baseline | 30–50% faster | Network efficiency |
| Job Stability | Node failure = stage retry | Node failure = continue | Data replication |
| Disk I/O | Random small files | Sequential large files | 2–5× throughput |
| Network Connections | O(M×N) | O(M+N) | Drastically reduced |
| Memory Pressure | On compute nodes | On dedicated shuffle nodes | Resource isolation |
When to Use Celeborn vs ESS
| Scenario | Recommendation |
|---|---|
| Small jobs (< 100 GB shuffle) | ESS may be sufficient |
| Large jobs (> 100 GB shuffle) | Celeborn recommended |
| Dynamic allocation required | Celeborn required |
| Cloud / Kubernetes deployment | Celeborn recommended |
| Spot / preemptible instances | Celeborn required |
| Multi-tenant cluster | Celeborn recommended |
| Frequent node failures | Celeborn recommended |
| Disaggregated storage needed | Celeborn required |
| Single-user development | ESS may be sufficient |
Migration Path
Phase 1 — Pilot
- Deploy Celeborn alongside existing ESS
- Test with non-critical workloads
- Compare performance metrics in parallel
Phase 2 — Gradual Rollout
- Enable Celeborn for specific teams or jobs via worker tags
- Monitor stability and performance
Phase 3 — Full Migration
- Make Celeborn the default shuffle service cluster-wide
- Disable ESS on compute nodes
- Optimize Celeborn cluster sizing based on observed usage
Was this page helpful?