Data Sources
After you have configured your Data Source, ADOC will continually monitor it and give you information, such as how you are utilizing it and other relevant data.
It is possible to produce several instances of the same Data Source using the system's provisioning capabilities.

If you have more than one Snowflake or Azure account, for example, you can follow the instructions in the accompanying image to set up numerous instances of Snowflake or Azure Data Source, one for each of your individual accounts. After you have configured your Data Source, ADOC will continually monitor it and give you information, such as how you are utilizing it and other relevant data.
To add a Data Source, perform the following steps:
- Click the Add Data Source button in the Register icon tab.
- Follow the instructions provided by the wizard to finalize the setup process on the Select a Data Source page.

For detailed integration steps, explore the relevant sections in the Contents on the left.
The AVRO file format is now supported by ADOC. This feature significantly increases the data format compatibility, allowing users to use AVRO files for greater data observability and dependability.
AVRO Integration and Data Ingestion
Navigate to the Data Source Integration area of ADOC to ingest AVRO file type data. You may simply establish AVRO settings for multiple data storage options, such as ADLS, GCS, S3, and HDFS.
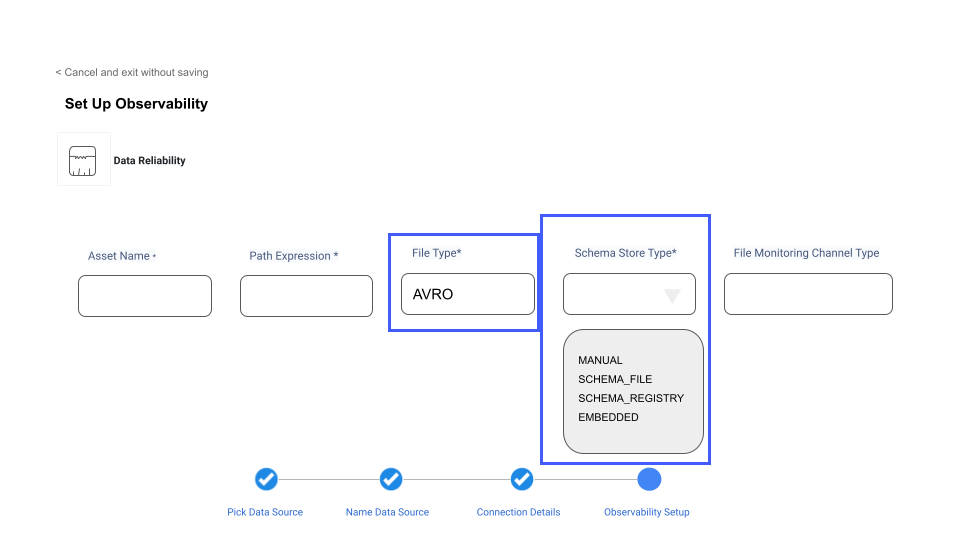
| Field | Description |
|---|---|
| Schema Registry | A registry owned by the user that stores several versions of the AVRO file structure. The exact version of the schema will be used to deserialize the binary AVRO data if available. |
| Schema File | An AVRO schema file is in .avsc format and provides a JSON schema representation. To utilize this, the user must input the path to the .avsc file that will be used for deserialization. |
| Manual Schema | When a user submits a JSON string describing the AVRO schema to be used for de-serialization, it is referred as the manual schema. When configuring the file asset, the user should just copy and paste the JSON string. |
| Embedded | The schema for the data in the AVRO file is included in the file as a JSON string in the header section. This option should be used when the user wants SPARK to infer the schema from the file header. |
Supported Data Sources and Integrations in ADOC
Click on an integration card from the list below to navigate to its respective integration page. These are the data sources (integrations) supported by ADOC.
.svg)
Azure Data Factory (ADF)

Hangouts


Jira

MAPR Connectors

Line

Microsoft Teams

OpenID

Opsgenie

PagerDuty

SFTP Connector

ServiceNow

Slack

PowerBI

Tableau

Alation

Atlan

Apache HDFS

Amazon S3

Azure Blob Storage
.svg)
Delta Parquet Files (3.7.1)

Google Cloud Storage

Amazon Aurora MySQL

Amazon RDS MySql

Amazon Aurora PostgreSQL

Amazon RDS MariaDB

Apache HBase

Amazon RDS PostgreSQL

Apache Impala

Azure CosmosDB PostgreSQL

Azure MSSQL

Cassandra

ClickHouse

IBM DB2

MariaDB

MongoDB

Microsoft SQL Server

MySQL

PostgreSQL

Oracle

SAP HANA

SingleStore
SingleStore (MemSQL)

Teradata

Apache Hive

Azure Data Lake

Databricks

Presto/Trino

AWS Kinesis

Kafka

Amazon MWAA

Airflow

Autosys

AWS Secret Manager

Azure Service Principal

Microsoft Azure Key Vault

Okta

Amazon Athena

Amazon Redshift

Azure Synapse

Azure SQL Warehouse

Google Big Query

Snowflake