This page demonstrates how to use Jupyter notebooks with Spark, including Python 3 kernel options and related development tools.
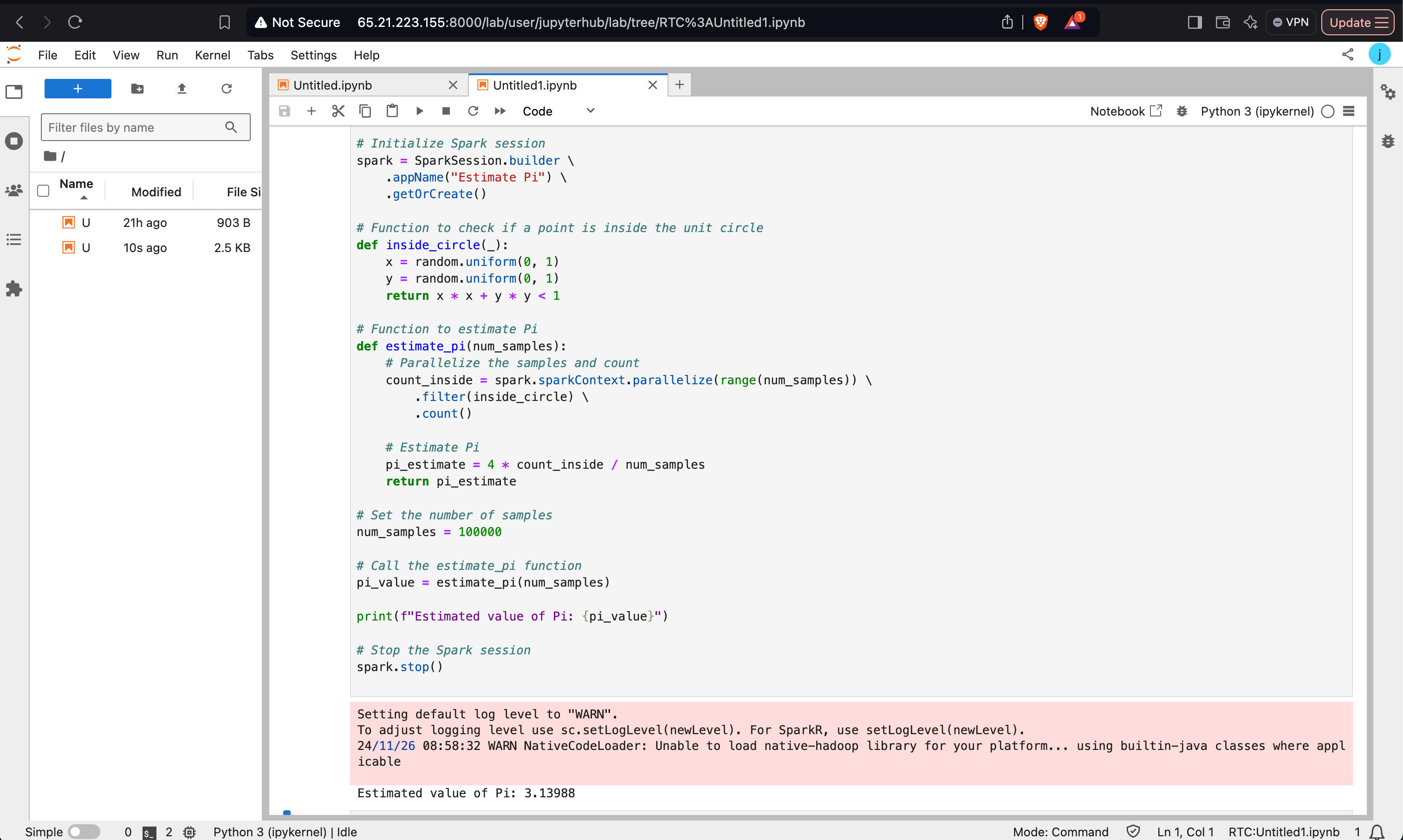
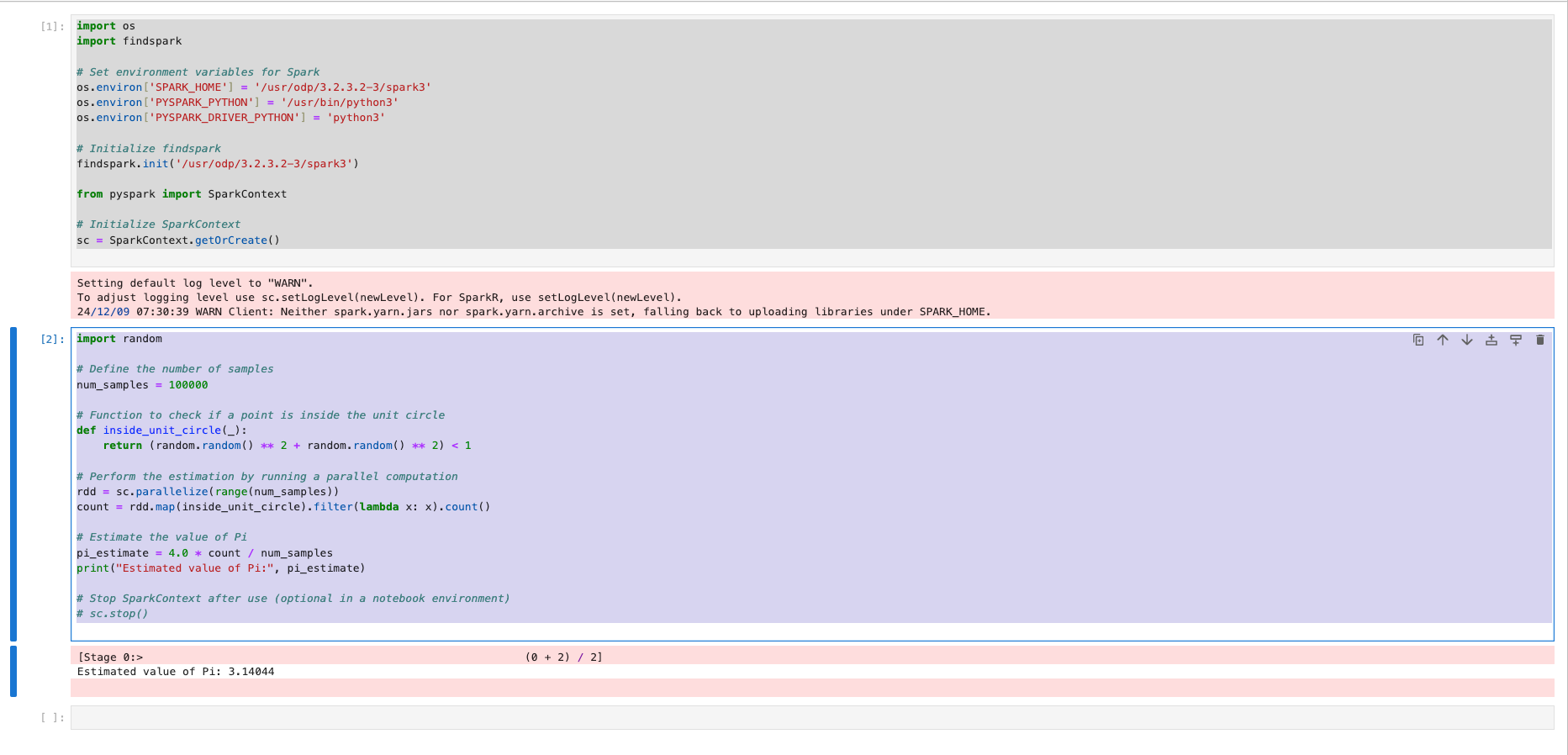
Estimating Pi Using PySpark
This program uses the Monte Carlo method to estimate the value of Pi. It demonstrates how to use PySpark to parallelize computations.
Creating and Displaying a DataFrame
This example showcases creating a Spark DataFrame using a list of Row objects and displaying it.

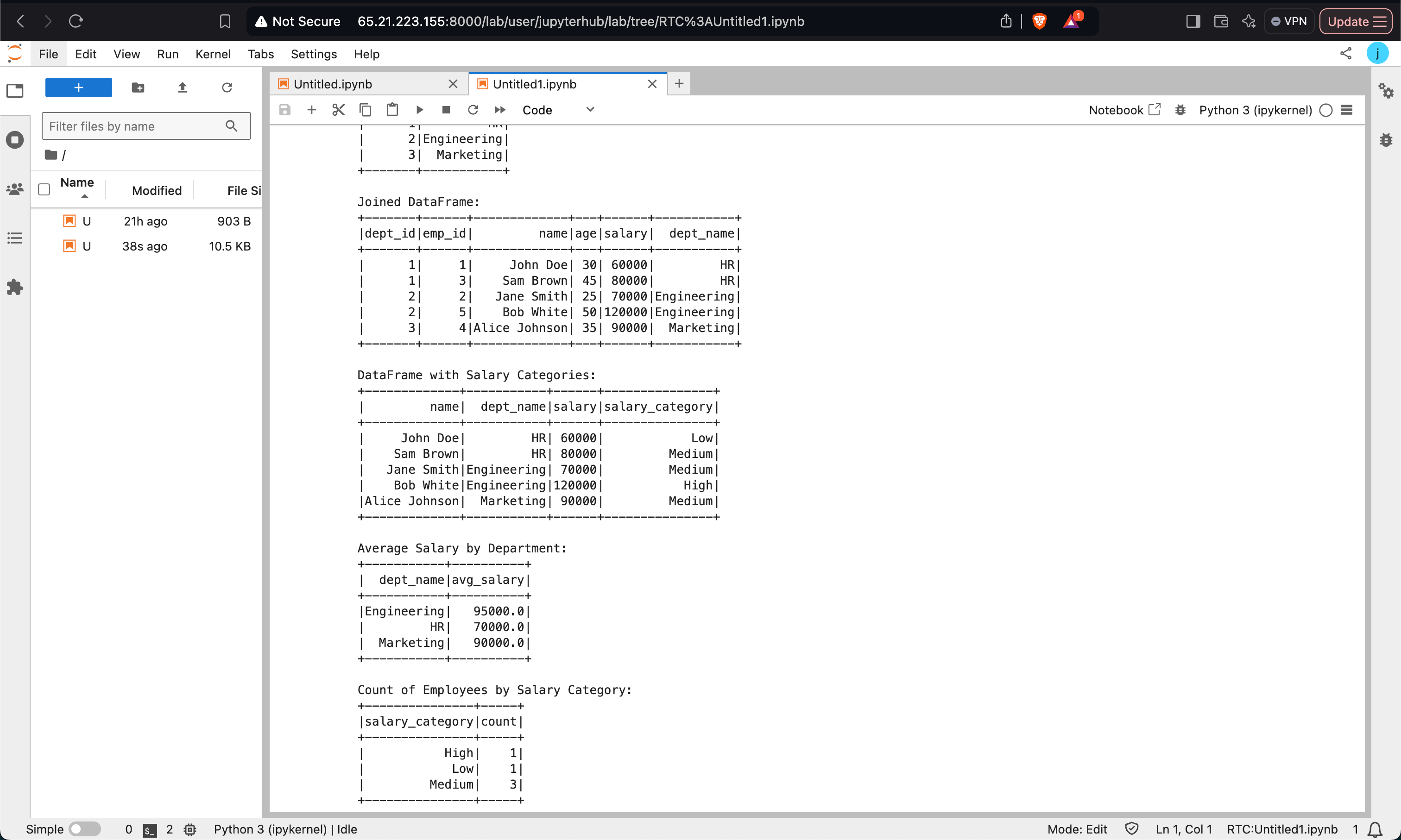
Complex Operations with PySpark
This example demonstrates joining DataFrames, applying User-Defined Functions (UDFs), and executing SQL queries.
Data Preparation and Joining:
Using UDFs:
SQL Queries:
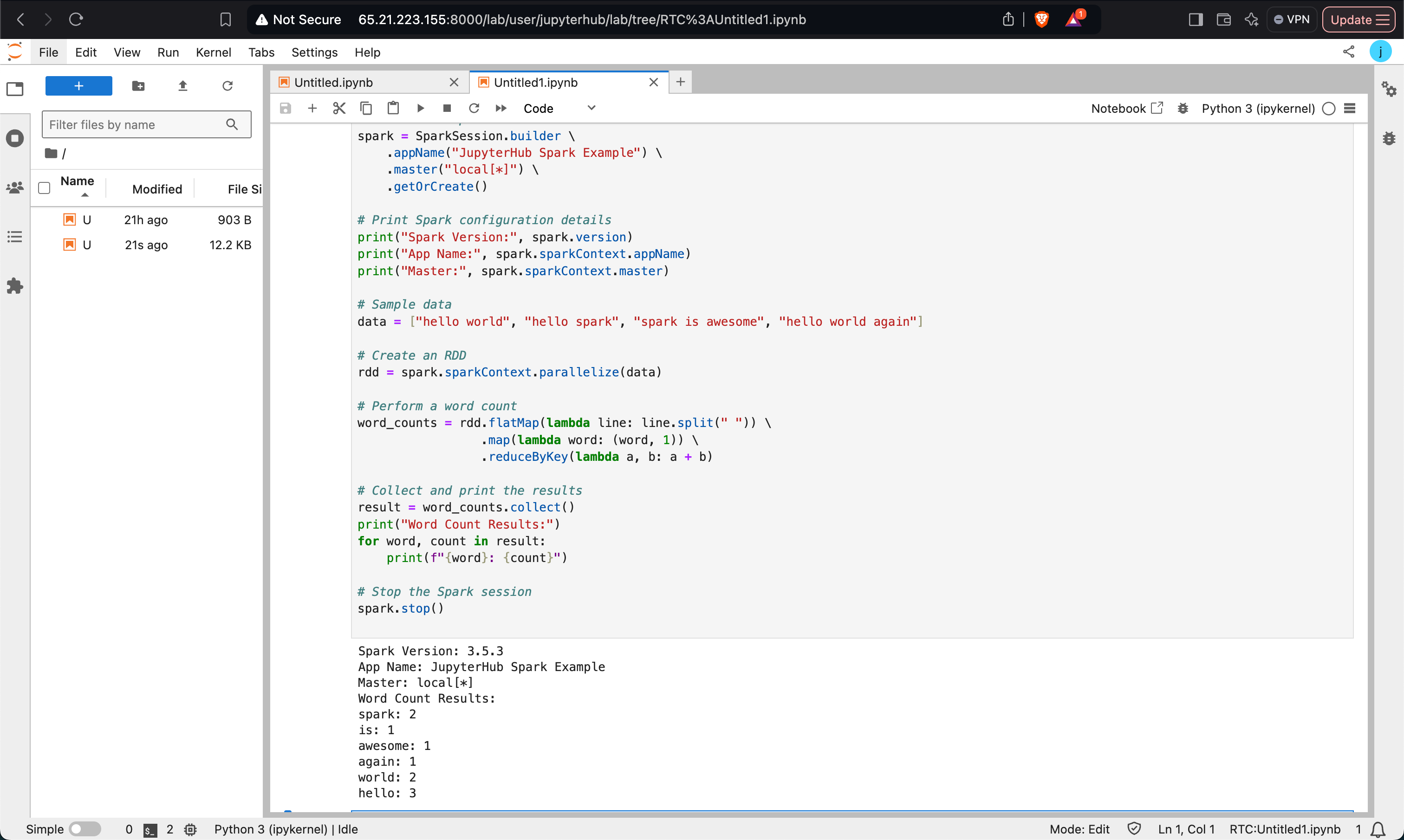
Performing Word Count
A simple word count example demonstrating Spark RDD transformations.
Using ODP’s Spark version
Submit the Job to a Cluster (Optional)
If you’re using a cluster manager like YARN with JupyterHub, you need to adjust the configurations accordingly:
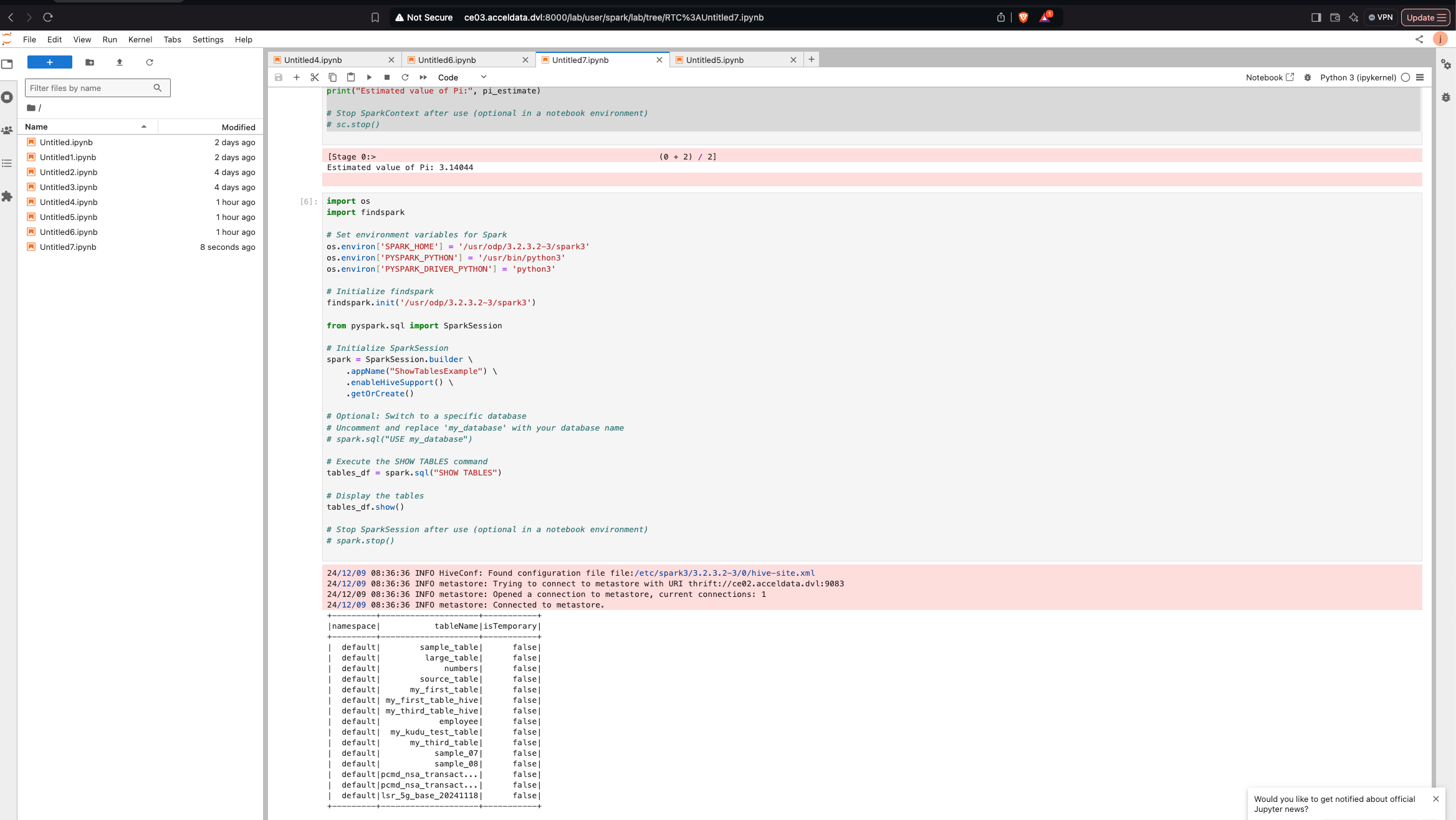
Show Hive Tables in Spark
How It Works:
Environment Setup: Configures the necessary Spark environment variables.
SparkSession: Initializes a
SparkSessionwith Hive support (if needed).Switch Database (Optional): You can switch to a specific database if you want to list tables from it.
Show Tables: Executes the SQL command
SHOW TABLES, which returns a DataFrame of tables.Display Output: Displays the list of tables in the output.
Expected Output:

Note
Dependencies: Ensure Spark is correctly set up and configured for
localoryarnmode depending on the example.UDFs: Register user-defined functions (UDFs) as required for custom transformations.
SQL Queries: Use
createOrReplaceTempViewto run SQL queries on DataFrames.Data Source: Replace hardcoded data with external sources like HDFS, databases, or files for real-world applications.
Resource Configurations: Tune
spark.executor.memoryandspark.driver.memorybased on the cluster size and workload requirements.